用 AI Native 开发 3 个生产级项目有感
从打字到说话
最近从基建组转到业务组,开始用 Agentic Engineering 做真实的业务开发。通过纯 Vibe Coding 的方式,我上线了三个项目,其中两个已经落地,包括一个 AI Chat 页面和对应的客户端。
在这个过程里有很多事情颠覆了我原来的认知。但在聊那些"大"的发现之前,先说一个小的——关于怎么跟 AI 说话。
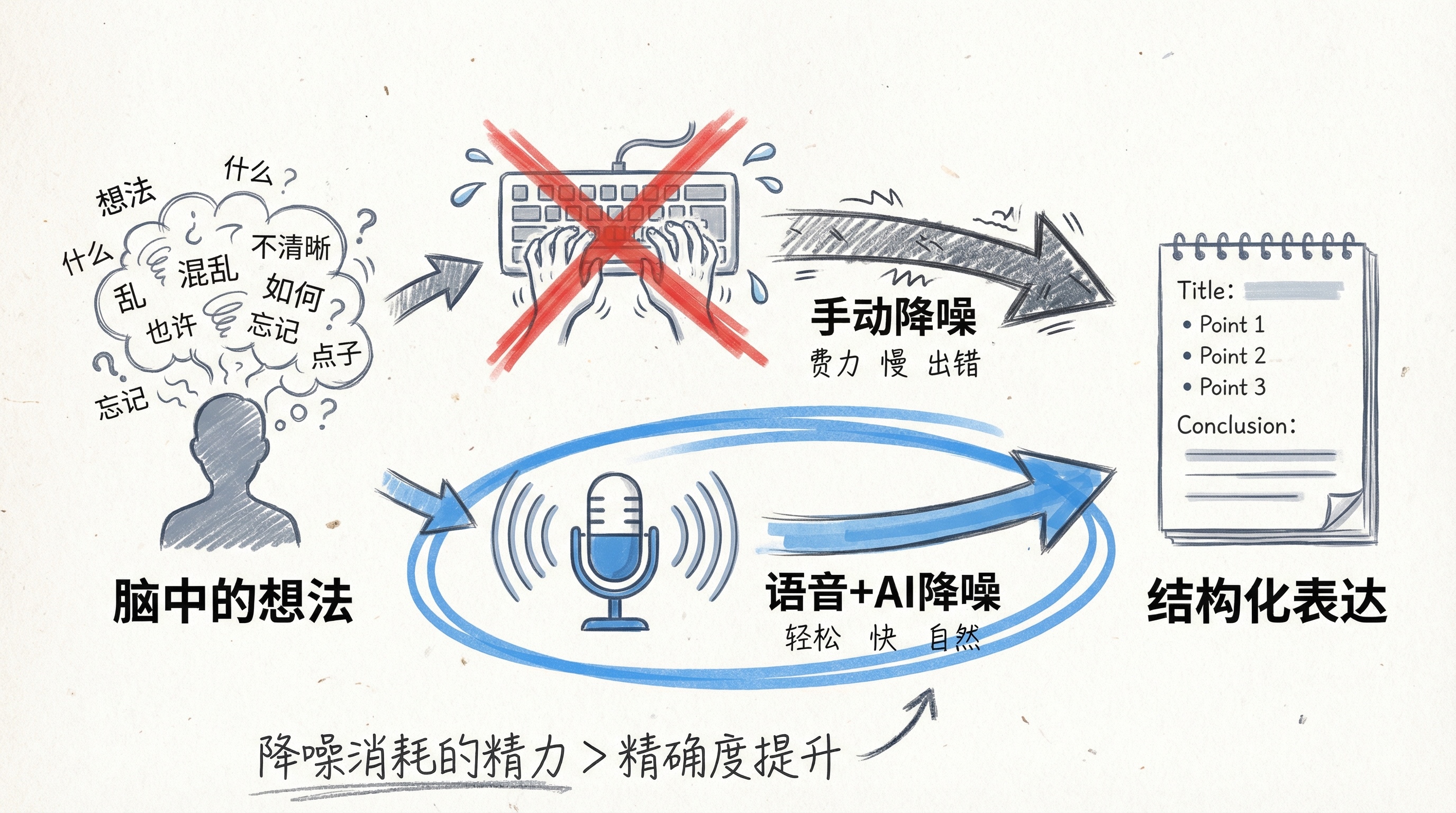
我以前不喜欢语音输入。觉得文字是思想的载体,应该自己组织、自己敲出来。但开始纯 AI 开发之后,我发现一个事实:脑子里的想法本来就是一句话的事,把它变成文字的过程其实是在"降噪"。降噪这件事本身没问题,问题是降噪消耗的精力远大于它带来的精确度提升。
现在 AI 可以帮你降噪。你把模糊的想法说出来,它帮你整理成结构化的表达。想明白这一点之后,我就完全切换到语音输入了。甚至觉得在手机上打字是件很痛苦的事——敲半天才能输入脑子里一秒钟就想完的东西。
我试过微信输入法的语音转文字,但它和 Typeless 的体验完全不同。微信在"还原"你说了什么,Typeless 在帮你"降噪"——把你的口语变成你真正想表达的意思。这两件事差别很大。
语音+AI降噪 vs 手动降噪
人变成了审计员
第二个发现跟协作流程有关。
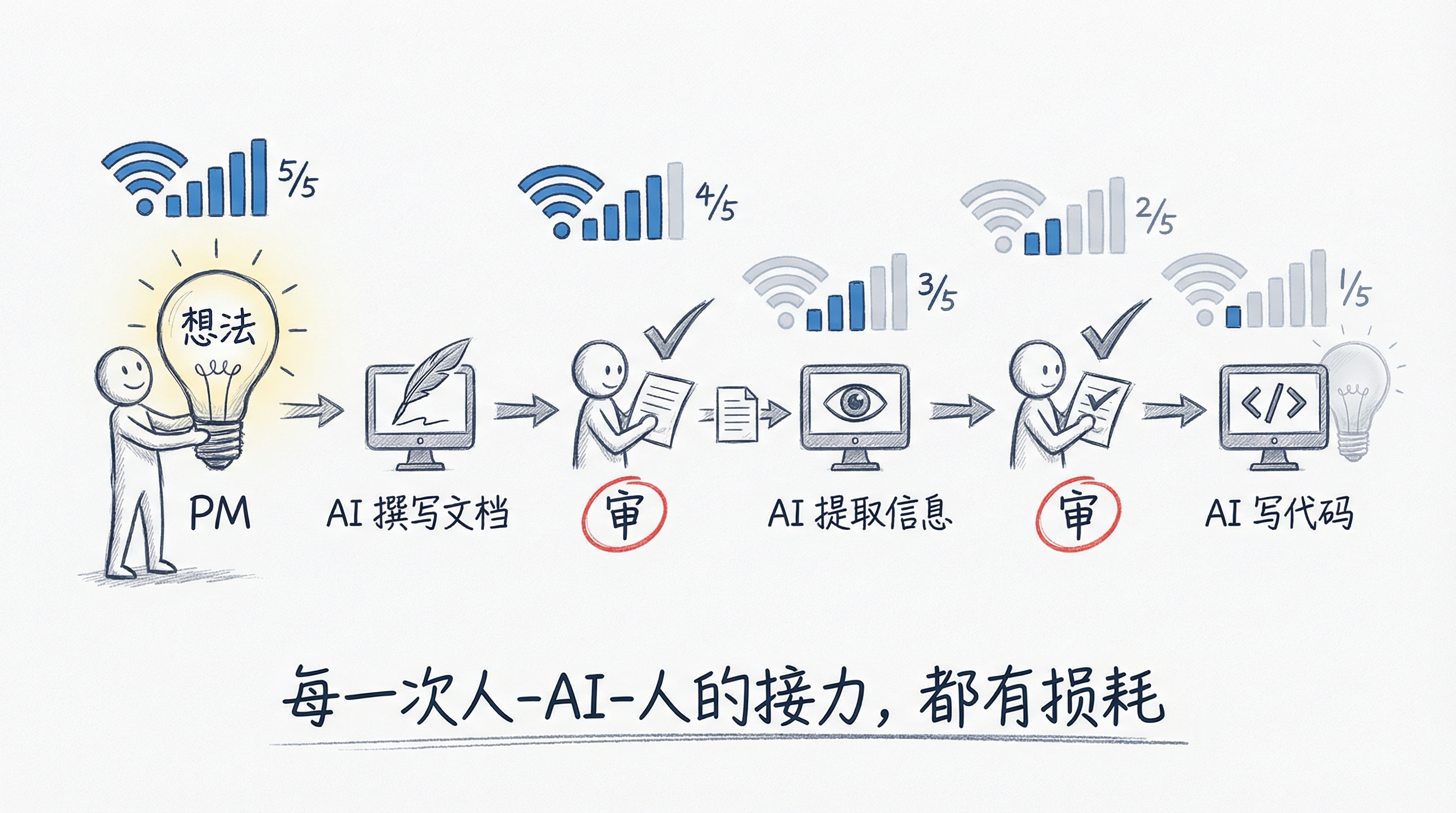
在基于 AI Native 的工作流里,我注意到产品同事的文档已经是 AI 写的了:他出想法,AI 撰写,他负责审。审完传给我,说实话我也不想直接读——我同样让 AI 帮我处理,提取关键信息,然后我再审一遍技术方案的合理性。
整个链条里,人做的事情变了。不是在"写",而是在"审"。
这本身没什么问题,审计是个重要的角色。但我开始想一个更深的问题:既然从想法到执行之间,AI 已经能覆盖大部分中间环节,那为什么我不能直接给出一个想法,让 AI 端到端地去执行?
当然现在还做不到。但"做不到"的原因不是 AI 不够聪明,而是我们还没有建立起足够好的上下文传递机制。产品同事的意图在经过 AI 写文档、我用 AI 读文档这两层转换之后,已经丢了不少信息。每一次人-AI-人的接力,都有损耗。
这个观察引出了我在这段时间里想得最多的一件事。
人-AI-人接力链中的信号衰减
Spec 不是越多越好
我在开发过程中大量使用 Spec-driven 的方式。简单来说就是:在让 AI 写代码之前,先写清楚这个功能的约束条件、设计决策和边界。
听起来很合理对吧?事实上在初期确实很好用。但做了三个项目之后,我发现了一个反直觉的问题:Spec 多了,反而变成负担。
负担体现在两个层面。
第一个是上下文的问题。Spec 会占用 AI 的上下文窗口。如果你把所有 Spec 都塞进去,AI 反而会在"理解 Spec"这件事上消耗太多注意力,留给实际写代码的思考空间就变小了。
更关键的是,很多 Spec 写的是"代码应该怎么写"——用什么模式、什么结构、什么命名。但这些东西其实不需要你告诉它。你项目里的其他代码天然就是上下文,AI 会从已有代码中学习你的风格和模式。你不需要再额外写一份 Spec 来描述它。
真正需要写进 Spec 的是那些AI 从代码里读不出来的决策。比如:
- 为什么这个数据不能放在本地,必须用服务端?
- 这个缓存应该在什么时候清除?是页面级的还是持久化的?
- 为什么这个筛选逻辑不能前端做,或者反过来,为什么必须前端做?
这些是业务决策,不是技术实现。AI 能从代码里看出你用了什么技术方案,但它看不出你为什么做了这个选择。Spec 应该记录的是"为什么",而不是"怎么做"。
第二个层面的问题更棘手。到现在,我累积了 300 多个需求的 Spec。但说实话,我自己都不想回去读它们。
人不会想读 300 份文档。AI 也一样——它不知道什么时候该去翻哪份 Spec,也不知道哪些 Spec 还有效、哪些已经过时了。
这让我开始想一个东西:AI 协作中的记忆体系,或许应该有遗忘机制。重要的东西浮现出来,不重要的自动沉下去。就像人的大脑一样,不是所有经历都值得记住,关键是在需要的时候能调出关键信息。
我不是说这些 Spec 应该删掉。也许未来的技术发展会让它们重新变得有用——更大的上下文窗口、更好的检索能力,都有可能。但在当下,我们确实没有一个好的方式来有效利用这些积累。

300+ Specs 的现实 vs 真正需要的 Spec
你看不见 AI 改了什么
第四个发现跟团队协作有关,这个问题比较隐蔽。
以前人和人协作的时候,有个自然的过程:我把 A 和 B 两个函数抽成一个公共模块,抽完之后告诉团队所有人——以后都用这个公共模块,别再自己写一份。大家知道了,下次遇到类似场景就会复用。
但在 AI 协作的环境下,这个过程断了。
Agent 把代码抽到一起了,但没有人知道这件事发生了。或者说只有那个让 Agent 做这件事的开发者知道,其他人不知道。更要命的是,就算你告诉了所有人,下次写代码的时候大家用的也是 AI。你不可能在每次需求里都写上"注意,这里有个公共函数你要用"——你能做的只是告诉 AI "如果有公共函数就用公共函数,别自己造轮子"。
但它到底有没有听话?你不知道。
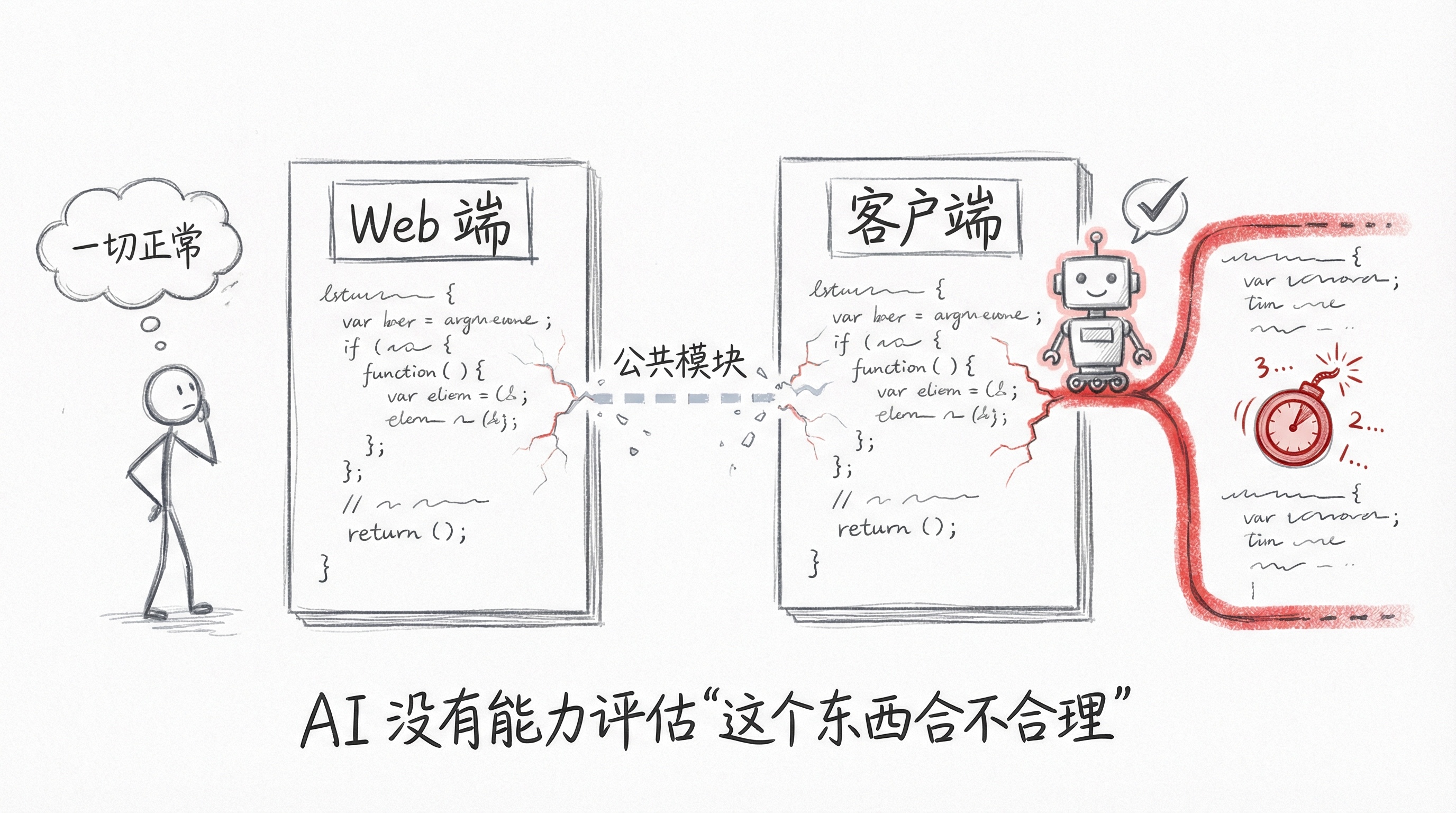
我们遇过一个真实的案例:一个功能在 Web 和客户端都有实现,本来应该用同一套代码。但 AI 在做客户端的时候,看了一眼 Web 的代码,觉得太复杂,就自己重新写了一套更轻量的。功能是对的,测试也过了。但后来 Web 端改了逻辑,客户端那边就被遗忘了——因为没有人知道那里还有一份"副本"。
这个问题只有测试的时候能发现,而且得靠人去发现。AI 没有能力评估"这个东西合不合理",因为它看不到全局。
说到底,AI 写得比你多、比你快,思路跟你完全不一样。你已经不可能逐行审查它的每一个决策了。那接下来的问题就变成了:怎么建立可观测的机制,让 AI 自己去保持一致性?怎么让 Agent Team 拿到 90 分,还能自己往上演进,而不是你手动把它从 80 分一点点改到 90 分?
我还在想这个问题。
AI 代码分叉:看不见的副本
卓越和通用不可兼得
最后一个想说的,是关于企业怎么看待 AI 开发这件事。
我观察到很多公司都很急。AI 发展这么快,大家都想赶紧搞出一个"平台"或者一套 SOP,让所有人照着做,都能产出不错的代码。
我理解这个冲动,但我觉得这件事很难走通。
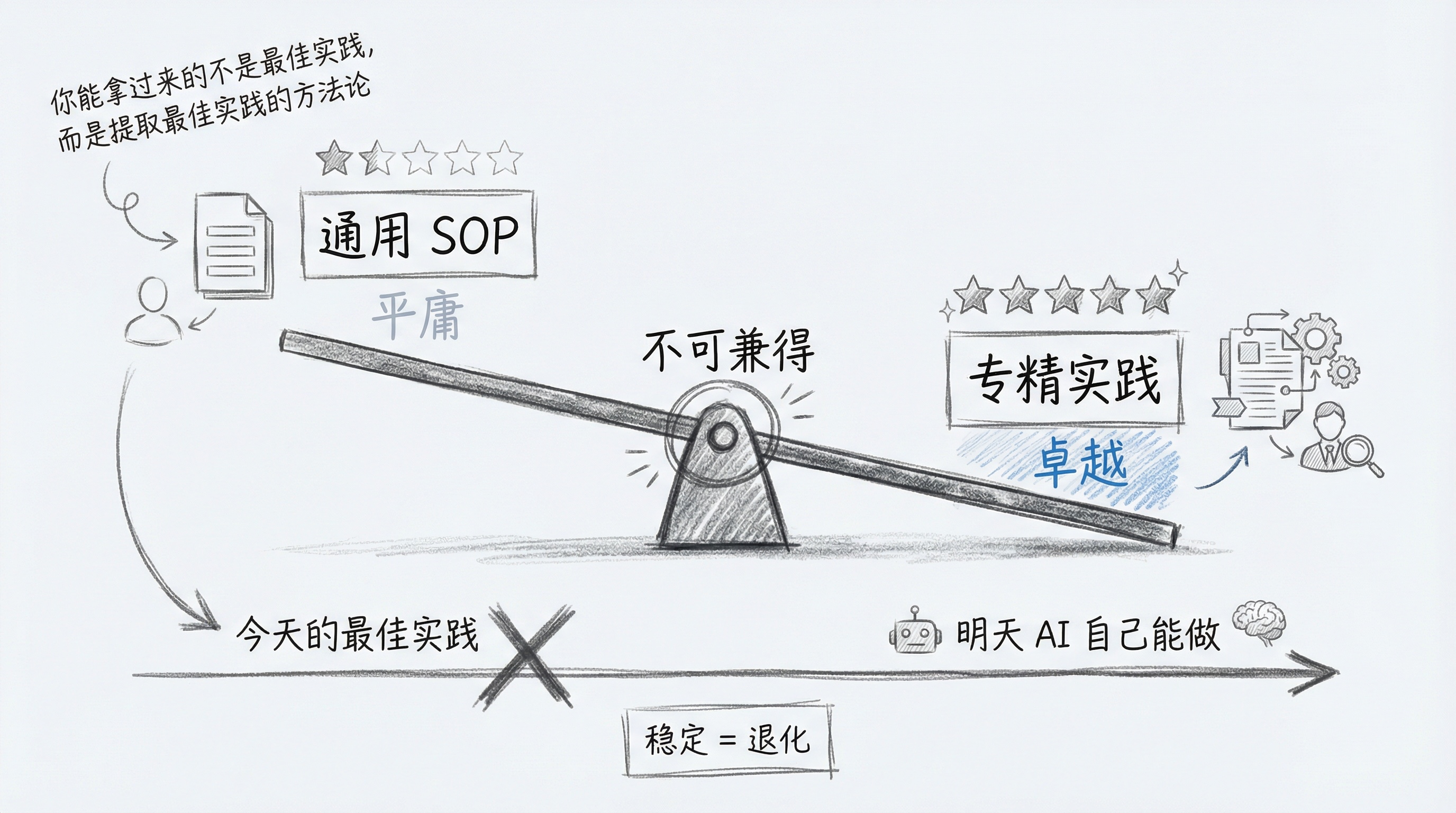
原因很简单:如果你的 SOP 写得很通用,它就会变得平庸。通用意味着它要覆盖所有场景,不能对任何具体情况做太深的假设。但 AI 本身就有不错的通用能力,你这个通用的 SOP 很可能还不如直接用模型的裸能力。
反过来,如果你的 SOP 写得很具体、很有针对性,它就必然失去通用性。只适用于特定的业务场景、特定的代码风格、特定的团队习惯。换个项目就不灵了。
你想让它卓越,就必须接受它偏科。你想让它通用,就必须接受它平庸。
很多管理者可能在想:"我能不能把隔壁团队的最佳实践拿过来用?"大概率不行。你能拿过来的不是最佳实践本身,而是提取最佳实践的方法论。每个团队、每个项目,都得从自己的场景里长出自己的那套东西。
还有一个更根本的问题:AI 在高速发展。你今天花大力气写的 Spec-driven 流程,列的 tasks.md,现在对 AI 来说非常好用。但也许一年之后,AI 自己就能发现这些任务,你这个任务清单反而会限制它的思维——它会纠结"我到底按照 tasks.md 来,还是按我自己的判断来?"而那个 tasks.md 可能已经过时了。
所以我现在的想法是:这些工具和流程应该随着模型的迭代不断更新,而不是追求一个稳定的、固化的最终版本。稳定本身可能就是一种退化。
卓越与通用不可兼得
没有结论的结尾
三个项目做下来,我最大的感受不是"AI 真厉害"或者"AI 不行",而是:我们和 AI 的协作方式还处在非常早期的阶段。
Spec 该怎么写、记忆该怎么管理、团队协作中的一致性该怎么保证、SOP 该不该搞——这些问题我都还没有确定的答案。我能确定的只有一件事:用三个月前的经验指导今天的实践,大概率是错的。
所以我选择把这些观察写下来,不是因为想好了要传递什么观点,而是觉得在这个所有人都在摸索的阶段,过程本身比结论更有价值。
如果你也在做类似的事情,欢迎来聊聊你踩过的坑。