DeepSeek 们蒸馏了 Claude,然后呢?
DeepSeek 们蒸馏了 Claude,然后呢?
Anthropic 今天指控三家中国公司蒸馏了 Claude。但我看完博客后想的不是"谁对谁错",而是一个更大的问题。
今天发生了什么
2 月 24 日,Anthropic 发了一篇博客,指控三家中国 AI 公司——DeepSeek、Moonshot(Kimi)和 MiniMax——通过大规模蒸馏行为提取 Claude 的能力。
蒸馏本身是一种正常的技术手段,前沿实验室自己也在用——把大模型的能力"蒸"到小模型里,降低成本。但 Anthropic 说的不是这种。他们描述的是一种工业级别的、有组织的能力提取行动。
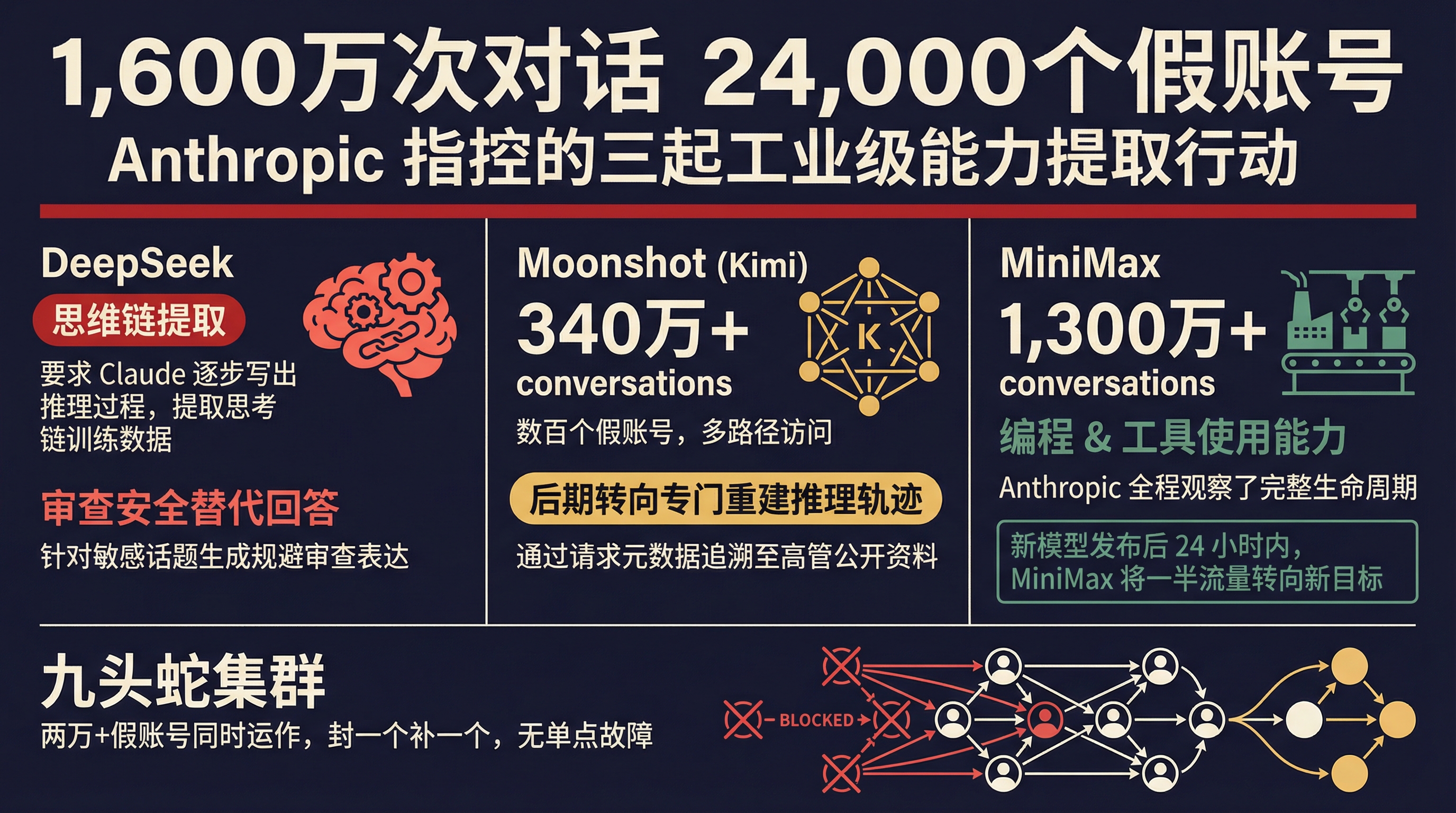
数字很惊人:超过 1600 万次对话,大约 24000 个假账号,通过代理服务绕过 Anthropic 对中国的访问限制。
蒸馏行为是否违法、是否道德,不是这篇想讨论的。但 Anthropic 博客里有一些细节,值得仔细看。
一场精心设计的能力提取
三家公司的操作方式各有特点,但都指向同一个目标:定向提取 Claude 最强的能力。
DeepSeek 的做法最有意思。他们的一部分 prompt 要求 Claude "想象并说出完成某个回答背后的内部推理过程,逐步写出来"——这本质上是在让 Claude 自己生成思维链训练数据。不是提取答案,是提取思考过程。另外,他们还让 Claude 生成"审查安全的替代回答"——针对涉及异见人士、领导人、威权主义等敏感话题的提问,让 Claude 写出规避审查的表达方式。这部分大概率是用来训练 DeepSeek 自己模型的内容安全系统。
Moonshot(Kimi)的规模更大,超过 340 万次对话,使用了几百个假账号覆盖多种访问路径。Anthropic 通过请求元数据追溯到了 Moonshot 高管的公开资料。后期 Moonshot 的策略变得更有针对性——从泛化提取转向专门重建 Claude 的推理轨迹。
但最让我停下来的是 MiniMax 的案例。
MiniMax 的规模最大——超过 1300 万次对话,主要针对编程和工具使用能力。Anthropic 说他们在蒸馏还在进行的时候就发现了,而且是在 MiniMax 发布目标模型之前。这意味着 Anthropic 完整观察了一次蒸馏操作的生命周期:从数据生成到模型训练到产品发布。
更有意思的是时间线:当 Anthropic 在 MiniMax 蒸馏期间发布了一个新模型,MiniMax 在 24 小时内就把将近一半的流量转向了新模型。这个反应速度说明什么?说明对方有一套成熟的、随时可以调整目标的基础设施。这不是几个工程师偷偷摸摸干的事,这是一条生产线。
Anthropic 还描述了这些操作使用的代理网络——他们称之为"九头蛇集群"。一个代理网络同时管理超过两万个假账号,把蒸馏流量和普通用户请求混在一起,让检测变得更困难。封掉一个账号,马上有新的补上。没有单点故障。
读完这些细节,我脑子里浮现的不是"谁对谁错",而是一个结构性的画面。
工业级蒸馏攻击规模:三家公司数据对比
我之前写过两篇关于 AI 和电力的文章。第一篇讲电力出不了国但 Token 可以,第二篇讲算力沉降为硬件后 Token 的成本只剩电费。今天这篇博客让我看到了同一条线的另一面。
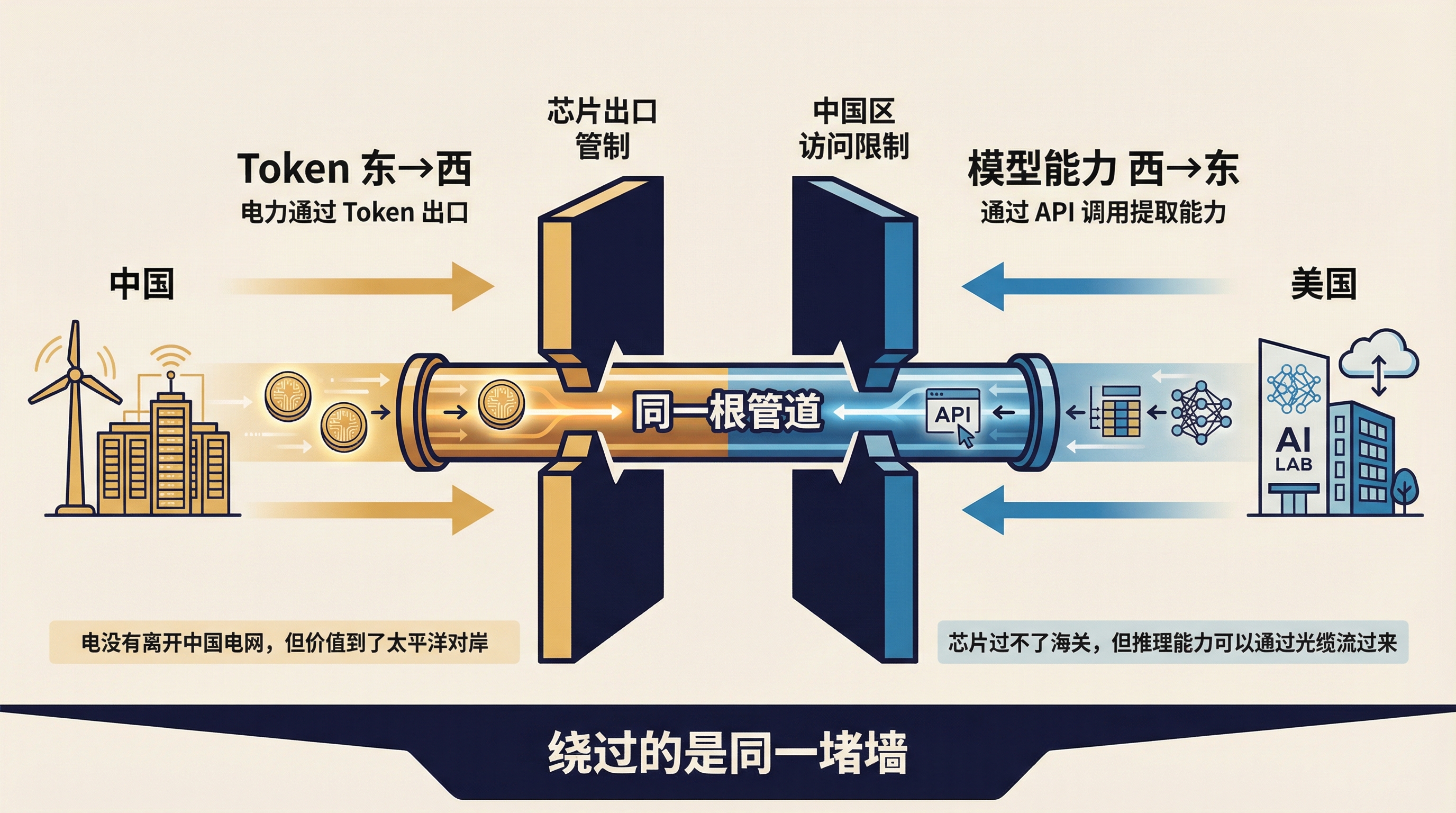
同一条光缆,两个方向
我在第一篇里写过:中国的电力成本优势被锁在国境线内,直到 Token 出现。电力通过 Token 这个载体,经海底光缆完成了跨境交付。电没有离开中国的电网,但它的价值到了太平洋对岸。
Anthropic 这篇博客描述的,是同一条光缆上的反向流动。
美国对中国实施了芯片出口管制,试图限制中国获取先进 AI 算力。Anthropic 对中国区关闭了商业访问。但模型的能力不是芯片——它可以通过 API 调用流过来。1600 万次对话,每一次都是一小块 Claude 的能力被提取、被记录、被用来训练本地模型。
芯片过不了海关,但推理能力可以通过光缆流过来。
Token 从东往西流,是电力变现。模型能力从西往东流,是知识蒸馏。两个方向,同一根管道,绕过的是同一堵墙。
同一条光缆,两个方向:Token 东→西与模型能力西→东
出口管制的逻辑是:控制硬件(芯片),就能控制能力(模型)。蒸馏绕过了这个链条——不需要你的芯片,只需要你的模型输出,就能复制你的能力。Anthropic 在博客里也说了一句很值得注意的话:如果没有对蒸馏行为的了解,这些实验室的快速进步会被错误地当作出口管制无效的证据。
换句话说,看起来是"创新追赶"的部分,实际上有一部分是"能力提取"。
唱片、Napster、和一个还没到来的 Spotify
这个困境让我想到了音乐产业二十年前经历的事情。
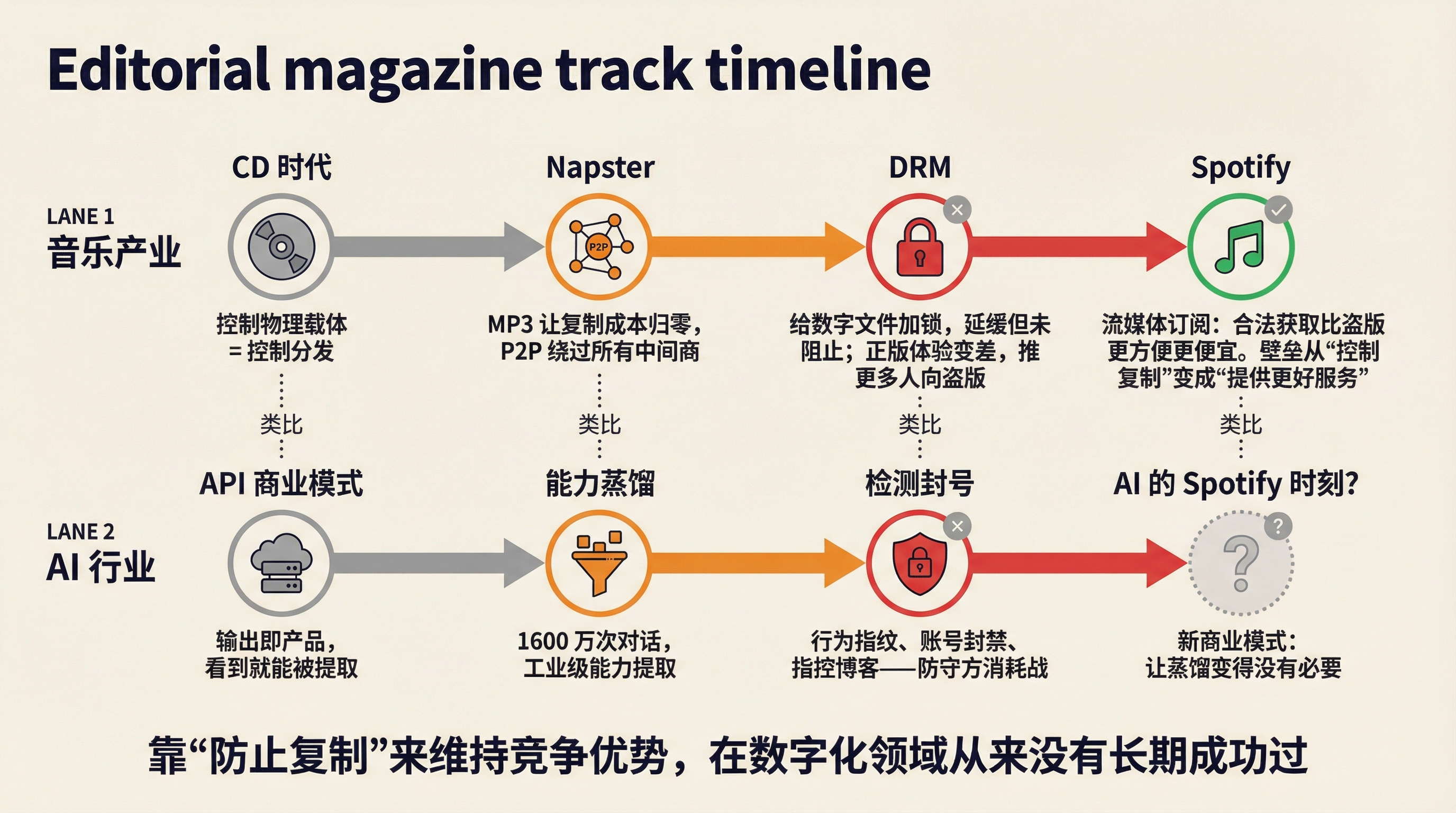
CD 时代,唱片公司的商业模式很简单:音乐封装在物理载体里,控制载体就控制了分发。你想听歌,就得买碟。
然后 Napster 来了。MP3 让复制成本降到零,P2P 让分发绕过了所有中间商。唱片公司做了什么?打官司,关 Napster,推 DRM(数字版权管理)——在数字文件上加锁,试图在数字形态里重建物理屏障。
DRM 有用吗?短期有一点。长期来看,它只是在延缓而不是阻止流失。每一代 DRM 都会被破解,而且 DRM 让正版用户的体验变差(不能跨设备播放、不能离线听),反而把更多人推向盗版。
最终解决问题的不是更好的锁,而是一个全新的商业模式——Spotify。当流媒体订阅让合法获取音乐比盗版更方便、更便宜的时候,大部分人就不费那个劲去下载了。唱片公司的壁垒从"控制复制"变成了"提供更好的服务"。
音乐产业与 AI 行业的双轨时间线类比
现在回头看 Anthropic 的处境。
他们的检测系统、行为指纹、账号封禁——这些都是 DRM。必要的、合理的、但从结构上注定是防守方的消耗战。因为任何通过 API 提供服务的模型,都面临一个根本矛盾:你必须让用户看到模型的输出才能收费,但用户看到输出的那一刻,输出就可以被记录和利用。
这和 CD 时代的矛盾一样:你必须让用户听到音乐才能卖钱,但用户听到的那一刻,音乐就可以被录制和传播。
AI 行业的"Spotify 时刻"是什么?我还不确定。也许是某种让蒸馏变得没有必要的商业模式——比如模型能力不再按输出收费,而是按运行环境收费(你可以用我的模型,但必须跑在我的基础设施上,用我的电)。也许是另一种我现在想不到的形态。
但有一件事是清楚的:靠"防止复制"来维持竞争优势,在数字化的领域从来没有长期成功过。
两种资产,两种命运
那什么能长期成功?
回到这个系列一直在讲的东西。
模型能力是可复制的。Claude 的推理能力,一旦通过 API 暴露出来,就可以被大规模提取。今天蒸馏 Claude,明天蒸馏 GPT,后天蒸馏 Gemini。Anthropic 可以建检测系统、封假账号、发博客指控,但已经完成的 1600 万次对话里包含的能力,已经在对方的训练数据里了。拿走了就是拿走了。
Anthropic 在博客里也承认:没有一家公司能单独解决这个问题。
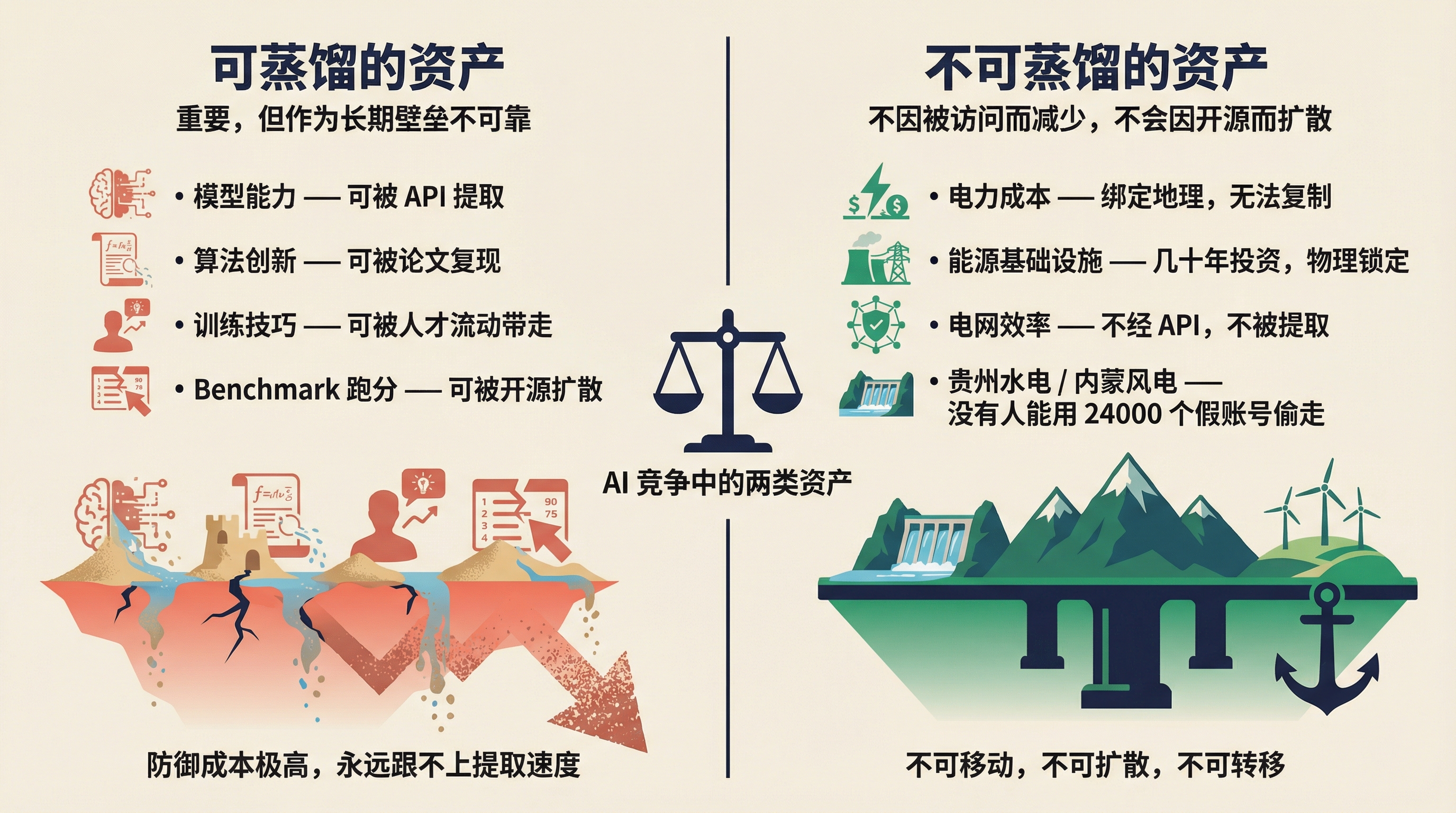
模型能力作为竞争壁垒,天然是脆弱的。它可以被复制、被蒸馏、被开源扩散、被论文复现、被人才流动带走。防御成本极高,而且永远跟不上提取的速度。
现在看另一种资产。
你没法"蒸馏"一个国家的电价优势。没有人能用 24000 个假账号偷走贵州的水电,或者内蒙的风电。电力绑定地理,绑定基础设施,绑定几十年的投资。它不经过 API,不能被复制,不会因为被"访问"了就减少。
AI 竞争中存在两类资产:可蒸馏的和不可蒸馏的。
模型能力、算法创新、训练技巧——可蒸馏的。重要,但作为长期壁垒不可靠。
电力成本、能源基础设施、电网效率——不可蒸馏的。不会因为被访问而流失,不会因为开源而扩散,不会因为人才跳槽而转移。
AI 竞争中的两类资产:可蒸馏 vs 不可蒸馏
意外的第二层:蒸馏加速趋同
但这里有一个我起初没想到的推论。
如果蒸馏真的防不住——不管是通过更好的检测还是更严格的管制,总有办法绕过去——那它的长期效果是什么?
模型能力的趋同。
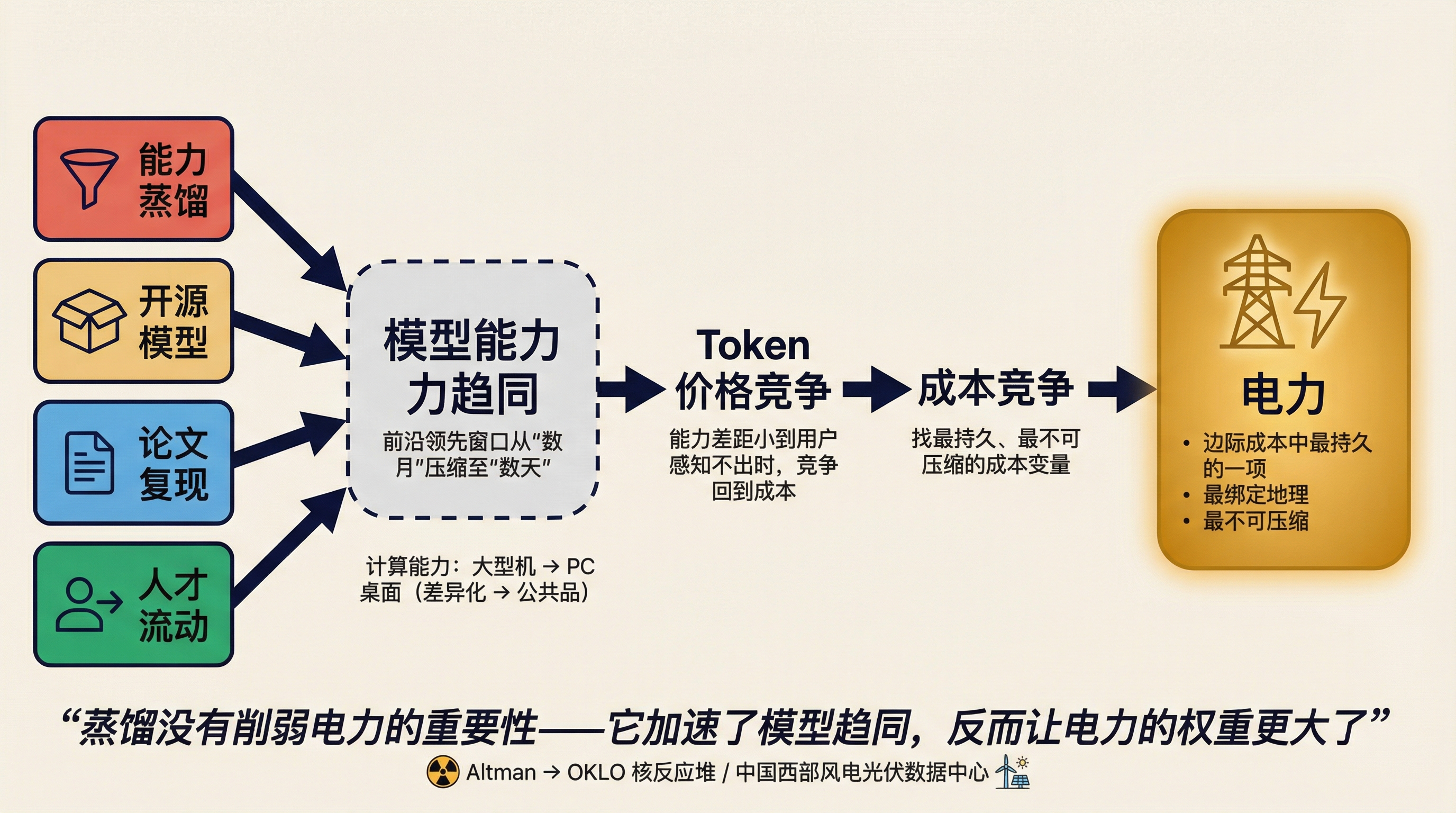
想想看。Claude 的推理能力被蒸馏到中国模型里,GPT 的编程能力也被蒸馏过来,Gemini 的多模态能力同样如此。与此同时,中国的开源模型(DeepSeek、Qwen)也在被全世界蒸馏和复现。能力在各个方向上流动,最终结果是:模型层面的差距被不断压缩。
这不是说所有模型会变得一样好——前沿实验室总会有几个月的领先窗口。但这个窗口会越来越短。当 MiniMax 能在 Anthropic 发布新模型后 24 小时内调转枪口,这个"几个月"正在被压缩成"几周"甚至"几天"。
蒸馏、开源、论文复现、人才流动——这些机制共同作用的结果是:模型能力正在从"差异化优势"变成"基础设施级别的公共品"。
就像计算能力在 PC 时代经历的一样——最初只有 IBM 有大型机,后来每个人桌上都有一台。计算能力没有消失,但它不再是区分赢家的变量。
当模型能力趋同,什么变量会浮上来?
电力。
如果所有人的模型都差不多好(或者差距小到用户感知不出来),那 Token 的价格竞争就回到了成本竞争。成本竞争的终局,在第一篇和第二篇里已经分析过了——电力是边际成本中最持久、最不可压缩、最绑定地理的那一项。
蒸馏没有削弱电力的重要性。它加速了模型趋同,反而让电力的权重更大了。
蒸馏加速趋同 → 电力成为终局变量:因果链框架图
三篇串起来
第一篇:电力出不了国,但 Token 可以。中国的电力优势通过 Token 绕过了物理出口壁垒。
第二篇:当模型被刻进芯片,算力变成固定成本,Token 的边际成本只剩电费。
第三篇:模型能力可以被蒸馏、被复制、被趋同化。但电力不能。蒸馏加速了模型趋同,反而强化了电力作为终局变量的地位。
Altman 投 OKLO 做核反应堆,不是在投模型。中国在西部大规模建设风电光伏和数据中心,不是在投算法。他们都没有在投可蒸馏的东西。
这个系列写到第三篇,我越来越觉得:AI 行业讨论的焦点——模型参数、Benchmark 跑分、融资额、谁蒸馏了谁——这些都是前景。它们很热闹,很吸引注意力,但都是可蒸馏的。
背景里那个安静的、不性感的、不会出现在任何博客指控里的变量,是电。
没有人会为电发一篇指控博客。因为电偷不走。