Agent coding 的核心不是 prompt,而是反馈回路
cover
有一次我接到一个很急的需求。
那天我本来已经准备加班了。结果一边工作,一边娃也有事。我没法一直坐在电脑前面盯着代码写。
我当时也没有什么完整方法。就是把我能想到的背景、需求、限制、代码位置,全都丢给 AI。然后我去带娃。
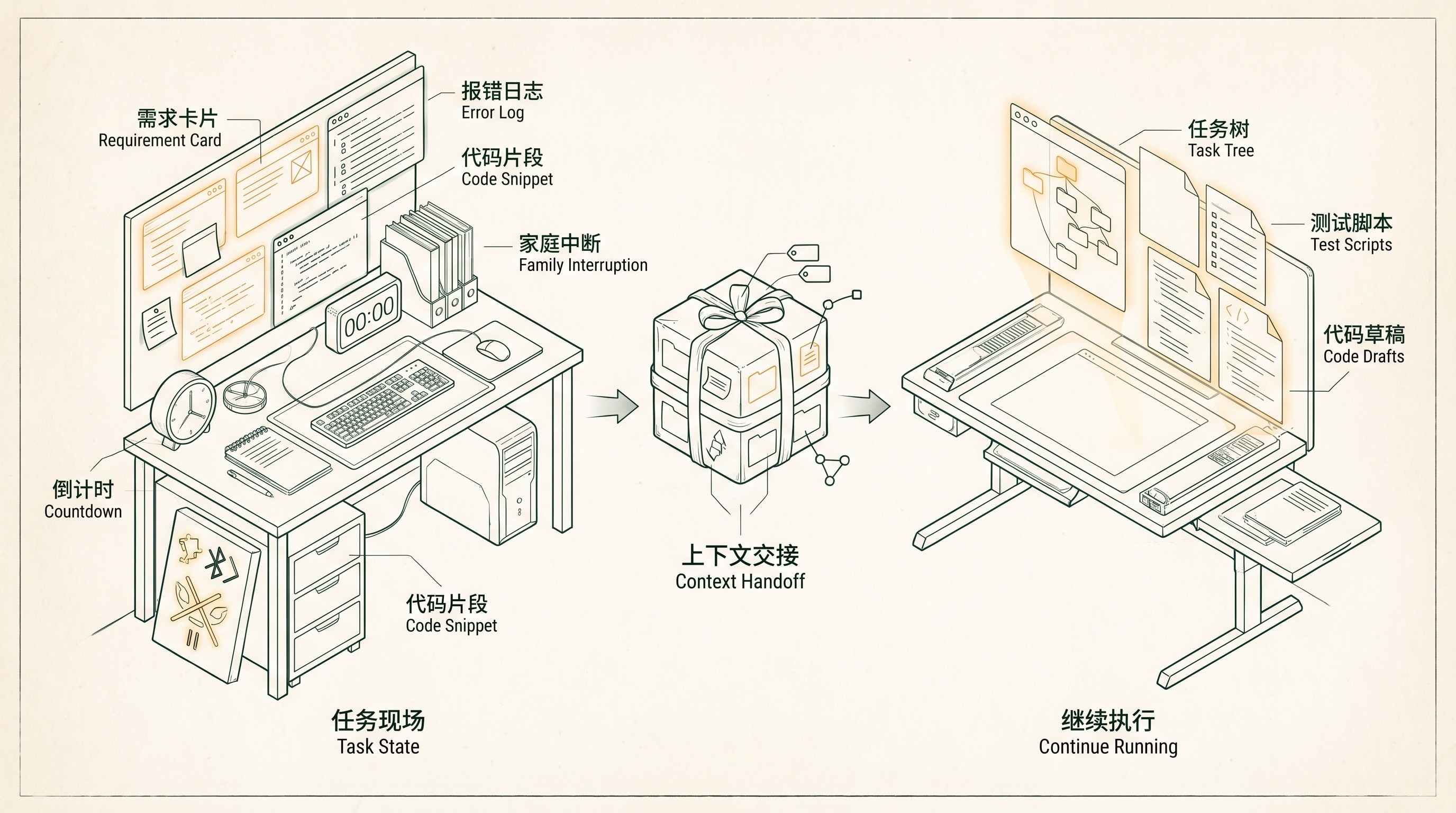
上下文交接:人离开键盘,系统继续保留任务现场
回来以后,我的第一反应是:这玩意儿居然能跑。
第二反应是:写得真糙,很多细节都没处理。
第三反应比较复杂。剩下的工作其实不多,但这些工作恰好是最重要的。很多细节、边界、异常状态,平时我自己写的时候也不一定一开始就想全,通常是做到后面才补。它这次反而提前想了一些。
这件事以后,我对 AI 写代码的看法变了。
不是因为它能写代码。能写代码这件事已经不新鲜了。真正让我在意的是:它把第一版做出来以后,我的工作变了。我不再从空文件开始写,而是先看一个能跑但不够好的东西,然后判断它哪里不对。
这比从零写代码更接近我现在的工作状态。
Prompt 不是最重要的
很多人聊 AI 编程,第一反应是 prompt。
怎么写 prompt?要不要先让它出方案?要不要让它列 task?要不要一步一步确认?
这些当然有用。但我现在不太把它们放在第一位。
大部分任务,我会直接让 agent 先做。如果它做得不对,我再补充要求,或者给它一个更明确的方案,让它重做。
原因很简单:很多时候,提前把所有事情说清楚,比让它先做一版成本还高。
这也是我现在对 agent coding 的一个判断:在 AI 时代,很多任务的对齐成本会比纠错成本高。以前我们习惯先把需求、方案、边界都对齐好,是因为人写代码的返工很贵。但现在 agent 先做一版的成本很低,看到实物以后再判断哪里不对,反而更省力。
假设我有 10 个问题。如果我每个问题都先写完整方案,时间会花很多。但如果我直接让 agent 做,它很快会给我 10 个结果。可能其中 6 个能用,3 个要改,1 个完全不行。那我只需要把精力花在后面 4 个上。
这个体感差很多。
以前手工写代码,任务没想清楚就开始写,返工成本很高。现在很多执行成本被 AI 吃掉了。真正贵的是三件事:
- 我有没有看出哪里不对。
- 我能不能判断这个问题值不值得改。
- 我能不能把问题讲清楚,让它下一轮改对。
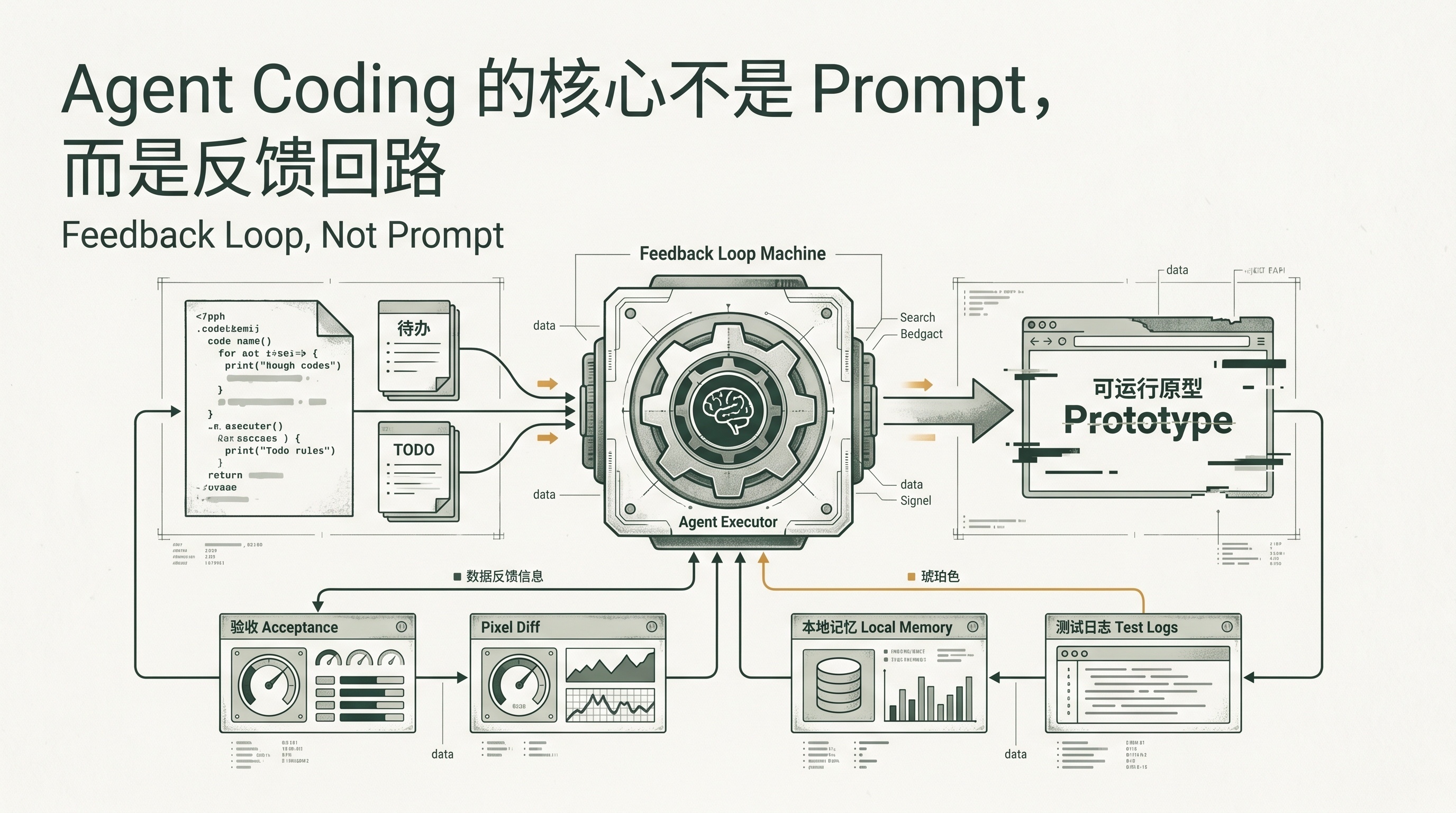
所以我现在更关心反馈回路,而不是 prompt。
prompt 只是输入。它不能保证事情真的做对。
真正有用的是后面这一串:任务丢出去,agent 做一版,我验收,发现问题,让它改,必要时补工具、补记忆、补测试。下一次再遇到类似问题,它应该更容易做对。这才是重点。
我一定会自己验收
我不会因为 AI 说完成了,就相信它完成了。
尤其是 UI 和真实行为,必须自己跑一遍。
UI 我会看 pixel diff。这个东西很直接,哪里变了,一眼就能看到。很多时候你光读代码看不出来 UI 被它搞坏了,但截图一对比就很明显。
常规行为我反而不太担心。比如输入框最大长度、错误 Toast、异常处理、复用项目已有的交互方式,这些它通常能做好。项目里有现成例子,它会照着学。我说太多反而浪费上下文。
真正要看的,是运行起来以后是不是对的。我一般会看这几类东西:
- 请求数量对不对,参数有没有多发、漏发。
- 过滤有没有真的生效,不只是 UI 看起来变了。
- 异常状态有没有处理,失败以后用户还能不能继续走。
- PC 切到 mobile 以后,布局和交互有没有崩。
- 页面上那些边界路径,是不是真的能跑通。
这些东西只看代码不够。
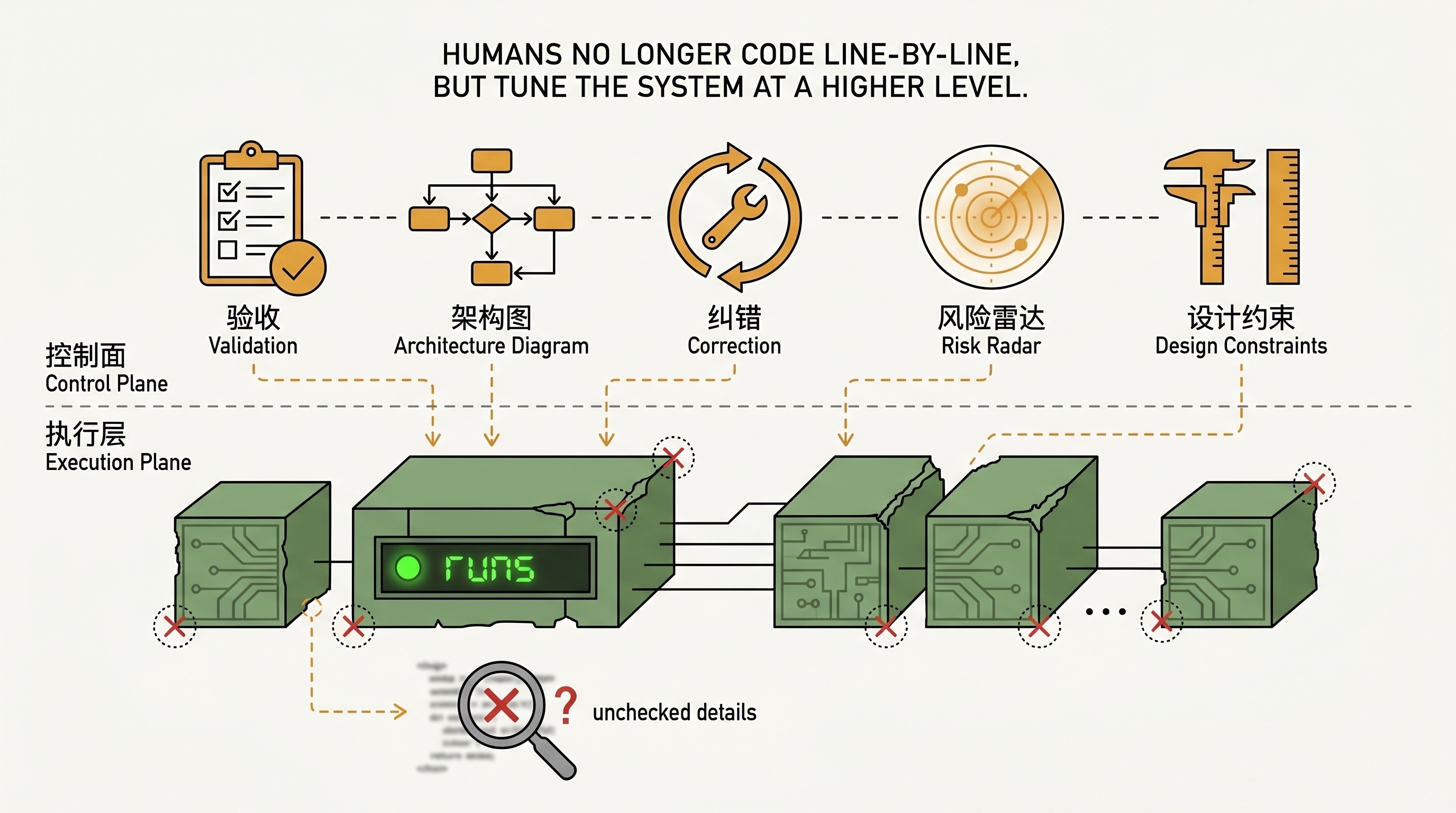
从逐行实现,到验收、纠错和系统设计
以前我写代码时,会一边写一边处理这些问题:这里要防御,那里要抽象,这个状态不能这么放。
现在很多时候是 agent 先写,我再验。我的能力变成了另外一种形式存在。以前这些判断发生在写代码过程中,现在更多发生在验收过程中。执行可以交给 AI,验收不能交,因为验收的本质是责任分配和信任问题,目前 AI 还不能承担。
一个它做坏的例子
我遇到过一个对话流的问题。
系统里有多个对话。原来的设计是,每个对话可以单独 pending,互不影响。同时还有一个全局 pending,用来表示整体状态。
也就是说,这里其实有两层 pending。
我让 agent 修一个中间状态。它修完以后,用了一个单例 pending。
结果就变成:第一个对话 pending 的时候,第二个对话也不能继续聊了。
原来应该是:
conversation A -> pending A
conversation B -> pending B
conversation C -> pending C
global -> overall pending
它改成了:
conversation A/B/C -> one pending
这个问题不是语法错误,也不是少写了一个判断。它把状态维度改错了。
而且我不是读代码发现的。我是在测试别的功能时发现:一个对话 pending,会影响另一个对话。
然后我让它 debug。过程大概是这样:
- 它一开始说,代码就是这么设计的。
- 我继续问,为什么要这么设计。
- 我让它从 git log 看看,这个设计是什么时候变成这样的。
- 它解释完以后,我才意识到问题在哪里:它只看到 pending 这个状态,没有理解这里需要两层 pending。
这类问题很常见。AI 修局部问题时,可能会改坏系统原来的语义。尤其是状态、并发、作用域、所有权这些地方,它很容易把复杂结构压成一个简单结构。
但我不会因为这个就不让它做。
这种错可以接受。关键是我能发现它,让它解释,再把正确模型补进去。下次再遇到类似情况,这个信号应该被记住。
记忆不要都塞进 agent.md
我写了一个记忆系统,用来记录这些判断。
不是把所有东西都永久塞进上下文里。它会蒸馏,也会遗忘。如果一条经验长期没被用到,那就忘掉。忘了说明它没那么重要。
很多人会把这些内容放进 claude.md 或 agent.md。比如:不要把 pending 写成单例;这个项目里 pending 有两层;某个组件不能这么改。
我现在不太喜欢这样做。原因不是 agent.md 没用,而是它和 memory 的职责不一样。
agent.md 适合放少量稳定规则,比如项目命令、编码规范、绝对不要做的事情。它不适合越写越长。
原因也很简单:它是常驻上下文。每次都加载。内容越多,干扰越多。而且项目一直在变,早期写下来的设计不一定还对。
我更倾向于把经验放进 memory。memory 是按场景触发的。只有遇到相似问题,它才应该出来。
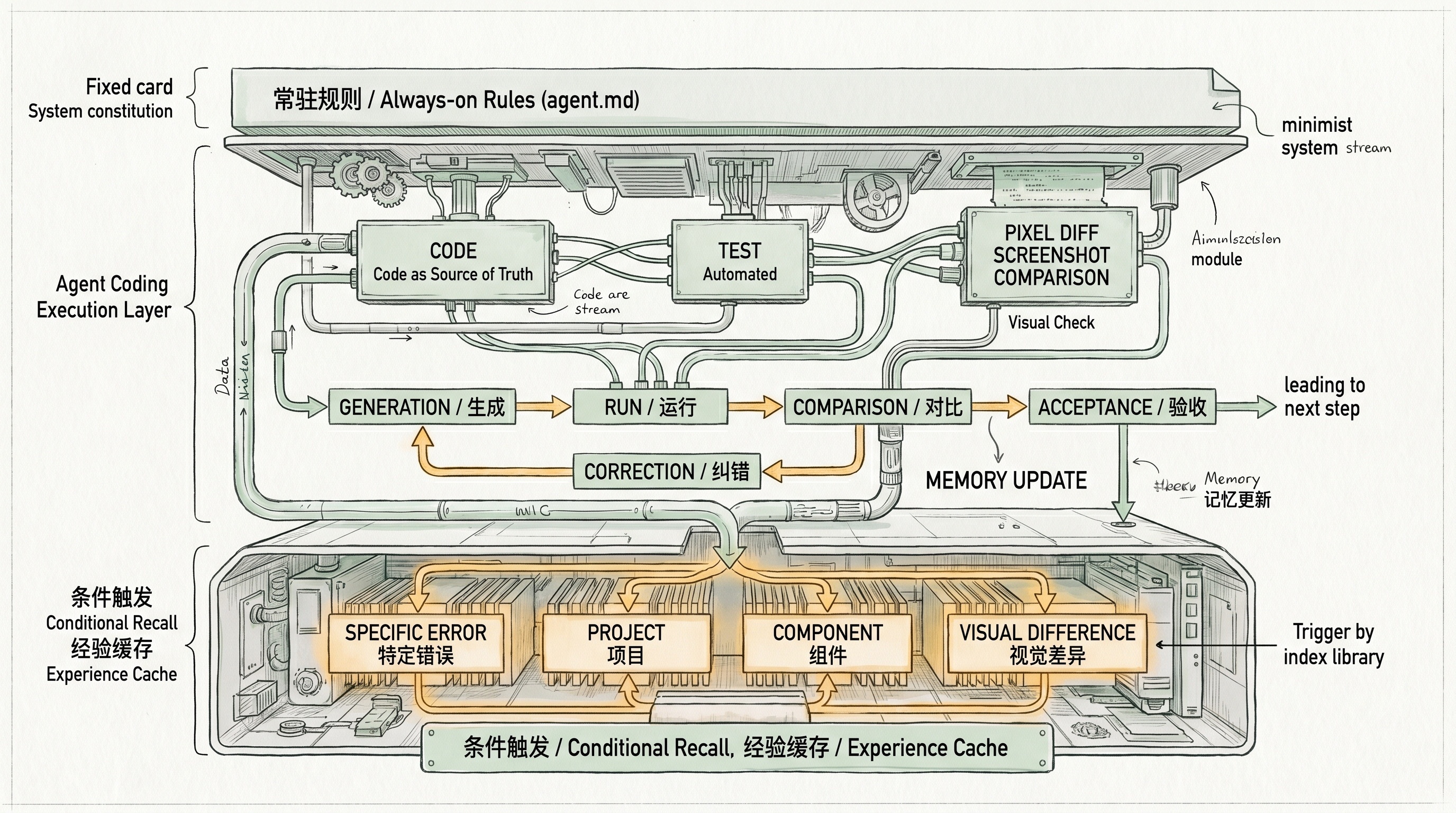
Memory 与 agent.md 的分工:常驻规则要少,经验缓存要条件触发
代码本身应该是最高优先级。项目现在是什么样,应该先看代码,而不是先相信一份很久以前写的说明。
所以我的原则很简单:
agent.md要少。 只放稳定规则和项目约束。- memory 可以多,但要能忘。 它应该按场景触发,而不是每次都出现。
- 代码永远优先。 当前代码比旧文档更可信。
这件事对我很重要。因为 AI 编程最麻烦的不是它没上下文,而是它带着一堆过期上下文还以为自己懂了。
不要一直停在结对编程
AI pair programming 当然有用,但如果一直停在那里,人还是很累。你说一句,它写一段;它错了,你改一段;你再解释,它再写。这样看起来用了 AI,但人的注意力一直被绑在每一步上。
我现在更想要的是让 agent 自己先跑几轮:先做,自己检查,自己修。 多轮之后,我再看剩下的问题。
大概流程是这样:
agent 执行
agent 自检
agent 修正
agent 再执行
human 验收
human 提供判断
memory 记录判断
下一轮继续
测试它自己会跑,但我不会要求它每次都跑,太慢,只有有价值的地方才补测试。UI 我会先看 pixel diff,再自己点页面,因为 UI 很容易被它改坏。Network 我会让 Chrome 持久化到本地,因为请求数量、请求参数、过滤条件,这些都是真实行为的一部分。多轮 review 我也会用,但我不希望它每一步都问我。
我希望它有一条固定路径:该查就查,该跑就跑,该看日志就看日志。它自己判断哪些值得做,不要每次都等我确认。这里的变化是,我不再当低级调度器。我只定边界,最后验收。
以后我会先改流程,而不是先改代码
如果我要带一个 AI-native 的工程团队,我大概会要求几件事:
- 任务先给 agent 做,不要一上来就手写。 不是说手写代码不好,而是你一手写,就绕过了这套流程。团队需要训练的是“怎么让 agent 做对”,不是继续训练每个人当手工高手。
- 验收必须自己做。 AI 写完不代表完成,自己点一遍,自己看请求,自己看异常,自己看移动端。
- 遇到问题时,不要急着自己修。 先想:为什么它没自己发现?为什么测试没覆盖?为什么工具没给它足够的信息?为什么 memory 没触发?为什么代码结构让它理解错?
很多时候我不应该直接修 bug,而应该修那个让 AI 能修 bug 的流程。这句话听起来有点绕,但意思很朴素:如果我每次都亲手补洞,那下次还是我补;如果我把工具、验证、记忆、代码结构改好,后面同类问题就可以少找我。
我早期还是会大量介入代码,重构项目,让它更容易被 AI 理解。等这个模子形成以后,我改得最多的就不是业务代码了,而是工具能力和验收机制。对我来说,收益最大的两个东西是 pixel diff 和 本地记忆系统。pixel diff 让验收变简单,本地记忆系统让我不用反复解释同一类问题。这两个东西比多写几个 prompt 模板有用。
我相信 AI 的解释,但是不相信 AI 的结论
当 agent 修 bug 失败时,我不会马上告诉它答案。我会先让它 systematic debug:先复现,再找原因,再解释代码路径。它要说清楚现象是什么,原因是什么,为什么这个修法能解决,以及怎么验证。我相信解释,不相信结论。 如果它解释清楚,我就继续让它做;如果它开始前后矛盾,我会新开一个对话,让它先总结事实。
这不是重来,只是清理上下文。一个对话太长以后,经常会混进很多错误假设。继续在里面追问,只是在坏上下文上继续打补丁。该丢就丢,该总结就总结。
这也是我为什么说,agent coding 的核心不是 prompt,而是反馈回路。Prompt 追求一开始说清楚,但真实开发里,一开始很难说清楚,很多判断要等东西跑起来以后才会出现。所以我现在的做法是:先让它做一版,尽快得到一个可以验收的结果,然后我用工具、运行结果和自己的判断去纠正它,重要的纠正再进入 memory 和流程。
我不是不写代码了,只是我越来越少把第一反应放在“这段代码我来写”上。我更关心的是,下一次类似问题,AI 能不能自己发现,自己解释,自己修好。这就是我现在理解的 agent coding。