被卡脖子的 AI 芯片层,正在发生三件没人说的事
被卡脖子的 AI 芯片层,正在发生三件没人说的事
三面墙、三条绕路、一个所有人忽略的新变量。芯片层的故事,"卡脖子"三个字装不下。
一笔让我重新审视芯片层的交易
昨天 AMD 宣布了一笔交易:和 Meta 签了一份多年期协议,部署定制版 AMD GPU 和 CPU,为 Meta 下一代 AI 数据中心供电。
规模是 6 个吉瓦的电力容量——大约相当于 600 万户家庭的用电量——全部用于 AMD 芯片。路透社估算合同价值约 600 亿美元。
这是 Meta 在 NVIDIA 之外押注第二个芯片供应商。就在一周前,Meta 刚和 NVIDIA 签了部署数百万颗 GPU 的协议。现在又锁定了 6 吉瓦的 AMD 产能。Meta 今年的资本开支指引是 1150-1350 亿美元,它有能力同时养两个供应商。
同一天,NVIDIA 发布了 Q4 财报,季度收入 861.3 亿美元,较去年同期成长73%,而且远高于分析师预测的657亿美元。依然是怪物级别的数字。但市场的注意力已经不只在 NVIDIA 身上了。
TrendForce 的数据显示:2026 年,云厂商自研 ASIC 芯片的出货增速预计达到 44.6%,而 GPU 的增速是 16.1%。
拐点已经出现了。
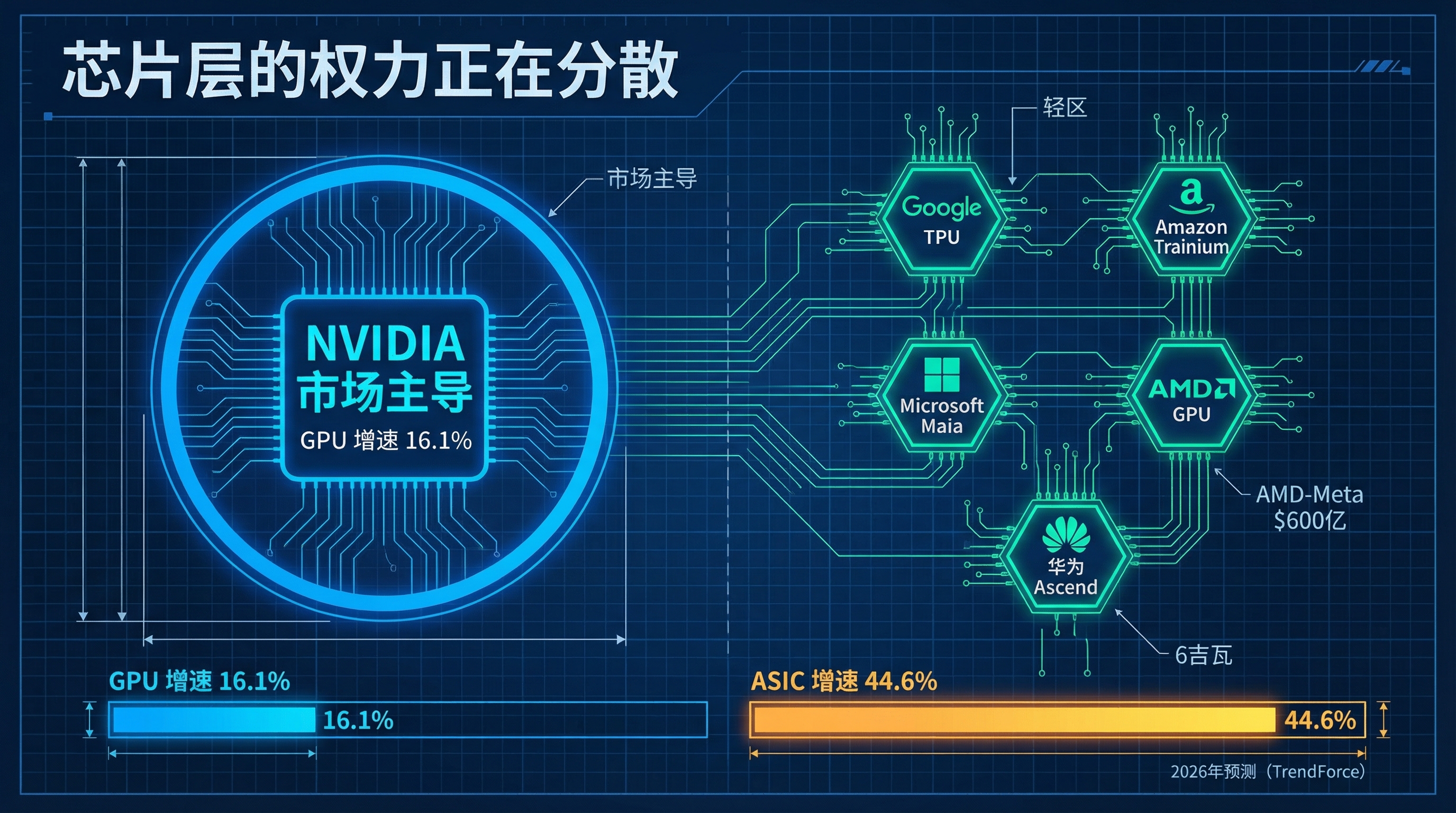
AI芯片市场格局转变:GPU增速16.1% vs ASIC增速44.6%,从NVIDIA一家独大走向多元竞争
黄仁勋的五层蛋糕
去年底,黄仁勋在华盛顿 CSIS 的一场对谈中提出了一个框架:AI 产业是一个五层蛋糕。
从底到顶:能源、芯片与计算基础设施、云基础设施与云服务、AI 模型、应用。
他做了一件很有意思的事——逐层给中美两国打分。在能源层,他直接说"中国的能源储量是美国的两倍"。在芯片层,他的判断则是美国占据绝对优势。
我前面几篇文章一直在聊第一层——电力。核心判断是:Token 的边际成本最终回归电费,电力是 AI 竞争中最不可蒸馏的变量。
现在往上走一层。
芯片层是五层蛋糕里中国看起来被卡得最死的一层。EUV 光刻机买不到,台积电最先进制程用不上,CUDA 软件生态绕不开。三面墙,看起来密不透风。
但最近半年,我越来越觉得这个判断需要修正。并不是墙不在了,而是墙的位置在变。
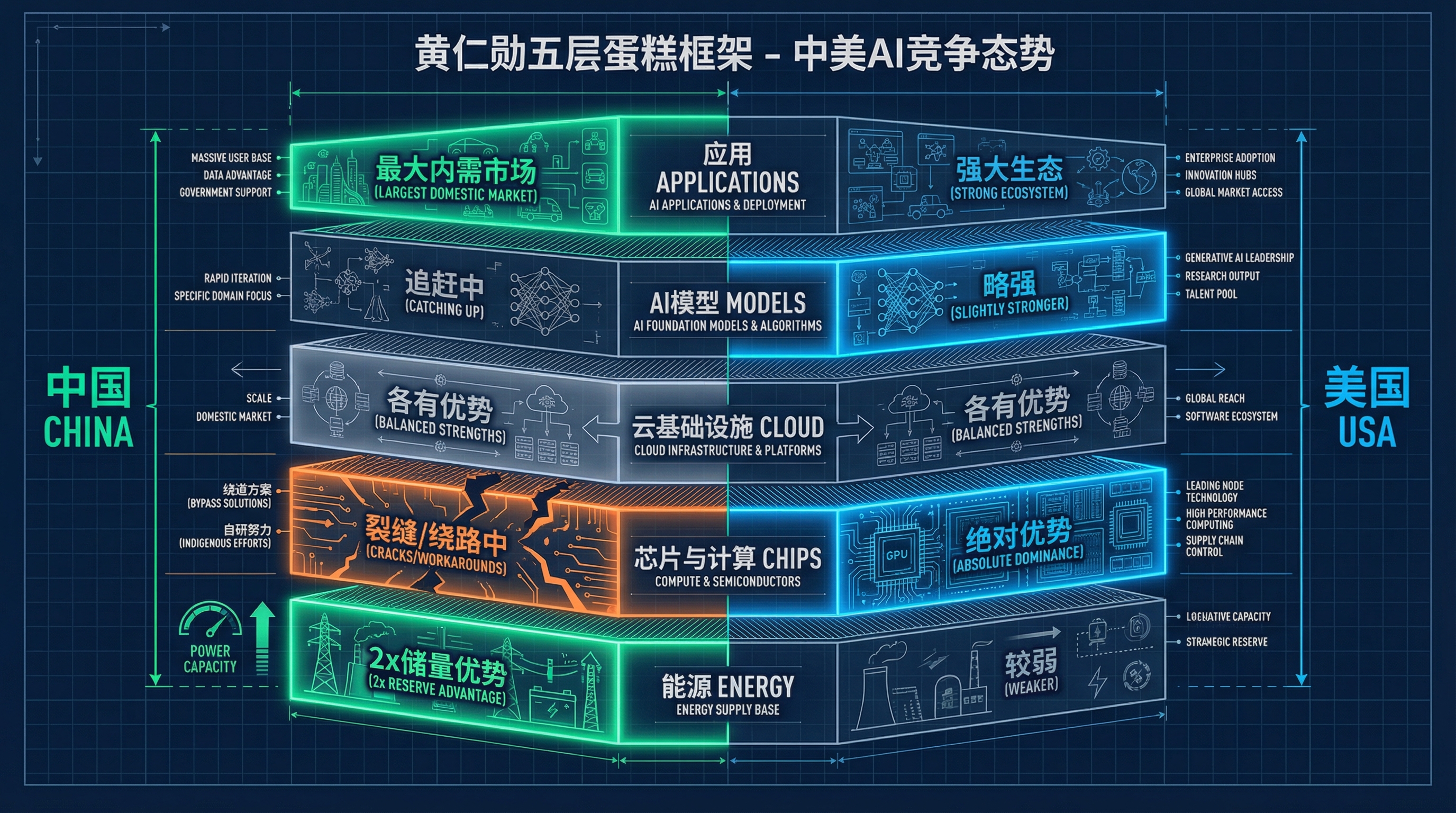
黄仁勋五层蛋糕框架:中美AI竞争各层态势对比
芯片层的权力正在分散
先看全球趋势。
AMD-Meta 的 600 亿美元交易只是一个信号。更大的趋势是:AI 芯片正在从"NVIDIA 一家独大"走向"多元竞争"。
Google 有 TPU,已经用自研芯片训练 Gemini,不依赖 NVIDIA 硬件。Amazon 有 Trainium 和 Inferentia。Microsoft 在做 Maia。OpenAI 和 Broadcom 合作设计自研芯片,计划 2026 年量产。华为有 Ascend 系列和达芬奇架构。
每一家超大规模厂商都在做同一件事:减少对 NVIDIA 的单一依赖。
这个趋势的底层逻辑是什么?
AI 芯片正在经历和计算机行业一样的"通用→专用"转变。
GPU 本质上是一个通用并行计算器。它什么都能算,但什么都不是最优的——为了兼容图形渲染和其他通用计算,GPU 保留了大量 AI 不需要的电路。当 AI 推理占总计算量的比重越来越高,为推理场景定制的 ASIC 就越来越有吸引力:更高效、更省电、更便宜。
这和我第二篇写 Taalas 的逻辑一脉相承:当一个计算模式足够稳定,它最终会从通用硬件沉降到专用硬件。 Taalas 是极端版本(整个模型刻进芯片),ASIC 是温和版本(为特定计算模式设计芯片),但方向是同一个。
三面墙
芯片层的全球趋势是分散化和专用化。但对中国来说,这个趋势叠加了一个独特的约束条件:制裁。
第一面墙:光刻机。 ASML 的 EUV 光刻机是制造 7nm 以下芯片的关键设备,中国买不到。这意味着中国无法在单芯片层面追上最先进制程。NVIDIA 的 Blackwell 用的是台积电 4nm,华为被限制在 7nm 左右。单论晶体管密度,这是一个代际差距。
第二面墙:代工。 即使中国能设计出先进芯片,制造也要依赖台积电或三星。台积电的 CoWoS 先进封装产能 2026 年预计 100 万片晶圆,绝大部分已被 NVIDIA、AMD、Apple 等锁定。中国芯片公司很难拿到产能。
第三面墙:软件生态。 NVIDIA 的 CUDA 生态经过 17 年的积累,几乎所有 AI 框架(PyTorch、TensorFlow)都针对 CUDA 深度优化。AMD 的 ROCm 至今仍在追赶。对中国来说,CUDA 既是技术锁定也是生态锁定——即使硬件追上了,软件开发者也习惯了在 CUDA 上写代码。
三面墙,看起来密不透风。
但我最近注意到的一些动向,让我觉得中国半导体行业并没有在正面硬撞这三面墙。它在绕。
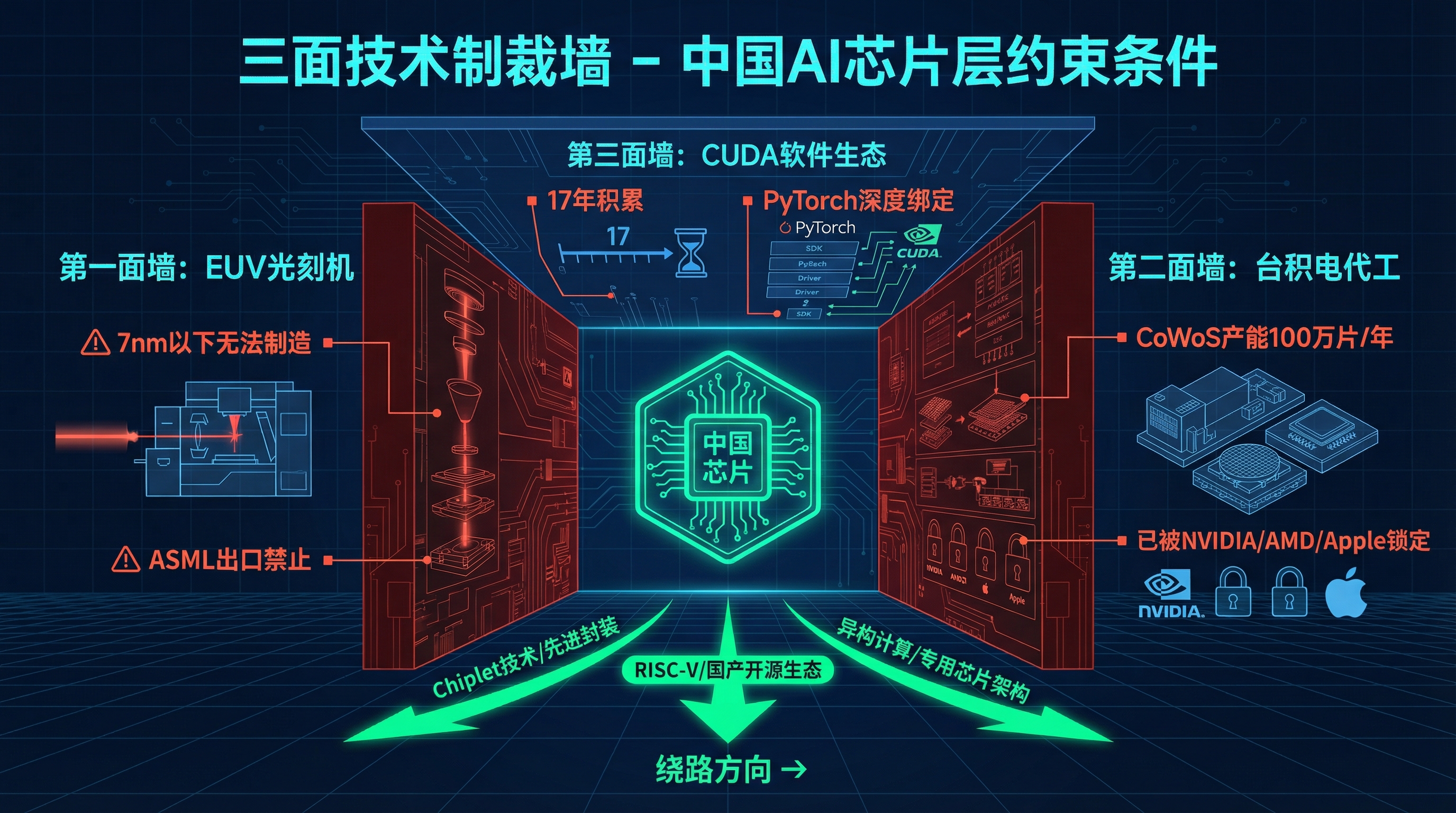
三面技术制裁墙:EUV光刻机、台积电代工产能、CUDA软件生态
绕路一:搭乐高
既然在指甲盖大小的硅片上刻不出 3nm 电路,那换一种思路:用成熟工艺(7nm 甚至 14nm)造出多个小芯片,然后像搭乐高积木一样,通过先进封装技术把它们"粘"在一起。
这个路径叫 Chiplets(芯粒)。业界称之为 More than Moore——不追求摩尔定律的纵向微缩,而是通过横向拼接来获取性能。
核心逻辑是:竞争的焦点从"光刻精度"转向"互联密度"。 只要封装技术(2.5D/3D Bonding)足够好,多个 7nm 芯片组合后的整体性能可以逼近单颗 5nm 或 3nm 芯片。
这正是中国半导体产业目前投入最疯狂的领域。长电科技、通富微电这些本土封装巨头在全力攻克类 CoWoS 的 2.5D/3D 封装技术。华为的 Ascend 910B 和传闻中的 910C,很大程度上就依赖这种"以面积换性能"的策略。
一个有意思的细节:CoWoS 的产能瓶颈其实说明了一件事——即使是 NVIDIA 和 AMD,也在受封装产能的制约。 2026 年全球 100 万片 CoWoS 晶圆需求,供不应求。这意味着先进封装不仅仅是中国的专属困境,而是全行业的瓶颈。
谁先解决封装问题,谁就在芯片层获得一个不对称优势——不是因为你的单芯片更强,而是因为你能把更多芯片更高效地组合在一起。
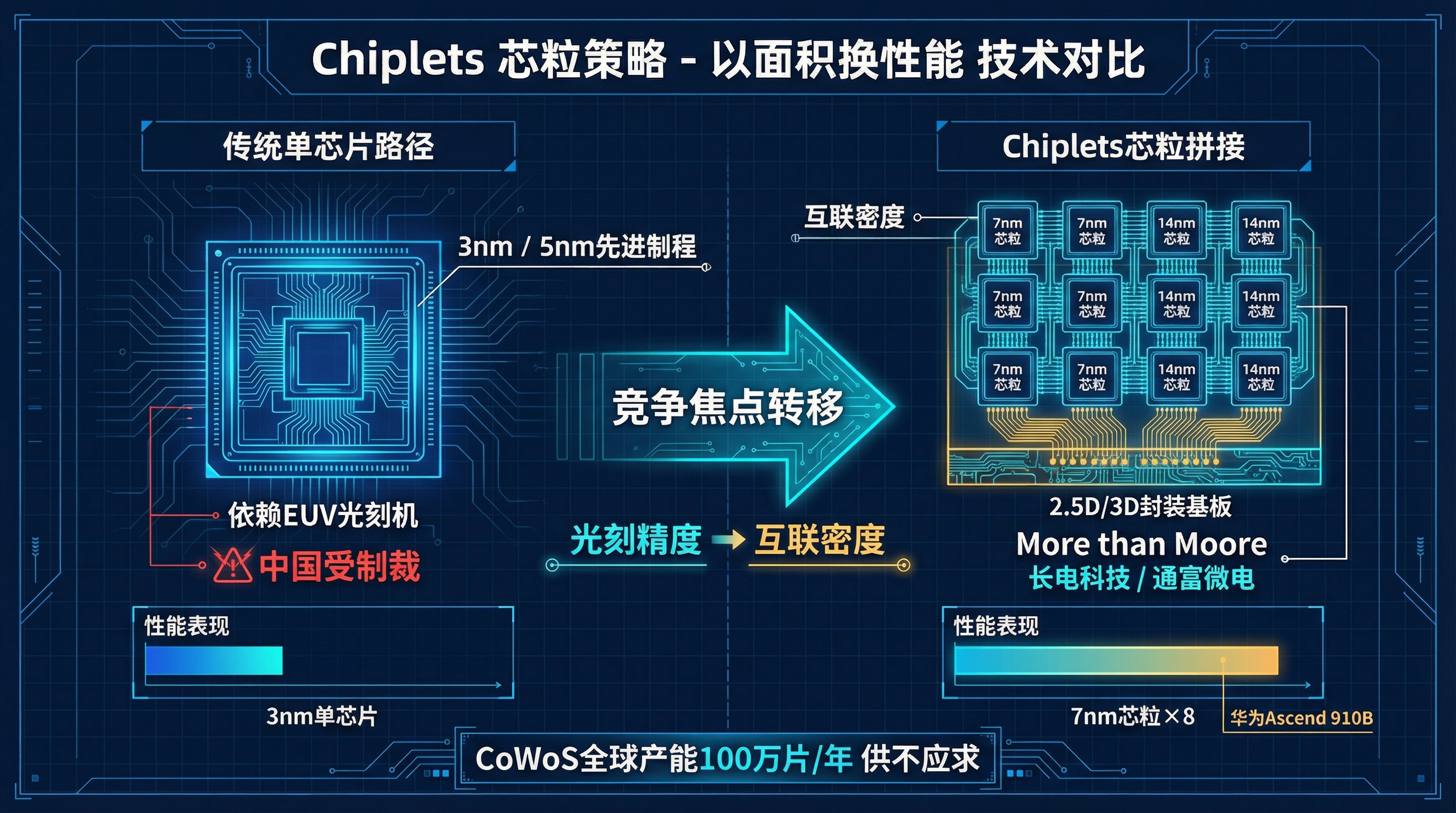
Chiplets芯粒策略:以面积换性能,竞争焦点从光刻精度转向互联密度
绕路二:光进铜退
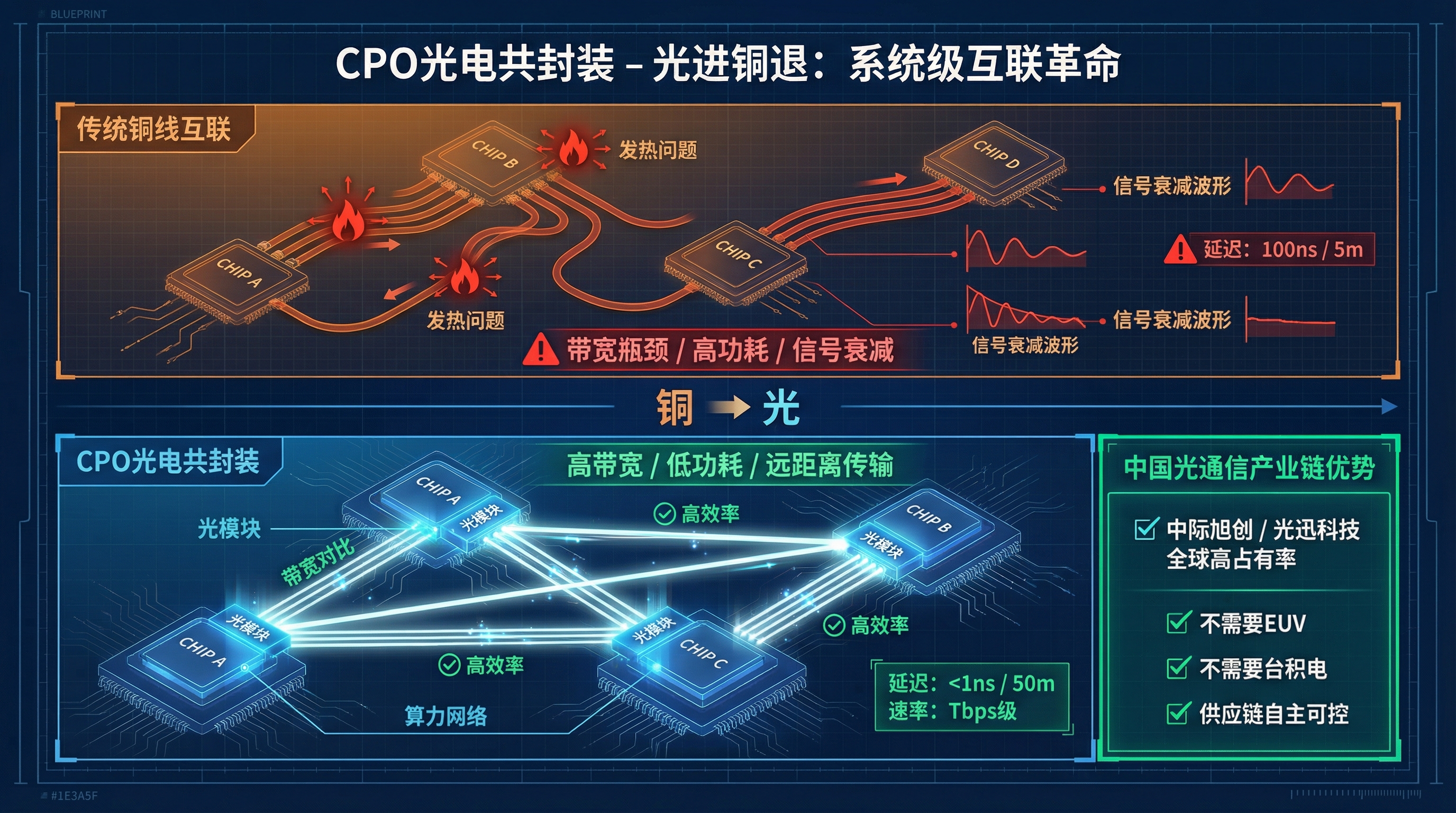
Chiplets 解决了"造不出最强单芯片"的问题,但引入了一个新问题:芯片堆多了,它们之间怎么通讯?
传统方案是铜线互联。但当你把几十甚至上百个小芯片封装在一起,铜线的带宽和功耗就撞墙了。信号衰减、发热、延迟——铜线在高密度互联场景下正在接近物理极限。
绕路的方案是 CPO——Co-Packaged Optics,光电共封装。把光模块直接封装在芯片旁边,甚至芯片内部,用光子代替电子来传输信号。
光子的优势在于:带宽更高、功耗更低、距离更远。 在数据中心内部,如果芯片之间的通讯从电信号切换到光信号,整个系统的互联效率会上一个台阶。
这里藏着一个中国的结构性优势。
中国在全球光通信产业链上的地位,远比芯片制造强得多。中际旭创、光迅科技这些企业在全球光模块市场上占有率极高。光模块的制造不需要 EUV,不需要台积电,中国的供应链完全自主可控。
如果 AI 计算基础设施的瓶颈从"单芯片性能"转向"系统级互联效率",那中国在光通信上的产业链优势就可以转化为芯片层的竞争力。 这是一条用自己的长板弥补短板的路径。
更大的图景是:中国提出的"算力网络"战略,本质上就是把分散在全国各地的数据中心通过高速光网络连接起来,让整个网络变成一台超级计算机。单个节点的芯片可能不是最强的,但节点之间的互联如果足够快,整体算力可以超过由最强单芯片组成的孤立集群。
CPO光电共封装:从铜线到光子互联,中国光通信产业链优势转化为芯片层竞争力
绕路三:不玩 CUDA 的游戏
前两条路解决的是硬件问题。但 NVIDIA 最深的护城河不是硬件——是 CUDA。
CUDA 用 17 年建立了一个开发者生态。全球绝大多数 AI 研究者和工程师写代码时默认使用 CUDA。PyTorch 对 CUDA 的支持远比对任何替代方案的支持成熟。这是一个典型的生态锁定:不是因为 CUDA 技术上不可替代,而是因为迁移成本太高。
中国的绕路策略不是在 CUDA 生态内追赶(AMD 的 ROCm 已经证明这条路有多难),而是在 CUDA 之外建一个平行生态。
华为的 CANN 框架配合达芬奇架构,百度的 PaddlePaddle 深度学习框架,加上中国庞大的内需市场(互联网大厂、政务云、央企数字化)——行政力量和市场规模结合,强行"堆"出一个不依赖 CUDA 的生态。
这条路很像当年 Android 对 iOS 做的事情。Android 从来没有在单设备体验上超过 iOS,但它用开放性和市场规模建立了一个平行生态,最终全球市占率远超 iOS。
华为最近的动作也在印证这一点。Ascend 芯片配合 UB 2.0 互联协议(对标 NVIDIA 的 NVLink),并且宣布向合作伙伴开放。阿里牵头成立 ALS 联盟(对标 AMD 的 UALink)。这些都是在构建一个不以 NVIDIA 为中心的生态系统。
NVIDIA 的 NVLink Fusion 策略——把 NVLink 接口作为 IP 授权给客户——恰恰说明 NVIDIA 也感受到了生态分裂的压力。 它在用"开放一点硬件接口,换取绑定更多客户到 CUDA 生态"的策略来对抗分散化。
生态战争不像芯片性能竞赛那样有一个清晰的胜负标准。它的结局更可能是"两个平行世界"——CUDA 生态和非 CUDA 生态长期共存,各自服务不同的市场。对中国来说,关键不是打败 CUDA,而是确保国产生态能自立运转。
但这里我必须说一个让我不太舒服的对冲观点。
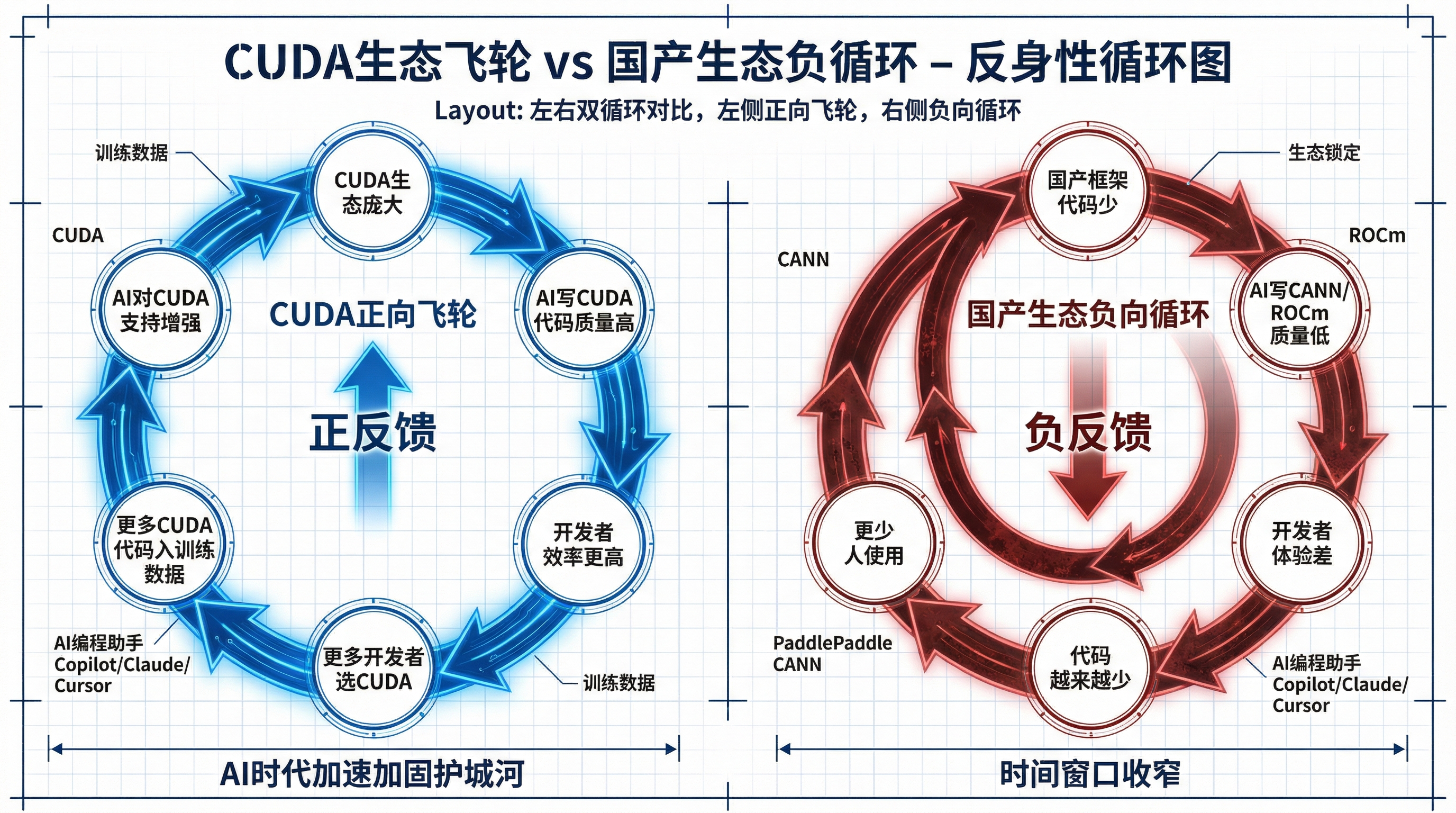
AI 正在加速生态锁定,而不是打破它。
想想 AI 编程助手——Copilot、Claude、Cursor——它们是用什么训练的?GitHub 上的代码、Stack Overflow 的问答、技术文档。这些训练数据里,CUDA 代码的数量和质量远远超过 ROCm、CANN 或任何替代框架。
结果是:AI 写 CUDA 代码写得非常好,写国产框架的代码写得很一般。
这就形成了一个反身性循环:CUDA 生态越大 → AI 对 CUDA 的支持越好 → 开发者用 AI 辅助编程时选择 CUDA 效率更高 → 更多人选择 CUDA → 产生更多 CUDA 代码进入训练数据 → AI 对 CUDA 的支持进一步增强。
AI 不是一个中立的工具。它会放大既有生态的优势。
输入越标准化,AI 的输出质量越高。CUDA 是当前最"标准"的 AI 编程接口,所以 AI 对 CUDA 的加持最大。这意味着 CUDA 的护城河不是在被 AI 时代侵蚀——它在被 AI 时代加固。
对国产生态来说,这个反身性的含义很严峻:开发者体验的差距不只是当前状态的问题,它可能在 AI 辅助编程时代被加速拉大。CANN 上的代码越少,AI 写 CANN 代码的能力越差,开发者越不愿意用 CANN,CANN 上的代码就越少。
国产生态的时间窗口可能比想象中更窄。 如果不能在 AI 编程助手全面普及之前积累足够的代码量和开发者社区,这个正反馈循环会让追赶变得越来越困难。
Android 当年面对 iOS 时没有这个问题——那个时代还没有 AI 编程助手来放大生态差距。中国的芯片生态战争,面对的是一个前人没有遇到过的新变量。
CUDA生态飞轮 vs 国产生态负循环:AI正在加速加固既有生态的护城河
一个更大的赌注
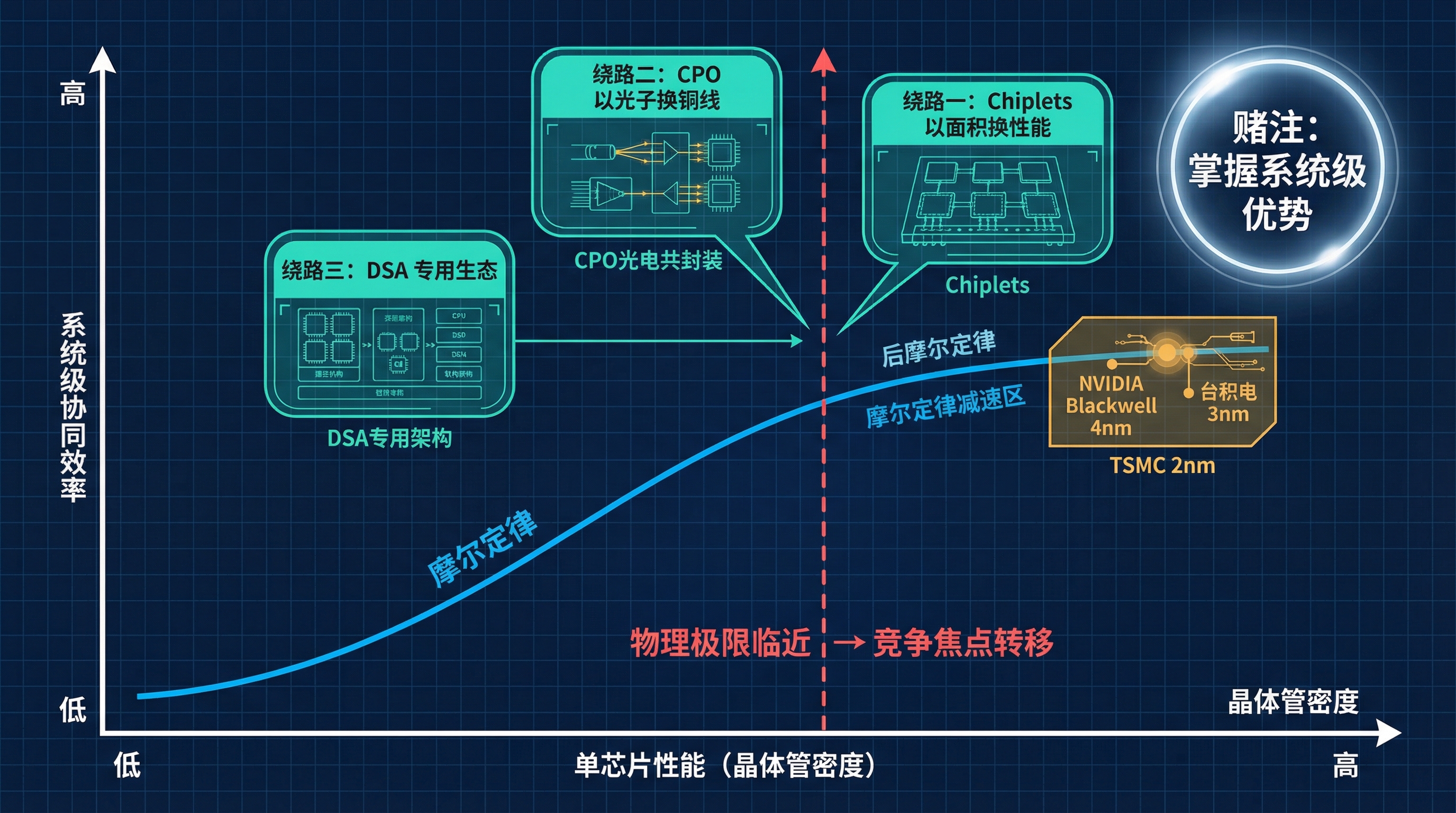
三条绕路放在一起看——Chiplets 以面积换性能,CPO 以光子换铜线,DSA 以专用换通用——它们有一个共同的底层逻辑:
把竞争的维度从"单芯片的晶体管密度"拉到"系统级的协同效率"。
这是一个赌注。
风险很明确。功耗会很大——多芯片封装的总功耗必然高于单颗先进制程芯片。良率初期会很低——2.5D/3D 封装的工艺成熟度远不如传统封装。生态孤岛的风险——如果国产框架的开发者体验和 CUDA 差距太大,开发者会用脚投票。
但机会也在这里。
摩尔定律正在减速。从 7nm 到 5nm 到 3nm,每一代的性能提升越来越小,成本越来越高,物理极限越来越近。TSMC 的 2nm 可能是传统光刻微缩的最后几代之一。
如果物理极限真的到来——晶体管密度不再是决定性变量——那"系统级互联"能力就会取代"先进制程"成为新的竞争焦点。
率先掌握了 Chiplets + CPO + DSA 这套组合拳的一方,在后摩尔定律时代可能不是追赶者,而是定义规则的人。
这当然是一个很大的"如果"。我不确定这个拐点什么时候来,也不确定中国的封装技术能不能在那之前成熟。但方向是清楚的。
后摩尔定律战略框架:三条绕路把竞争维度从单芯片密度拉到系统级协同效率
回到五层蛋糕
写到这里,我想起黄仁勋在 CSIS 那场对谈里说的一句话:任何一层的优势或短板,都会沿着链条向上传导。
芯片层是第二层。它上面还有三层:云基础设施、模型、应用。
单看芯片层,中国确实是劣势。三面墙都在,绕路的每一条都有风险。
但放在五层结构里看,结论可能不一样。
第一层——电力——中国有明确优势,而且这个优势不可蒸馏,前几篇已经分析过了。第二层——芯片——中国在绕路,方向清晰但结果未定。第三层往上——云基础设施、模型、应用——中国有全球最大的应用市场和互联网基础设施。
一个五层蛋糕,底层最厚实(电力),中间有裂缝(芯片),上面几层有自己的优势。
这到底是一个致命弱点,还是一个可以被上下层弥补的瓶颈?
下一篇,往上再走一层。