从写代码到写规则:一个高级工程师的 AI 编程演进
2025 年初,Andrej Karpathy 在 X 上随手发了一条帖子,造了个词叫 Vibe Coding—— "完全跟着感觉走,拥抱指数级变化,忘掉代码本身的存在"。大半年过去,这个词已经进了 Collins 词典,成了 2025 年度词汇。但多数讨论还停留在 "AI 能不能写代码" 这个层面,很少有人认真拆解过:一个有九年经验的工程师,从半手动的 AI 辅助到几乎不碰编程语言,中间到底经历了什么,又因此改变了哪些判断。
这篇文章试图回答这个问题。不是布道,不是教程,只是一份来自生产环境的演进记录。
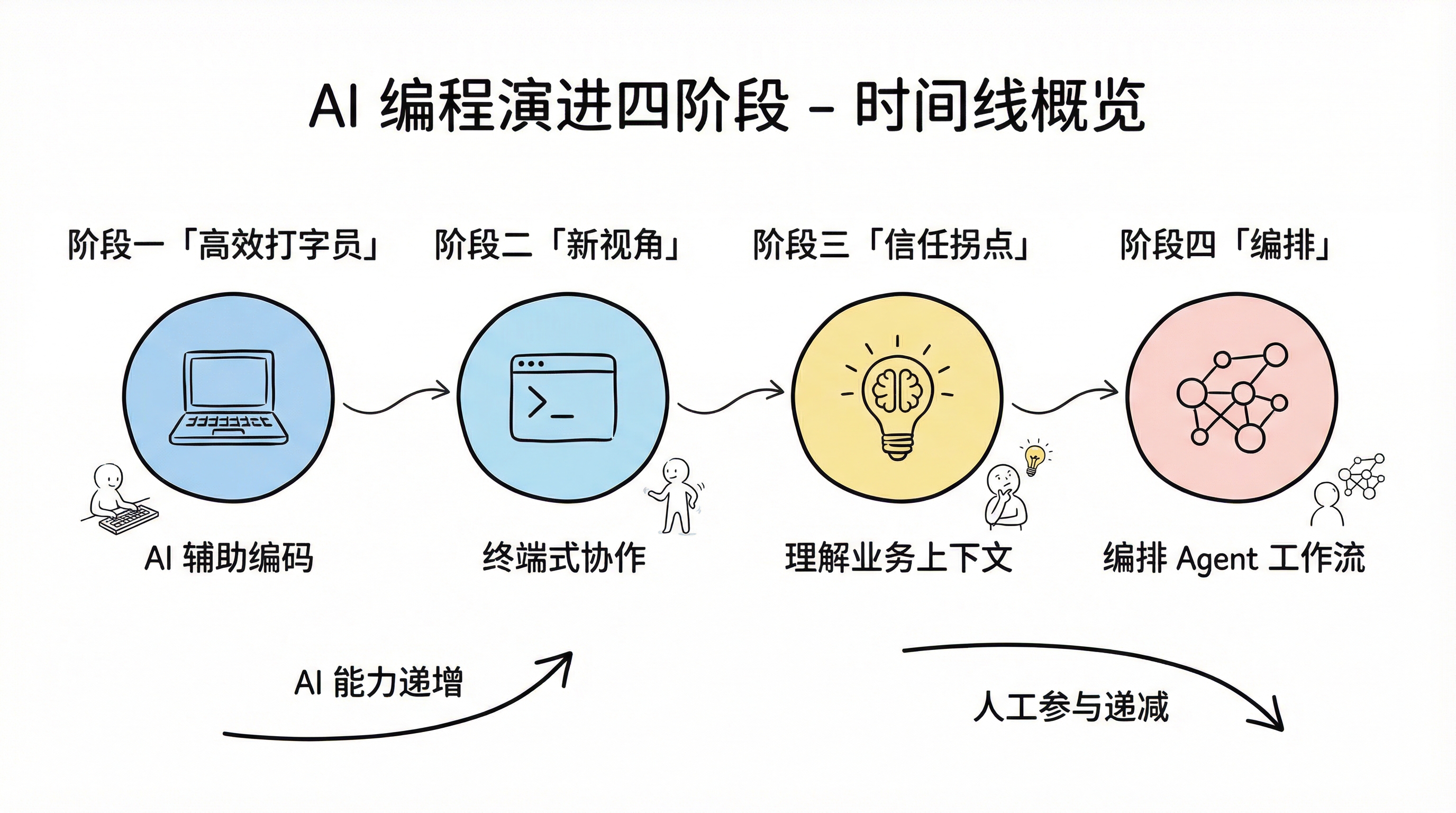
AI 编程演进四阶段时间线概览
第一阶段:AI 作为高效打字员
2025 年初的工具选择是 Cursor。它的核心价值很明确:项目级的上下文理解。把一个功能的业务逻辑梳理清楚,输给 Cursor,它能迅速写出写法一致、风格统一的代码。对于那些非复杂交互的核心逻辑——比如一个标准的 CRUD 流程、一套数据转换管道——Cursor 能节约大量的"体力劳动"时间。
但这个阶段的边界也非常清晰。AI 的 debug 能力不可靠:它能修语法错误,但面对一个跨组件的状态同步 bug,往往会越改越乱。复杂交互更是重灾区——但凡涉及多步骤、有条件分支的用户流程,AI 生成的代码几乎不可能一次跑通。更深层的问题是业务 sense 的缺失。"用户在这一步可能会返回上一页修改"这种隐含假设,AI 完全无法自行推断,需要把流程图级别的信息喂给它。
这个阶段的工作模式本质上是人脑做架构和决策,AI 做翻译和填充。效率的提升是实在的,但人的参与度依然很高。
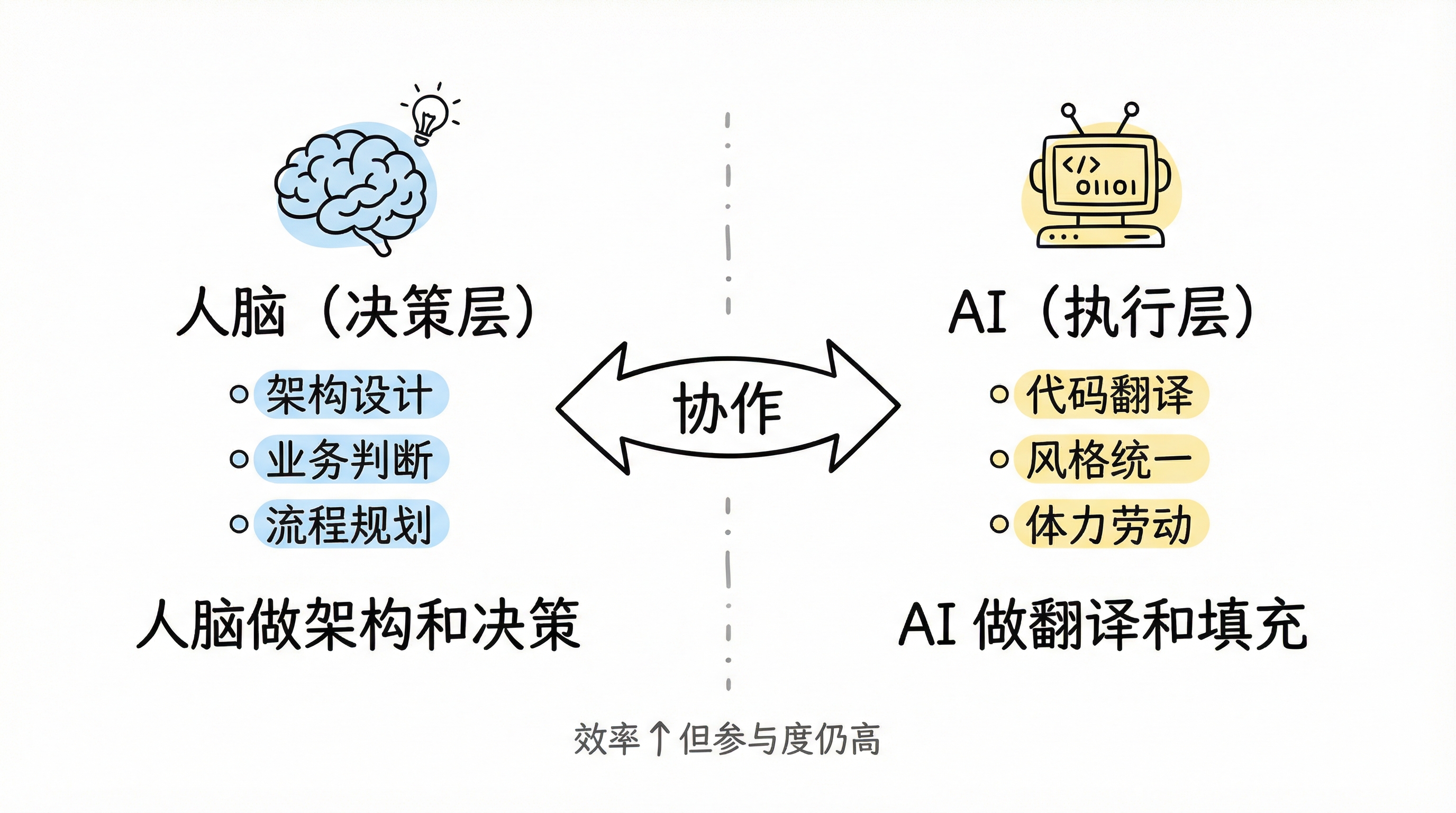
第一阶段工作模式:人脑决策层与 AI 执行层的分工协作
第二阶段:新视角,但还不够
Claude Code 的出现带来了一个完全不同的交互范式。与 Cursor 在 IDE 内辅助编码不同,Claude Code 像一个真正的程序员在终端里工作:用 grep 搜索日志,用 sed 批量替换文件内容,甚至能理解语义相似但写法不同的代码片段。
这种"程序员式"的操作方式带来了新的可能性。它不只是在光标位置补全代码,而是能主动在项目中搜索、理解、修改。但在早期阶段,Claude Code 与 Cursor 的实际差距并不大——核心瓶颈仍然是业务理解。它能操作代码,但不理解代码背后的业务意图,仍然需要大量的人工辅助来补全上下文。
这个阶段更像是看到了一种新的协作方式的可能性,但还没到可以放权的程度。
第三阶段:信任拐点
真正的转折出现在 Claude 4 Opus。
变化不是渐进的,而是一个明显的跃迁。最让人意外的体验不是它写代码更快了,而是它开始真正理解业务上下文。一个具体的例子:代码中有一段注释描述了某个业务流程的执行顺序,但后来业务逻辑调整了,代码已经改过来了,注释却没有同步更新。Claude 4 Opus 在处理相关代码时,发现注释描述的流程与实际代码逻辑不一致,主动把注释修正了。
这不是简单的文本匹配——它需要理解代码在做什么,注释在说什么,两者之间的矛盾在哪里,正确的版本应该是什么。这说明它已经具备了对业务场景的深层理解能力。
从这个阶段开始,工作模式发生了根本性转变。不再需要给 AI 预设角色或描述具体场景,它能从代码的上下文中自行提取这些信息。于是工作流变成了:在每个项目的 agent.md 里写入基本规则和业务背景,然后把需求直接输给它——不需要拆解,不需要翻译成技术语言,它完全能理解。甚至在完成开发后,它会自己做一轮测试验证。
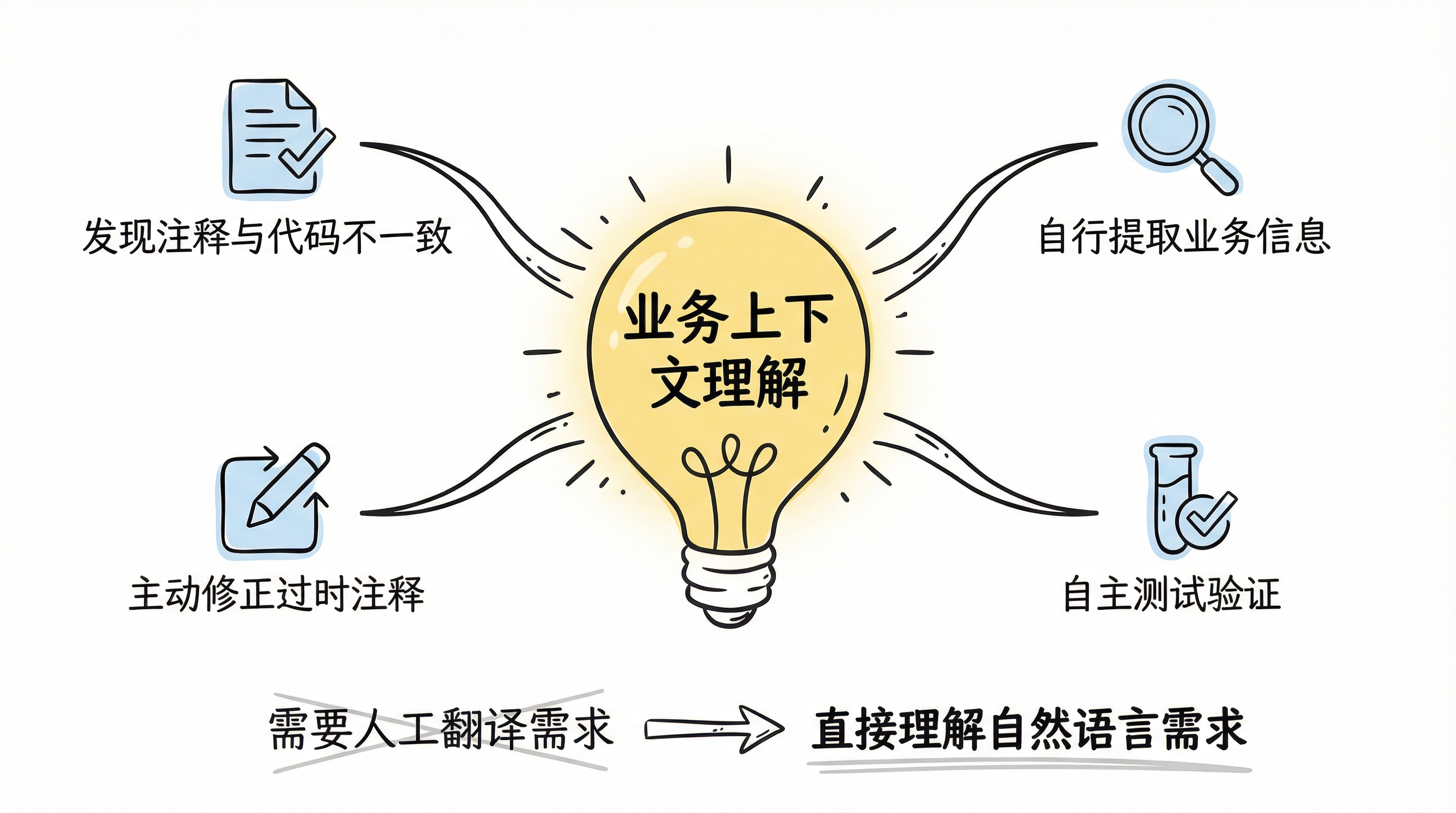
信任拐点:AI 理解业务上下文的能力跃迁
第四阶段:从编程到编排
当 agent 的智力跨过信任门槛后,工作的重心自然开始转移。不再关注"怎么写代码",而是关注"怎么让 agent 更高效地工作"。
这个阶段引入了 OpenSpec——一个 spec 驱动的开发框架。纯 Vibe Coding 的问题在于过程不可控:agent 在多轮对话后容易遗忘之前的任务上下文,而且无法追溯它为什么做出某个决定。OpenSpec 通过将需求结构化为 proposal、specs、design 和 tasks 四个层级,让整个开发过程变得可审核、可追溯。它解决的核心问题不是"AI 能不能写代码",而是"AI 写的代码是不是按照约定来的"。
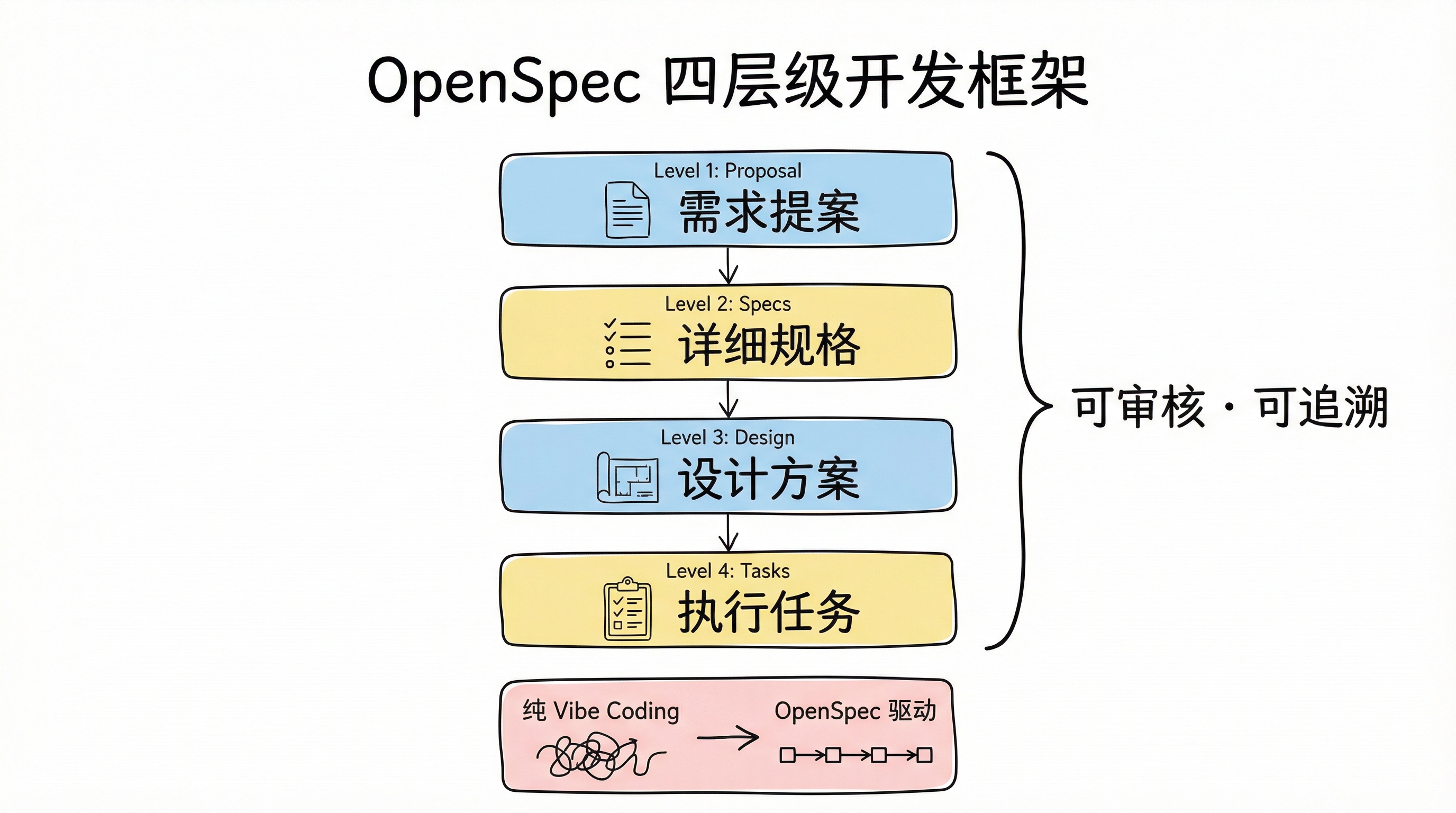
OpenSpec 四层级开发框架
同时,大量时间开始投入到 Skill 的设计中。Skill 本质上是为 agent 编写的领域知识文档——不是通用的编程规范,而是针对具体业务仓库的深度指南。比如在某个项目的 Skill 里,会明确写出"不要使用 XX 方案实现这个功能,因为它会导致 YY 问题"。这些都是踩过的坑,是人类工程师花了时间才获得的经验,把它们写成 Skill 后,agent 就能避免重复犯错。
更进一步,开始研究 workflow 和 multi-agent 模式——让多个 agent 并行处理不同的任务,或者让 agent 自行协调分工。随着 agent 智力的持续提升,需要人工干预的环节越来越少。
一个有趣的逆向变化也在这个阶段出现:为了让 AI 工作得更好,主动改进了代码本身。具体包括三类改动。第一,把冷门的第三方库替换成社区主流方案——AI 对热门库的训练数据更充分,表现更好,而社区惯例本身通常也更合理。第二,删除过度封装和不必要的抽象层——那些"只有原作者能看懂"的设计模式,对 AI 来说是纯粹的噪音。第三,将非标准写法改为社区惯例——冗余的自定义实现换成标准库提供的方案,减少了因为奇怪规则而额外消耗的 token。
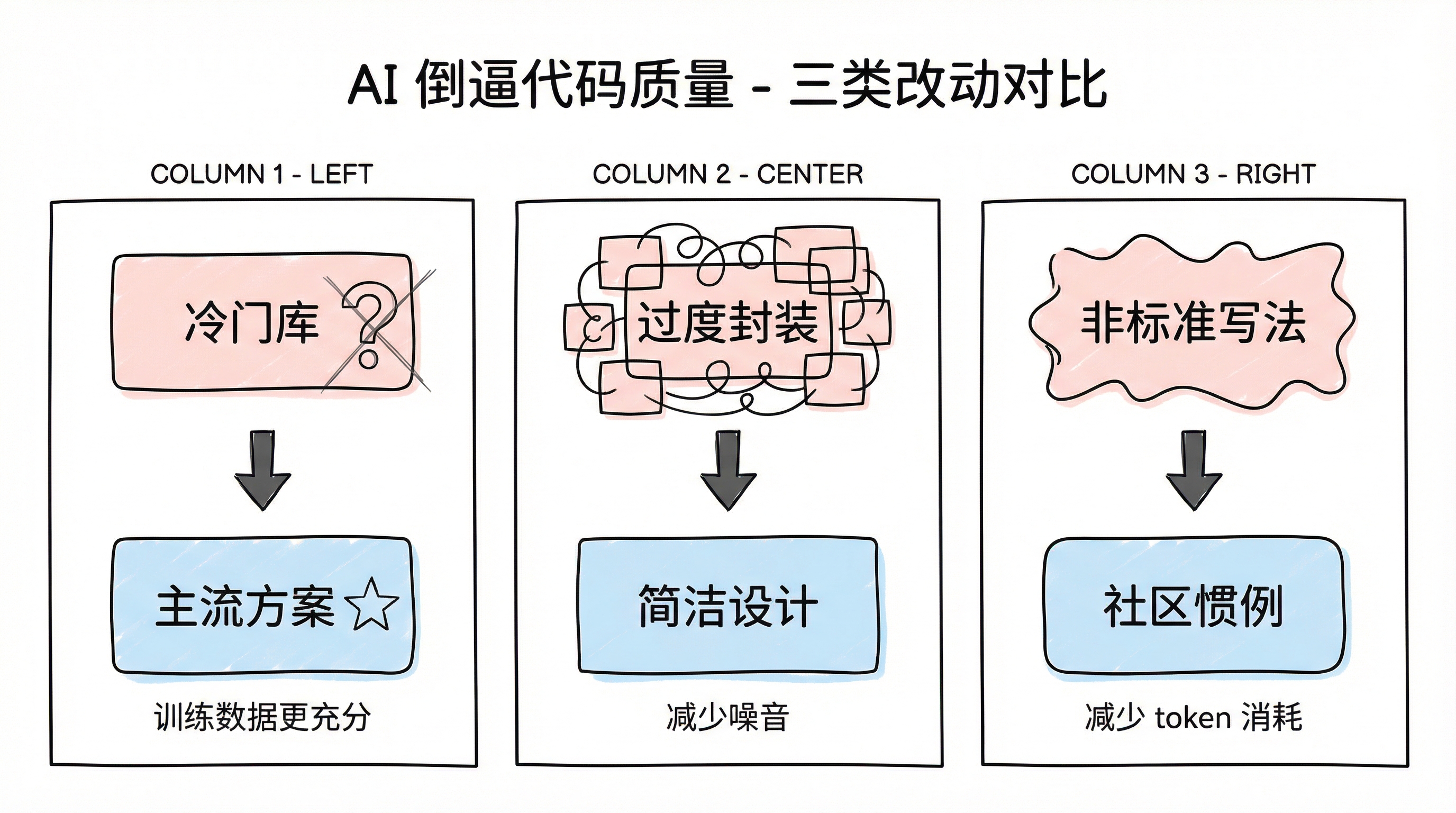
AI 倒逼代码质量:三类改动对比
本质上,AI 倒逼了一次对代码质量的重新审视。那些"对人类勉强能用,对 AI 完全不友好"的代码,在 AI 编程的语境下就是技术债。
边界和代价
诚实地说,Vibe Coding 目前有清晰的能力边界。
最典型的场景是复杂的 UI 交互。在一个类 SQL 查询构建器的开发中 —— 它有复杂的输入框嵌套、下拉菜单遮挡、条件分支的动态渲染 —— Agent 的表现明显不足。整体流程能走通,但细节层面的问题不断:元素遮挡导致操作被阻塞、输入框无法正确响应焦点事件。
根本原因是 agent 没有 runtime。它能推理代码逻辑,但无法"看到"界面的实际渲染效果。虽然 agent browser 和 Chrome DevTools MCP 等方案已经出现,但目前的连接成本和响应速度都还不够实用。这意味着但凡涉及复杂视觉交互的场景,人工调试和验证仍然是不可替代的。
这不是一个会永远存在的限制 —— runtime 连接的问题迟早会被解决 —— 但在当下,它定义了 Vibe Coding 的实际边界。
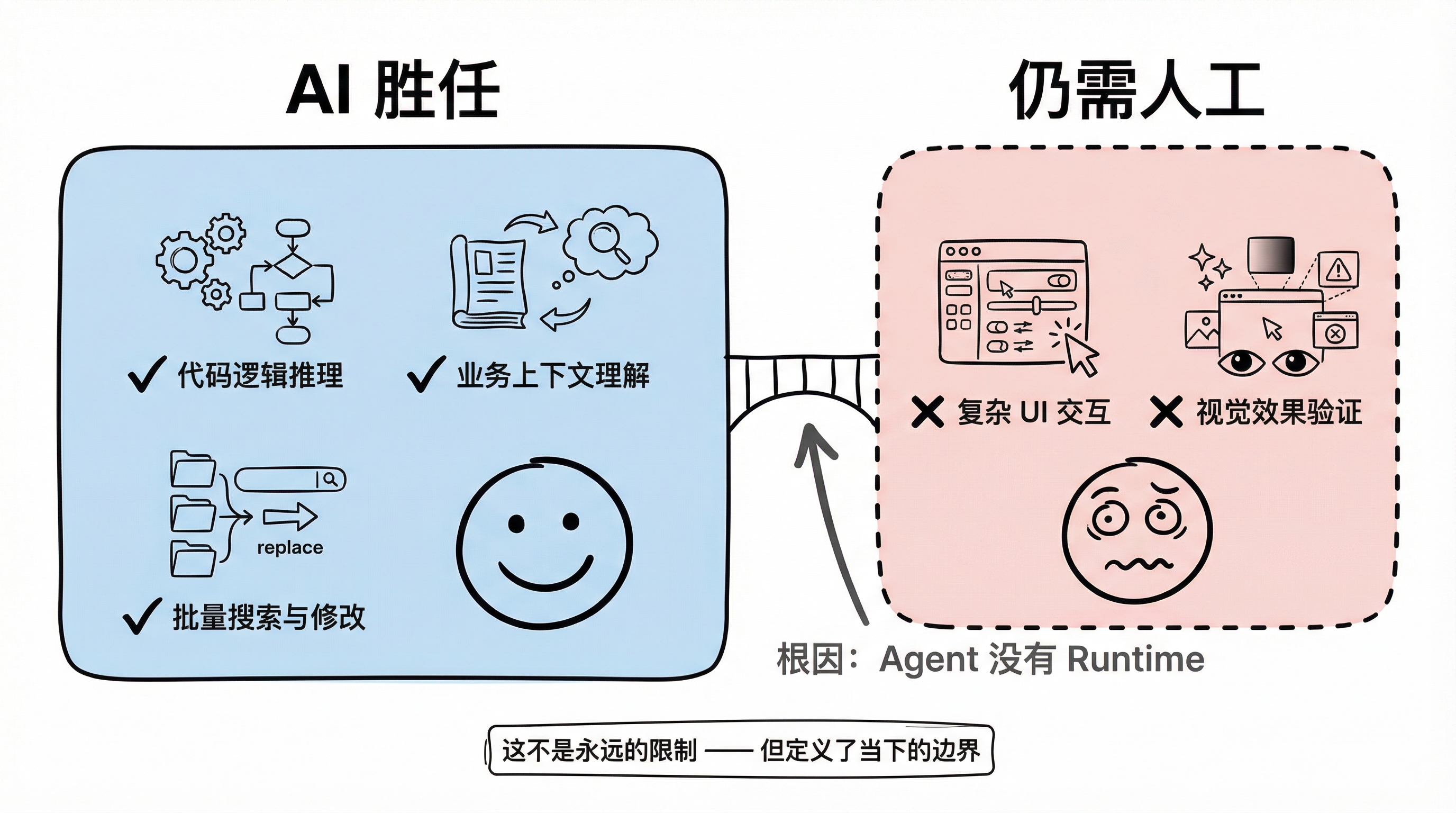
Vibe Coding 能力边界:AI 胜任区域与仍需人工区域
三个越来越清晰的判断
经过大半年的实践,有三个判断变得越来越确定。
关于流程控制:管理协作,而非管理执行。 随着 agent 能力的提升,"监督每个 agent 具体在做什么"的意义在快速下降。真正重要的是 agent 之间如何协作——哪些是不可违背的原则,哪些是需要人工确认的关键节点。这很像工程管理的演进:从 code review 每一行代码,到定义架构约束和评审关键设计决策。未来的高效工程师,核心竞争力不是写代码的速度,而是编排 agent 工作流的能力。
关于 Skill 设计:专精胜过通用。 越是具体、越是详尽的 Skill,适用范围虽然越窄,但在其适用范围内的表现会越来越好。为某个项目专门编写的 Skill,能让新成员几乎零成本上手,agent 的表现也会非常出色。但如果试图把一个 Skill 写得越来越通用、越来越庞大,它就会变得平庸。这和工程师的能力模型完全一致:一个对所有环节都了解但不够深入的人,很难在某个方向上精通。而一个在特定领域积累了丰富经验的人,效率会远超前者。
关于编程范式的迁移:AI 友好将成为新的筛选标准。 OpenSpec 的自然语言驱动编码已经展示了这个趋势。未来所有的框架、语言和工具只会分为两类:对 AI 友好和对 AI 不友好。冷门的库、过度封装的架构、非标准的写法——所有"只有人类通过特殊训练才能理解"的东西,都会因为效率劣势而逐渐被淘汰。不是因为它们本身不好,而是因为效率的迭代不可能倒退。当 AI 能在主流方案上做到 95 分,没有人会为了坚持一个 AI 只能做到 60 分的冷门方案而放弃这个效率差距。
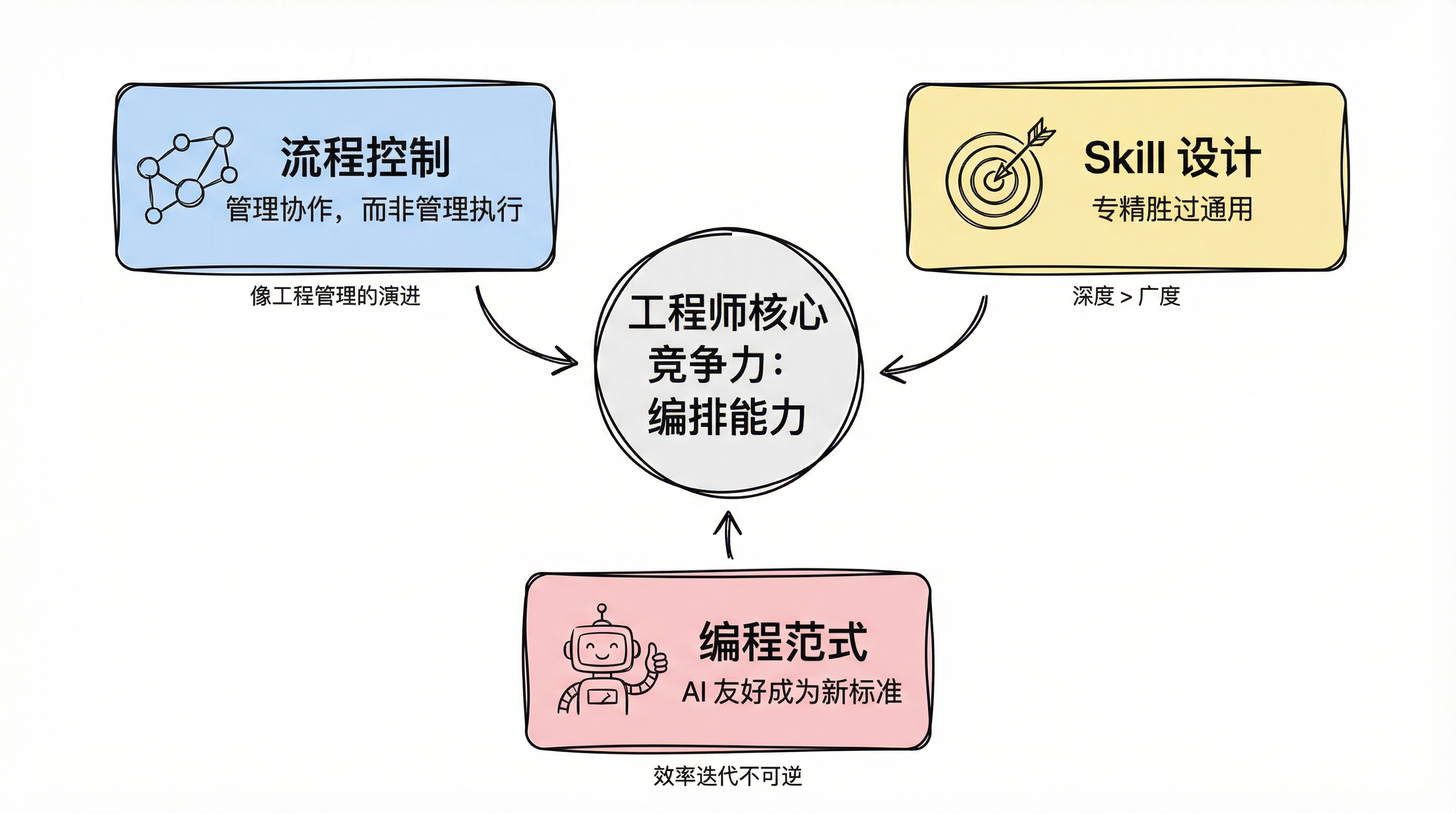
三个核心判断汇聚为工程师新核心竞争力
不是结论,而是一个坐标
从写代码到写规则,从操作细节到设计框架,这个转变在大半年内发生得比预想的更快。但它不是终点。Agent 连接 runtime 的能力还在早期,multi-agent 的协调效率还有很大提升空间,Skill 的最佳实践还在摸索中。
唯一可以确定的是方向:工程师的价值正在从"实现能力"向"编排能力"迁移。写代码这件事本身不会消失,但它在工程师工作中的占比会持续下降。取而代之的是对业务的深度理解、对 agent 工作流的设计能力、以及把隐性知识转化为可执行 Skill 的能力。
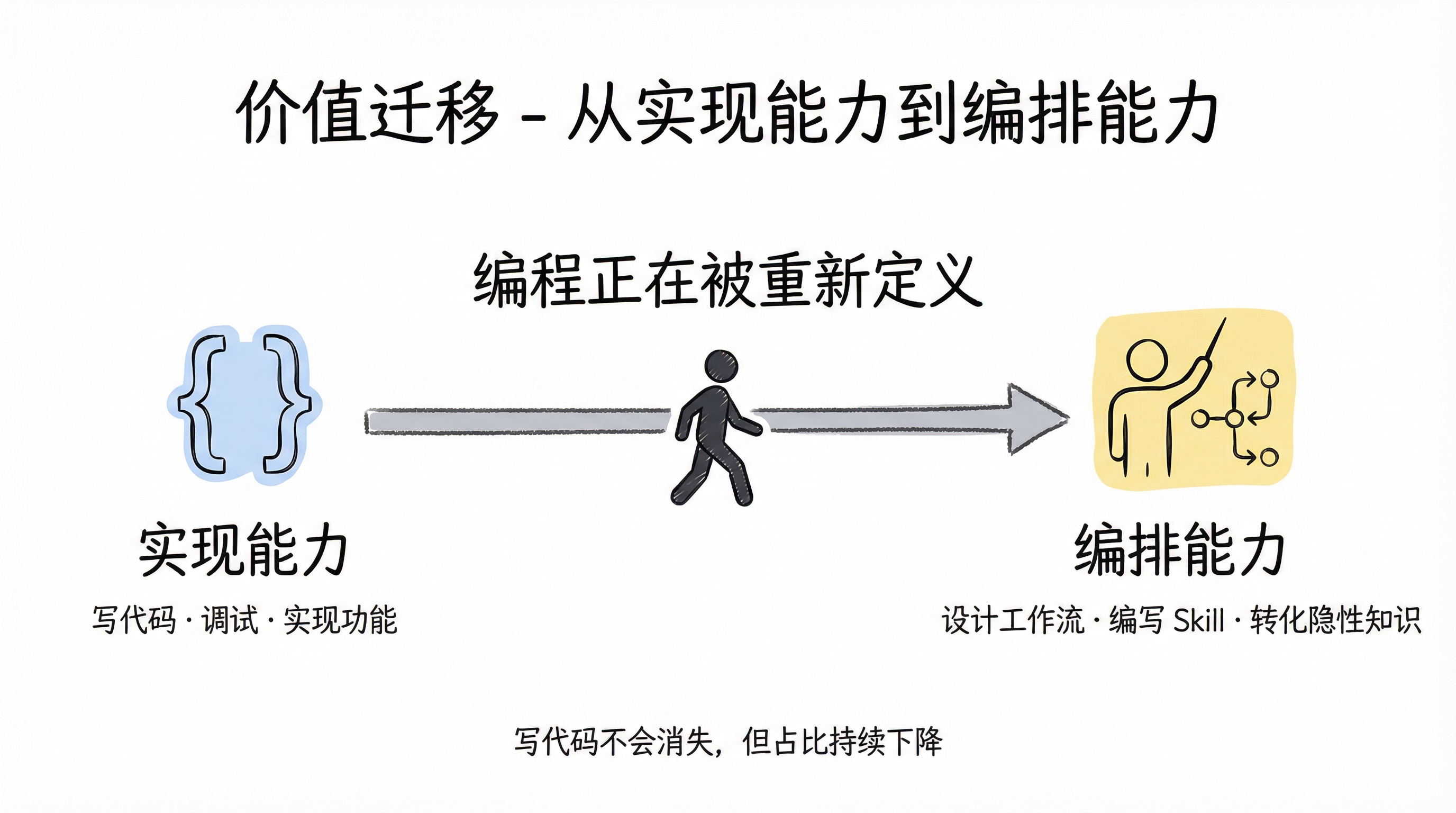
价值迁移:从实现能力到编排能力
这不是一个关于"AI 会不会取代程序员"的故事。这是一个关于编程这件事本身正在被重新定义的故事。