我每天上班第一件事,是给一群机器下属批改作业

cover
AI 推到第三个季度,我发现自己每天 40 分钟在 inbox 里批准、否决、改方向、派任务,处理的全是机器昨晚交上来的作业。这件事比管人冷得多,效率也高一个数量级。然后某天我意识到一个挺荒诞的问题:我正在帮公司变得更高效,还是正在让公司变得不再必要?
早上九点的 inbox
我现在每天上班的第一件事,是打开电脑批处理 AI 留下的一堆东西。
过夜跑出来的报告、自动起草的 PR、Lark 里它整理好的会议纪要和 @ 我的待办、卡在某一步等我点头的工单、还有几条它升级上来的“我觉得这事得你看看”的提醒。
一杯咖啡,大概 40 分钟。我会挨个过:这个 PR 改的方向不对,打回;这份报告主线对了,细节再补两个数;这个工单可以让它走自动修复;那个客户反馈背后藏了一根线,我得自己去看一下原始上下文。处理完了,人和 AI 重新各自上路,我去开会、它去跑活儿。
这个动作我做了大半年。最近某天我突然意识到一件事:我每天上班的第一个小时,本质上是在管理一群机器下属。
那一刻我有点恍惚。我管人的时候要照顾情绪、要给反馈、要做职业发展规划;我管这群机器下属的时候,只需要批准、否决、改方向、派任务。后者比前者效率高出一个数量级,也冷得多。两种工作模式,正在我身上慢慢分叉。
后来我把这半年看到的、做到的、栽过跟头的,慢慢梳理成了一张地图。这张地图不是什么学术框架,更像是一个正在亲历变革的人,半夜睡不着觉时画给自己看的草图。它要回答的是:我们到底走到哪儿了,前面还剩什么,哪些坑是真的,哪些幻觉是假的。
我把它叫做 AI-Native 的五层模型。
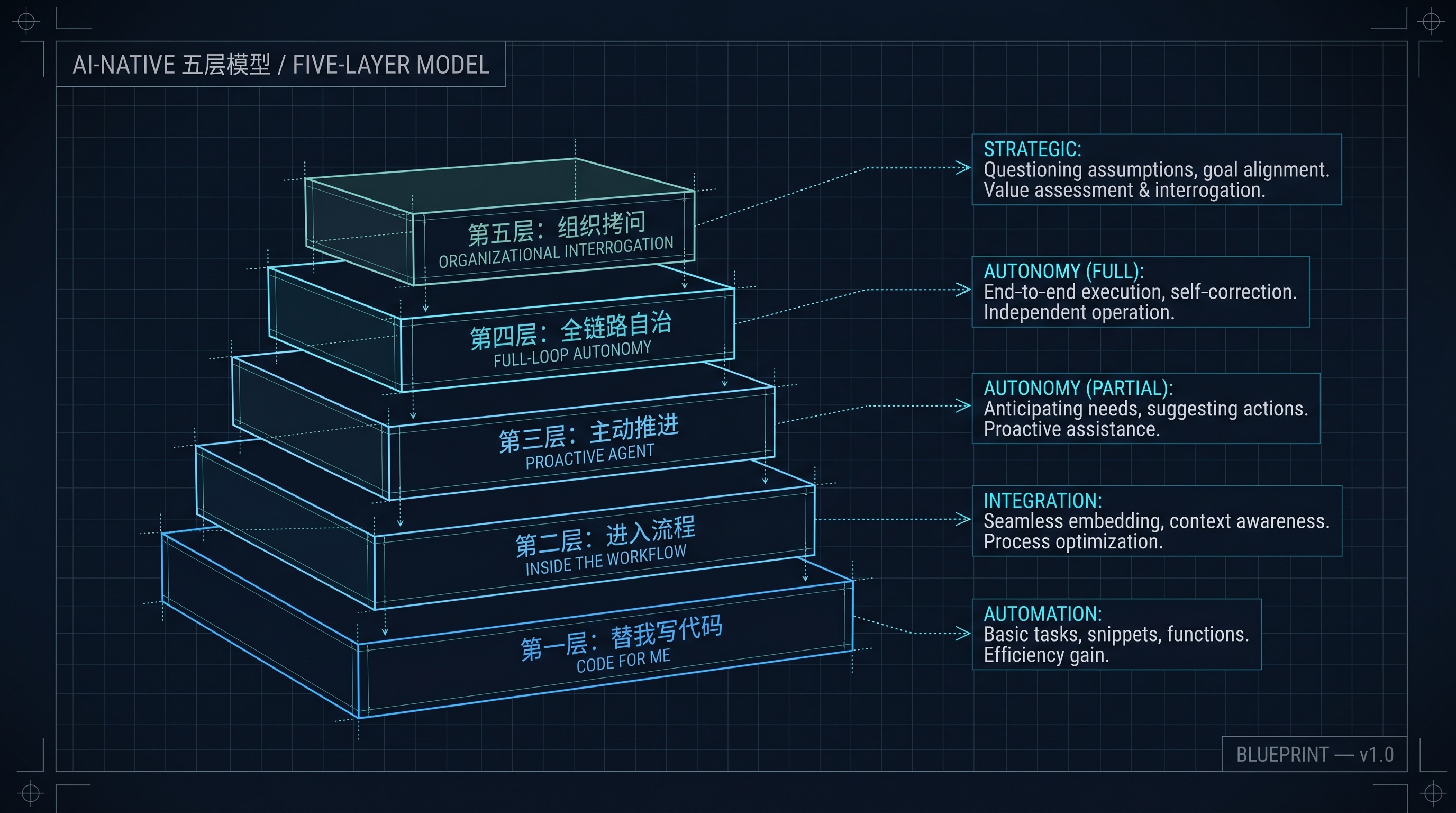
AI-Native 五层模型总览
第一层:替我写代码
最早大家用 AI,都是替自己干活。
最典型的就是写代码。我团队里几个工程师,从 Cursor 用顺之后,基本不再手写第一版。需求来了先和 AI 聊清楚,让它出底稿,再自己改。文档也一样,周会纪要 AI 起,自己润色;评审材料 AI 起,自己改逻辑。
这一层和上一层(传统人工写代码)的根本差异是什么?是工具被替换,但工作没有变。 人干的活儿没动,只是换了个更高效的执行者。和当年从 Vim 换到 VSCode、从 SVN 换到 Git 是一回事。
它的边界也很清楚:AI 只服务于“我”这个独立的个体。 它不知道我们部门在做什么大项目,不知道隔壁组上周提了什么需求,不知道我老板今天为什么发火。它就是我桌上一个特别能干的工具。
唯一的副作用挺反直觉:工程师每天写代码的时间从 6 小时降到 2 小时,剩下 4 小时去哪儿了?开会、对齐、扯皮、走流程审批。所以这一层落地之后,工程师抱怨开会变多了。
抱怨没错,但也错了。AI 抢走的其实是那 6 小时“我太忙了不能开会”的借口,代码反倒是次要的。一个工程师过去之所以能逃掉一些没用的会,是因为他可以指着显示器说“这段逻辑很复杂,我得静下来写”。现在 AI 把这段逻辑半小时就写完了,他不得不真的去面对那些会议。
到这里,组织还是原来那个组织。AI 只是在每个工程师的桌面上各自闪光。
第二层:进了协作流程(我们目前在这里)
第二层的标志,是 AI 从服务个人变成服务流程。
这一层长什么样?我可以画一个具体的画面。
我们部门的 Lark 群,过去最忙的角色是几个内部支持。早上 9 点开始,产品经理、QA、客户经理在群里抛各种问题:“上线计划改了吗?”“那个客户的合规审批走到哪一步了?”“昨天那个 P3 工单分给谁了?”这些问题 80% 是重复的、20% 是有标准答案的、剩下少数才需要真正的判断。过去这些重复劳动消耗了好几个 HC。
现在我们部门的 Lark 群里,接了一个 Q&A bot。它读知识库、读工单系统、读发版日历,绝大部分重复问题它直接答了。会议纪要也是它做,自动同步到 Lark 文档,@ 上相关的人。内部 IT 工单也走它先过一遍,简单的事情(如重置某个测试账号、申请某个开发权限)它直接处理。
这一层和第一层的根本差异是什么?是 AI 从“个人桌面”进入了“团队基础设施”。 它服务的不再是某一个工程师,而是整个流程。它的输入和输出都嵌进了团队的日常协作中。
但它有个非常明确的天花板:它仍然是被动响应的角色。 你问它就答,你不问它就在那儿待着。
这个天花板是什么时候让我看清的?是一次线上事故。
那次事故的根因藏在某个工程师两周前的一条 Lark 消息里。他在一个有四五十人的项目群里轻飘飘地说了一句:“我看了下这块改动,Y 业务线那边的对账逻辑可能要受影响。”那条消息发出来以后,有人随手“收到”,有人没看见。他自己后来也忘了。
两周后,Y 业务线的对账真的出了问题。客户投诉,合规上报,一路追到我这儿。复盘的时候我特别难受:那条消息 AI 全都“看见”过。它做过那次会议的纪要、它处理过那个项目的 IT 工单、它甚至帮人翻译过那条消息给海外团队。但它没有“识别风险”这件事的能力。
它处理消息,不读懂消息。它整理纪要,不理解纪要里哪条决议没人接。它回答问题,不去问“这个问题为什么没人问过”。
第二层的天花板就摆在这儿:它解放的是手,没解放眼睛和判断力。
我们现在主要就在这里。这一层的甜头很容易吃到。上线一个 Q&A bot、配一个会议纪要工具,两周就能看到 ROI,老板汇报的时候 PPT 也好做。所以很多团队会在这里停下来,觉得自己已经“AI-Native 了”。
其实只是装了个更聪明的客服。
第二层到第三层之间:那道真正的坎
要从第二层迈到第三层,中间隔了一道很多人没说清楚的坎:上下文。
上下文这件事有四个层层递进的难题。我们一个一个看。
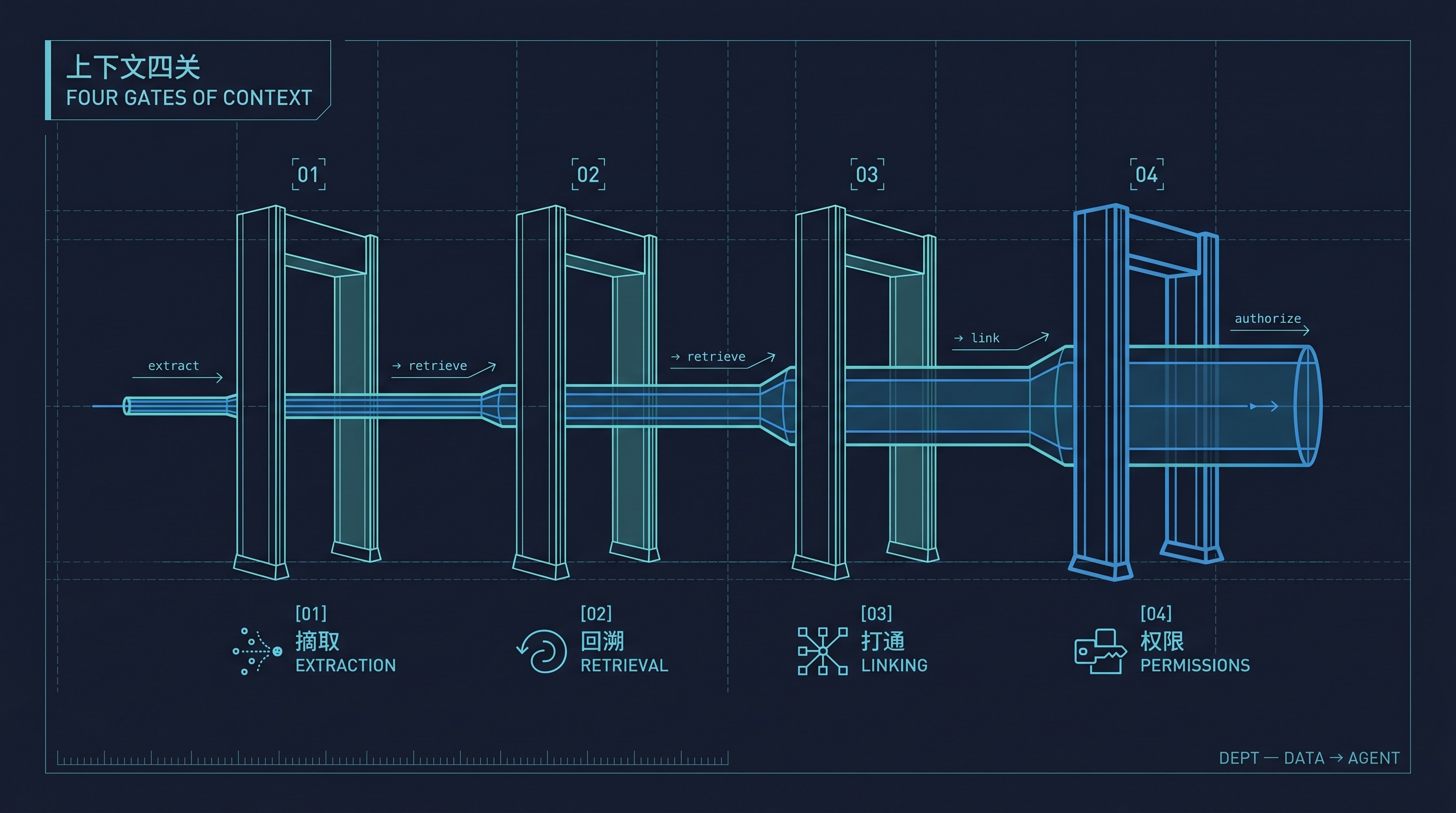
上下文四关:摘取、回溯、打通、权限
第一关:摘取
AI 要做事,首先得知道“现在在发生什么”。
一个客户问题来了,AI 要看的不只是这条消息,而是消息背后整个故事的合理摘取:这个客户是谁?他过去三个月提过什么问题?他的合同等级是什么?他这次抱怨的功能上次是谁改的?改动当时通过审批了吗?发版的时候监控有没有报警?
这些信息散在 CRM、工单系统、Git、Jira、监控平台、发版系统、Lark 群聊、Lark 文档。每个系统的接口、字段、权限模型都不一样。光“客户”这一个实体,在 CRM 里叫 customer_id,在工单里叫 account,在合同系统里叫客户编号,在合规系统里叫主体代码:四套 ID,没人能告诉你完整的映射关系。
让 AI 摘出“刚才发生了什么”,这件事的工程量,主要花在大量翻译工作上。
第二关:回溯
光看当下不够,AI 要会往回翻。
一条线上 error log 出现的时候,真正决定怎么修的信息可能藏在三个月前的一次架构评审会议纪要里。当时讨论过这种边界情况,选了一个权宜方案,留了个 TODO,后来没人追。
让 AI 回溯,意味着它要能从今天的现象,反向找到三个月前那次会议、那个文档、那条决议、那个具体的人。回溯链路越长,AI 跳的次数越多,每跳一次都要重新加载一遍上下文,每一次跳跃都是一次代价不低的成本。这不只是 token 烧得快的问题,更是每一跳都可能丢失关键信息、走错方向。
第三关:打通
摘出来了、回溯到了,接下来是关联。
光知道“这个客户提过这个问题”,不够。AI 要能把这个客户问题、上次的代码改动、当时的监控曲线、合规上的限制、产品 roadmap 里的优先级排序,全部关联起来,看到一张完整的图。
这件事特别难,因为这五张表分别属于客服部、研发部、运维部、合规部、产品部。每个部门的数据治理标准不一样,有些部门的核心数据根本就没数字化、还存在某个总监的脑子里。
真正在做的事情,是数据集成、schema 统一、跨部门权限协调,跟训模型基本无关。
讽刺的地方在于,这件事的难度不是 AI 带来的。这是十年前我们就该解决的“数据中台”问题,只是过去一直能拖。AI 之所以让我们必须现在动手,是因为它把“上下文不联通”的成本从隐性变成了显性。以前数据孤岛,无非是开会时多吵几句;现在数据孤岛,直接卡死你的 Agent。
第四关:权限和组织重力
最后一关最难,因为它不是技术问题。
AI 要跨系统拿数据,绕不开权限。一个 AI Agent 想要看 CRM 里的客户数据,得有客服部的授权;想要看 Git 里的代码,得有研发部的授权;想要看合规系统的备案,得走法务的流程。每多一层组织,就多一道门。
而且这些门是设计给“人”的,不是设计给“AI”的。给一个工程师开一个权限,有他主管签字、有他岗位职责背书、出问题能找到他;给一个 Agent 开权限,谁签字?谁背书?它出问题谁负责?
我们部门有过一次讨论,讨论给 Agent 开生产环境只读权限。开会开了三次,合规、安全、运维、法务都来了,最后没敢开。技术上能做到,问题是没人愿意在这个东西上签字。
组织层级越深,AI 跳上下文的代价就越高。 在一个 30 人的小公司,AI 拿任何数据可能就是一行配置;在一个 3000 人的业务线,AI 拿同样的数据要走三个部门、五张表、八个审批节点。
说到底,这是组织重力的问题,跟技术关系不大。
我们 dev 环境里“日志到代码”这条链路已经跑通了。AI 能读到一条 error log,关联到代码,起草一个修复 PR。整条链路是闭环的,在测试数据上跑得也漂亮。但我们还不敢把它放到生产环境:数据通道还有死角,权限模型还没敢给它生产读权限,真出了事谁负责的问题还没想清楚。
这道坎卡住了我们大概两个季度。现在我特别理解为什么很多 AI 项目最后都搞成了“内部 demo”:瓶颈从来不在技术,在上下文跨不过组织。
第三层:开始变得魔幻
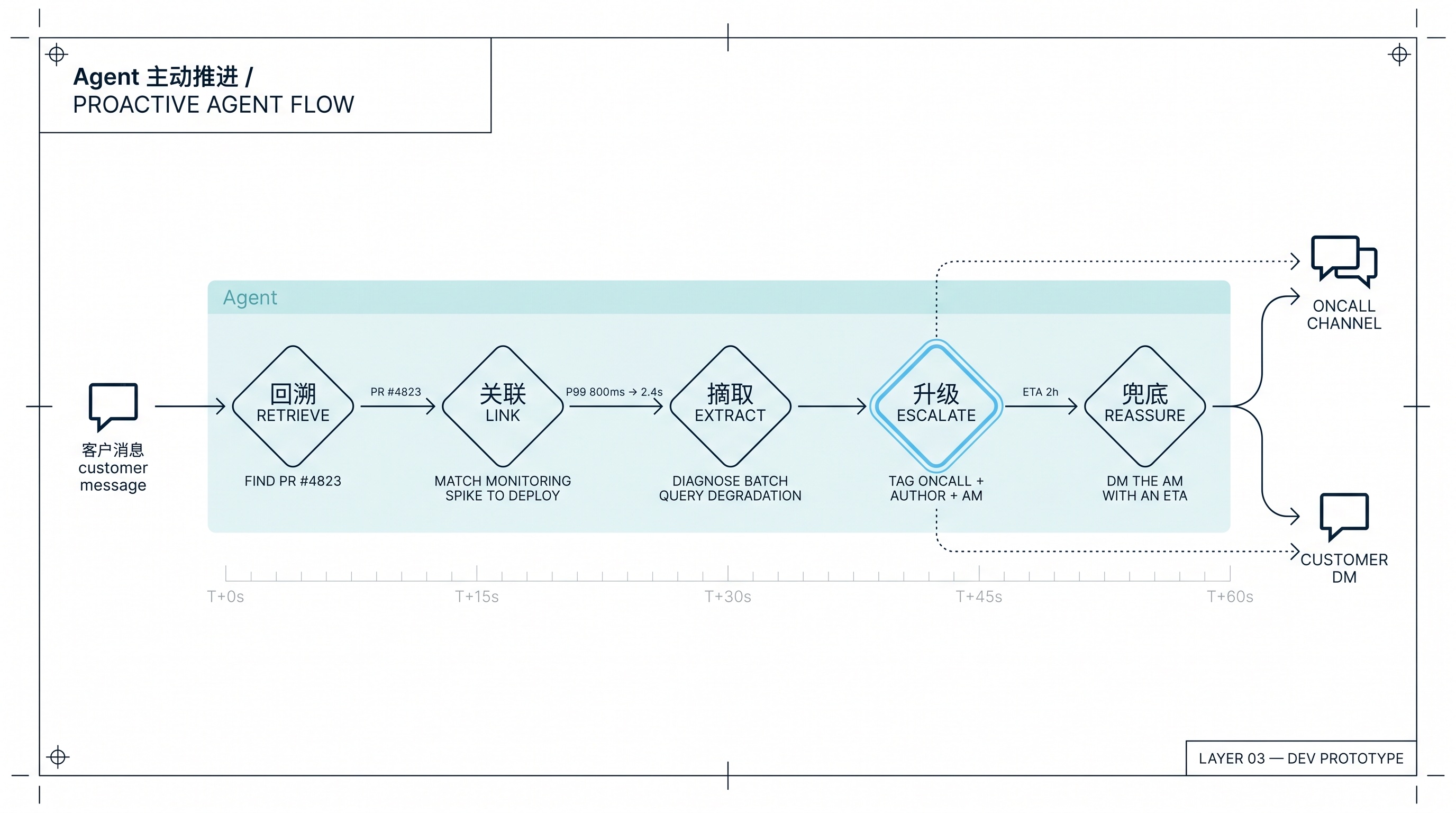
Agent 主动推进:从客户消息到自主升级
如果上下文这道坎能跨过去,第三层就开始有了。
我至今觉得这一层有点不真实。技术上做出来其实没那么难,真正让我意外的是做出来之后那个画面。
我先描述一下我想看到的样子,以及我们 dev 里已经能看到一部分的雏形:
某个早上,一个客户经理在 Lark 里转发了一条客户的吐槽:“你们那个 XX 功能这周变慢了,我们后台批量跑批一直超时。”
过去这条消息会经过一长串接力:客户经理 @ 产品经理,产品经理 @ 研发主管,研发主管在群里问“谁知道这事”,有人记得上周改过相关代码,@ 那个工程师,工程师上线一看监控、翻发版记录、找 PR、找日志……一圈下来两三个小时,客户那边还在等。
第三层的样子是这样:Agent 看到这条消息(它在那个群里,而且有上下文权限),自动做了这么几件事:
它先回溯:上周这个功能有过一次发版,定位到具体的 PR #4823。
它再关联:监控里这个功能的 P99 确实从 800ms 涨到了 2.4s,涨幅时间点和发版时间吻合。
它再摘取:翻 PR #4823 的代码改动,识别出有一处批量查询的写法可能在大数据量场景下退化。
它再升级:在 oncall 频道里发了一条消息,@ 了原作者张三,@ 了 oncall 当班的李四,@ 了客户经理:“这个客户问题我已经定位,可能和 PR #4823 相关,涉及批量查询性能,建议升级为 P2。修复草案我贴在 PR 评论里了,请看一下。”
它最后兜底:在客户经理的私聊里回了一句:“问题已经定位并升级,预计 2 小时内给您回复修复方案,请稍等。”
这一切发生的时候,人还在喝早咖啡。
这一层和第二层的根本差异是什么?是 AI 从被动响应变成主动推进。 第二层的 AI 是“有问必答”型的客服;第三层的 AI 长出了职业本能,会自己识别风险、自己拉对应的人、自己找代码、自己起方案、自己向上报告进度。
注意这一步的关键:真正的跳变在于“AI 第一次表现出了职业判断”,而不是“AI 会写代码”。 它过去要培养一个工程师两三年才能形成的那种本能,什么事算紧急、什么事该先 @ 谁、什么时候该升级、什么时候该自己处理,AI 第一次有了这种东西。
我对这一层的评价就一个词:魔幻。
魔幻在哪儿?在于第二层之前所有 AI 行为都是“你按一下它动一下”。第三层之后,它开始有自发性。你早上打开 inbox 的时候,会发现里面有一半的事情是它已经替你把准备工作做完了的,你只是来按 yes 或 no、提供最终判断。
但它仍然有边界。它能起草方案,不能拍板;它能升级问题,不能决定优先级;它能 @ 人,但被 @ 的那个人,还得自己去理解上下文、做决策、改代码。
修代码这件事,在第三层依然回不到 AI 手里。AI 早就能写出能跑的代码,真正难的是它知道该修什么、从哪里取上下文、怎么验证修对了。代码本身是最简单的环节,知道“修什么、为什么修、修完了怎么知道好了”,才是工程的本体。这件事还要靠人。
第三层让 AI 长出了眼睛和嘴,但还没长出手。
第四层:Agent 全链路自治(我能想象,但还没看到)
第四层这件事我得诚实说:我们还在路上,而且很远。
第四层的样子是这样的:线上日志出现异常 → Agent 自动捕获 → 自动复现 → 自动定位代码 → 自动写修复 → 自动写测试 → 自动跑 CI → 自动提 PR → 走灰度 → 看 AB 数据 → 决定是否全量 → 全量后回归 → 关闭工单。
整条链路全可观测、可回溯、可回滚。出问题了你能立刻看到它在哪一步做了什么决策,也能把它任何一步拽回来重做。
这一层和第三层的根本差异是什么?是 AI 终于长出了“手”。 第三层的 AI 还是把球传给人,它定位、它起草、它升级,然后等人。第四层的 AI 自己接住了球,跑完整条赛道。它不只是“识别问题”,还“解决问题”。
但从 dev 跑通到敢上生产,中间有一组没解决的硬问题。
第一是回滚。 Agent 改错了怎么办?一次错误的发版可能意味着百万级的客户资损、监管层面的合规事件、舆情上的风险。这些东西在人写代码的世界里靠 SRE 经验、靠值班默契、靠“我赶紧回滚一下”这种人肉响应。在 Agent 世界里,你必须把这些经验全部写成显式的协议。什么样的指标变化触发自动回滚?多快算“快”?回滚后状态怎么对齐?对齐不了怎么办?
第二是责任归属。 Agent 上线了一个 bug 导致客户损失,谁担责?是审过 PR 的工程师?是部署 Agent 的团队?是公司?这个问题在受监管的场景下尤其要命,因为追溯会要落到具体责任人。监管不接受“AI 干的”这种回答。
我们部门内部为这件事开过一个会,讨论了三个小时,最后没结论。技术上没有任何障碍,组织上没有人愿意签那个名字。
第三是观察成本。 Agent 跑得越自动,人就越看不见它在干嘛。等你发现它在干蠢事的时候,可能已经干了一万次了。这意味着什么?意味着你可能某一天突然收到合规部的电话,告诉你 Agent 三个月前就在持续做一件违规的小事,只是直到今天才被发现。
我之前提过一个想法叫“日志驱动的自治修复闭环”,本质上就是第四层的样子,让生产环境的真实数据直接驱动 Agent 的工作流,人只在关键决策点出现。 但“关键决策点”在哪儿、怎么定义、谁来定义、出了问题谁来背,这些事我们自己也还在摸。
第五层:终极拷问
第五层其实不算一个新能力,更像是一组问题。
它问的是:你的整个企业架构,对 AI 友好吗?
这一层和前四层的根本差异是什么?前四层都是“我们怎么用 AI 干活”,第五层是“我们这家公司,有没有资格用 AI 干活”。
听起来夸张,其实非常具体。拆开来是这么几个拷问。
线上 bug 发生的时候,AI 能不能看到完整的发生过程? 日志、链路、用户行为、上下文,这些东西是埋好的吗?还是散落在七八个系统里,连人都拼不齐?(这就是我们卡在第二、三层之间的那道坎。)
需求来的时候,AI 能不能知道它的来源和背景? 是某个客户的具体场景,还是销售为了拿单临时承诺的,还是产品经理拍脑袋?是合规要求的、还是监管下达的、还是高层一句话?这些上下文有没有沉淀到一个 Agent 能读到的地方?还是只存在于某个总监的微信里?
该升级的问题能不能升级? Agent 有没有跨团队、跨权限、跨工具的“通行证”,还是每到一个边界就被卡住?在金字塔型的大组织里,这一条尤其难,一个权限要走五个审批节点,Agent 走一次要等三天。
代码文档是给 AI 写的吗? 注意这个问题问的是“给 AI 写”,不是“给后来的人写”。这两件事的标准非常不一样。给人看的文档允许模糊、允许默契、允许“懂的都懂”;给 AI 看的文档必须显式、必须自洽、必须把上下文写完整。那些祖传系统的文档,大部分对 AI 来说是天书。
说到底,第五层是组织问题,跟技术关系不大。
它意味着你公司的每一个流程、每一份文档、每一套权限、每一个工具,都要重新审视一遍:它对 AI 友好吗?如果不友好,前四层的能力都会在这里被打骨折。
我见过太多 AI 项目最后变成了“内部 demo”或者“试点试到没下文”:他们花了大力气把 Agent 的能力做起来,结果发现 Agent 跑不动。业务系统的日志结构是十年前的祖传代码、需求文档堆在三个不同的协作工具里、关键人的判断只存在于他自己脑子里、跨部门的权限要走三周流程才能开通。
Agent 站在那儿,什么都能干,但什么都干不了。
第五层之后:还需要公司这个东西吗?
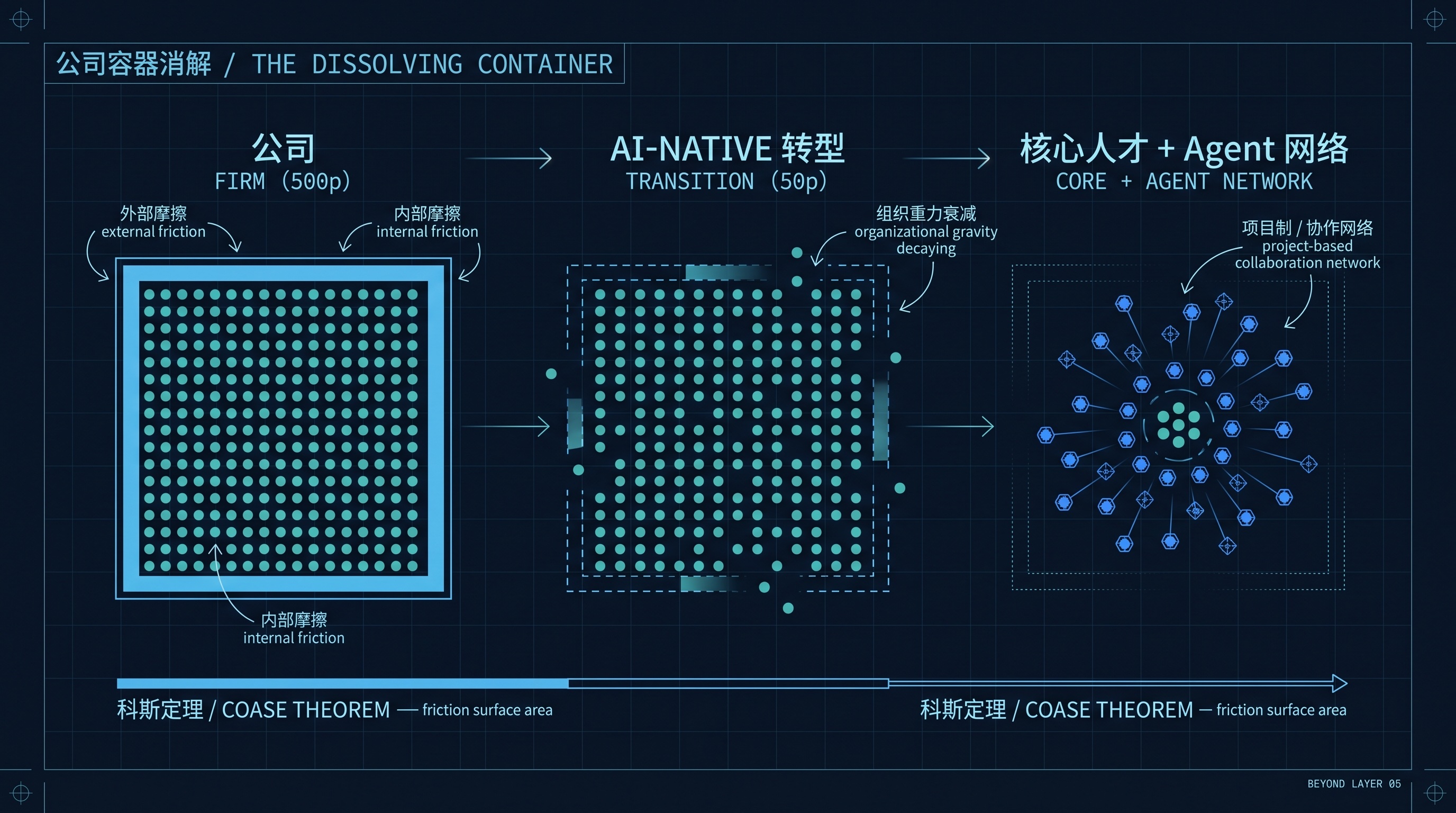
公司容器的消解:从金字塔到协作网络
第五层的拷问到这里其实还没完。如果你真的把组织改造成了“对 AI 友好”的形态,会发生一件比“提效”更深的事:这家公司的人员结构会被彻底重写。
我先抛一个判断:职能划分这件事,可能要从根上改写。
我们今天的公司架构,本质上沿用的是流水线时代的逻辑:把一件大事拆成无数小件,每个小件交给一个专门的人。装配工只负责装配,质检员只负责质检,采购员只负责采购,法务只看合同,合规只看合规,产品只画产品,研发只写代码。
为什么要这么分?因为人的带宽有限。 一个人脑子里能装的上下文是有上限的,精力也是有上限的。让一个人同时做装配、质检、采购,他三件事都做不好。所以越窄、越垂直,人的效率就越高。这是工业革命以来组织设计的第一原理。
但 AI 没有这个约束。
AI 可以并行十件你交给它的事情,不用担心精力问题。它的“带宽”几乎只取决于你给它的上下文够不够、规则定得清不清。这意味着,当一个人手里有了 AI,他能高效处理的事情,从一个窄方向变成了一片广阔区域。
过去要求“深度”,现在要求“广度”。
过去要的是一个领域里钻到底的专家。现在要的是 一专多强的复合型人才:一个对自己主战场理解透彻、同时能 hold 住相邻几个领域、能熟练用 AI 把这几个领域的活儿同时跑起来的人。
这件事对组织架构的冲击是颠覆性的。
人事、行政、采购,本质上都是处理事务流程的部门。在 AI-Native 的公司里,这三个部门可能合并成一个 5 人的“运营中台”,剩下的活儿全是 AI 在跑。
法务和风控,本质上都是在做合规判断和风险识别。这两个部门常常各有上百号人,但底层逻辑是同一套。AI-Native 之后,合并成一个团队没什么不可以。
产研团队最戏剧性。今天我们部门的产品经理、研发、测试、设计、运维,五条线五个 leader 五个汇报关系。你真的把第三、第四层的 AI 跑起来,大量“对齐成本”消失了:产品脑子里的需求可以被 AI 直接翻译成代码草稿,研发改的代码可以被 AI 自动生成测试,测试出的问题可以被 AI 自动定位回需求源头。五条线变成一个“产研一体”的小团队,完全可以做到。
最戏剧性的是:大多数公司其实不需要那么多“科学家”型的专家。深度专业能力依然有价值,但需求量会大幅缩减。一家中型业务线过去需要三十个深度专家,未来可能只需要五个真正顶尖的专家加一群有“广度+AI 杠杆”的复合型人才。
写到这里我必须诚实承认:这件事不会一夜发生。组织重力太大了,流程惯性太重了。但方向是清楚的。未来五年内,你会看到组织架构图变得越来越扁,职能边界变得越来越模糊,岗位描述里“会用 AI 杠杆放大产出”会成为隐含必备项。
这个转变到这里还没结束。再往前推一步,会出现一个更尖锐的问题。
公司本身,还是必要的吗?
经济学里有一个经典的解释,叫“科斯定理”:公司之所以存在,是为了减少一群人在社会上协作时产生的交易摩擦。
意思是,如果你想造一辆车,理论上你可以临时找市场上 100 个独立工人,每个人按合同帮你做一部分。但实际上你不会这么干,因为找 100 个人、签 100 份合同、协调 100 个人的进度、处理 100 次扯皮,这个交易成本高得离谱。所以你成立一家公司,把这 100 个人雇下来,用内部管理代替市场交易,把那些摩擦“内化”了。
公司,本质上是一个降低摩擦的容器。
但如果 AI-Native 真的把组织极度精简了,一个原本 500 人的业务线,变成 50 人的复合团队加一群 Agent,会发生什么?
500 人和社会的摩擦面是巨大的:招聘、培训、绩效、晋升、办公室政治、跨部门协调、合规审计、文化建设。这些“内部摩擦”本身就是巨大的成本,公司这个容器之所以值得存在,是因为它降低的“外部摩擦”比制造的“内部摩擦”更大。
50 人的摩擦面骤然缩小。10 人甚至 1 人的“公司”呢?
当一群人变成一小撮人,这一小撮人和社会之间的摩擦从一片火变成了星星之火。 这个时候,“公司”作为一个降低摩擦的容器,价值在快速衰减。
那 AI-Native 的极致形态,是什么?
可能是一种我们今天还没完全看清楚的形态:少数核心人才,加上一群可调度的 AI Agent,以“项目制”或“协作网络”的形式直接对接市场。 没有金字塔,没有部门,没有那些为了协调几百人而存在的中间层。
听起来像是科幻。但你回过头看每一层的演进:AI 替你写代码,AI 进流程,AI 识别风险,AI 闭环,AI-friendly 组织。每一层都在剥离一些“为了协调一群人”才存在的东西。剥到第五层之后,继续剥下去,你剥的就是公司本身。
我不知道我们这一代人会不会真的看到那一天。但我已经能感觉到方向在哪了。
在一个几千人的组织里推 AI-Native,每往前走一步,都会有一个声音在我脑子里响起来:你正在帮公司变得更高效,还是正在让公司变得更不必要?
这个问题没有答案。我也不打算给一个。但每一个走在 AI-Native 路上的人,迟早要直面它。
写在地图边上
回头看,从第一层到第五层再到那个没编号的拷问,真正在变的是问题的形状,跟技术演进关系不大。
第一层问的是“AI 能不能写代码”;第二层问的是“AI 能不能进流程”;第三层问的是“AI 能不能识别风险”;第四层问的是“AI 能不能闭环”;第五层问的是“组织能不能让 AI 闭环”;第五层之后是“等组织真的变了,公司这个东西还需要存在吗”。
前四层,是单一职能就能推动的事情。第五层不是。第五层要拉上 CEO、CTO、HR、法务、合规、财务一起改造,要重新写流程文档、重新切权限、重新定 KPI、重新定岗位。这件事大部分会被拖,因为又难又看不到短期收益,而且每一次改动都涉及到几十个人的部门利益。
第五层之后那个问题呢?它已经超出了任何单一岗位的职权,也超出了 CEO 一个人能拍板的范围。这是这家公司、这个行业、乃至这一代人要共同面对的问题。
但拖不起。AI-Native 的窗口不会一直开着。当你的对手在第三、第四层稳定运行的时候,你还在第二层加人手填会议纪要,这中间隔的是组织代差,跟技术差距没多大关系。再往前看,当你的对手已经开始重画职能、合并部门、把组织架构图变扁的时候,你还在守着传统的金字塔,这中间隔的就不只是组织代差了,是物种代差。
写到这里我自己也清楚:这张地图画完了不等于路就好走。我们团队就是个例子,第二层的甜头吃到了,被一道叫“上下文”的坎卡了两个季度,dev 里勉强跑通了第三层的雏形,第四层只敢在脑子里推演,第五层的每一个问题都在啃,第五层之后那个问题更是连边都还没摸到。
如果说这张地图能给走在同一段路上的人留下什么,大概只有一句:别等“AI 真的成熟了”再动。等的人不会赢,边走边修地图的人才会。 这句话对组织重力大、流程沉的环境尤其重要,这里的每一步都比小团队慢三倍。你越早动,越早把那些“十年前就该解决”的旧账翻出来还清,在窗口关闭前才有可能站到第三层、第四层的位置上。
每天早上的那 40 分钟批处理,看起来是新工作模式带来的,其实是新组织形态在催着我做出选择。
我每次合上电脑去开会,都会想一个问题:我在管那群机器下属上花的时间,会不会有一天超过我管人的时间?如果会,那我们这家公司的样子,就要重画了。
更深一层的问题是:那张被重画的图,可能压根就不再是“一家公司”。