Harness 与 Agentic Engineering:控制一个会自己做决定的系统

cover
一次意外的失控
前两篇分别讲了 AI 怎么"看"(Prompt 与 Context Engineering)和怎么"动"(MCP 与 Skill)。写到这里,拼图看起来已经差不多完整了:你把信息喂给模型,模型想好了,通过工具去执行。但我最近碰到的一件事,让我意识到中间缺了一块很关键的东西。
我用 Claude Code 帮一个项目做重构。任务不复杂:把一批旧的 API 接口迁移到新的路由结构。我给了它清楚的 Context,配好了相关的 Skill,MCP 也接上了代码仓库和文档。它开始干活了。前几步都很顺利,识别旧路由、创建新文件、迁移逻辑。然后它自己做了一个判断:它认为有些旧的测试文件已经"不需要了",直接删掉了六个测试用例。
模型的推理不是没有道理。那些测试确实是针对旧路由写的。但它不知道的是,其中三个测试覆盖了一些边界条件的回归检测,删掉之后我们的 CI 就裸奔了。
问题出在哪?不在模型的能力,不在 Prompt,不在 Context,不在 MCP,也不在 Skill。问题在于:谁来决定模型可以删文件?谁来设定"做到这一步要停下来问我"?谁来管理这个循环的节奏和边界?
这就是 Harness 要解决的事。
Harness:不是另一个框架,是另一种框架
Harness 这个词直译是"马具",也就是套在马身上让骑手能控制方向和速度的那套装置。在 AI 工程里,它指的是包裹在模型外面的那层应用框架。
但先说清楚它不是什么。它不是 LangChain 那种工具库,不是 RAG 那种技术方案,也不是一个具体的产品。Harness 是一种架构角色,类比的话,它在 AI 应用中的位置相当于 Spring Boot 在 Java Web 应用中的位置,或者 Next.js 在前端应用中的位置。
拿 Claude Code 举例,它的 Harness 每一轮对话都在做这些事:启动时加载 CLAUDE.md、Memory、MCP 配置和 Skill 列表;收到你的消息后,把这些东西跟你的输入组装成一个完整的 API 请求发给模型;模型返回结果后,解析输出,如果里面包含工具调用就去执行;执行结果再回传给模型,开始下一轮。
画出来是一个循环:
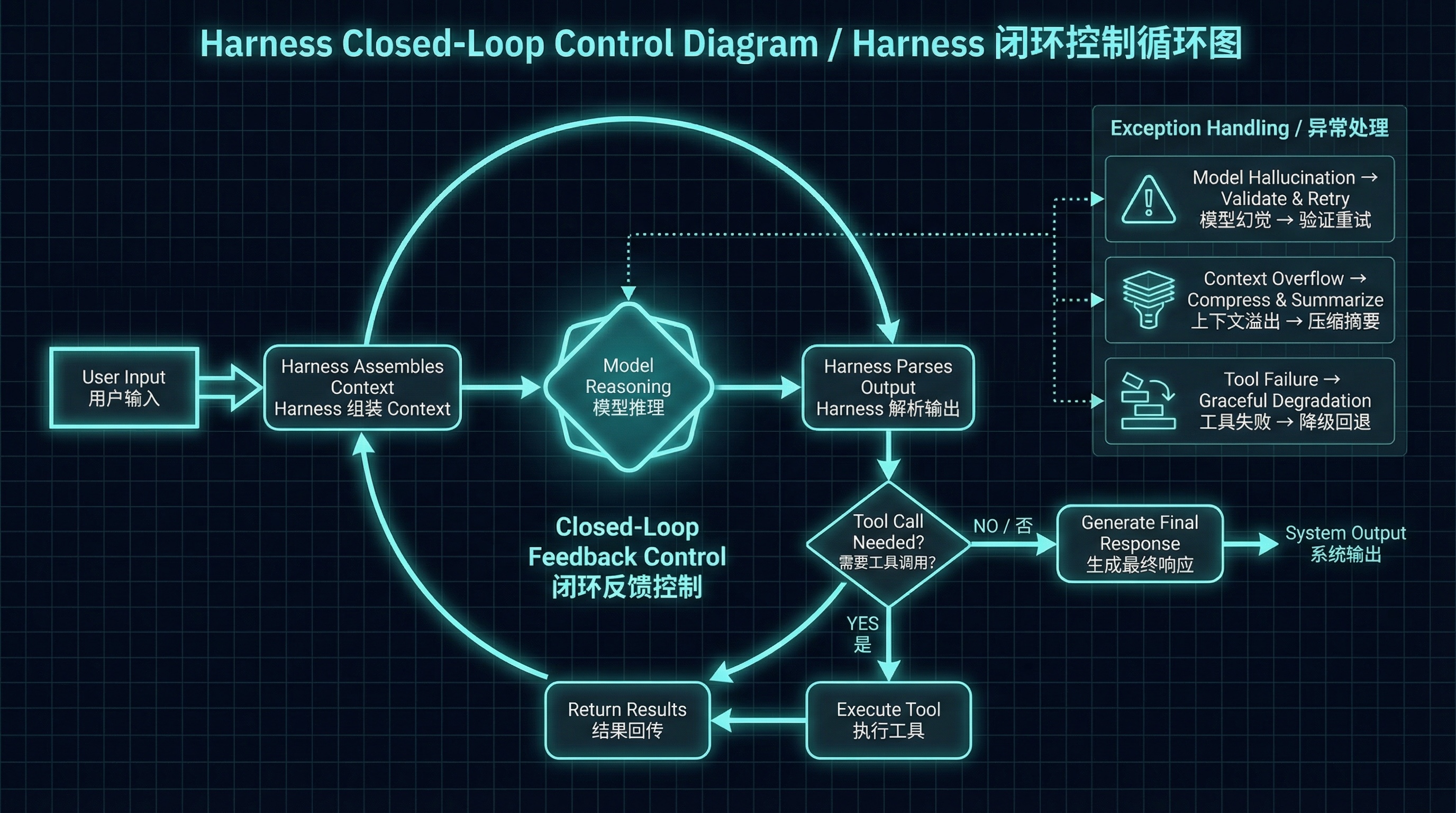
Harness 闭环控制循环图
模型在这个循环里是什么角色?它是其中一个环节,不是全部。这个认知很重要。同一个 Claude 模型,在 claude.ai 网页版里只能聊天,在 Claude Code 里能读写文件、执行命令、调用 MCP。模型没变,Harness 变了。
小林在圆桌讨论时打了一个比方,很传神:Harness 是餐厅的管理系统。它决定服务员穿什么制服(System Prompt),培训手册放在哪里(Skill),能打哪些外线电话(MCP),客户档案存在哪个系统里(Memory)。同一个服务员在不同餐厅工作,表现可以完全不同,因为管理系统不同。
闭环:一个 1948 年就想明白的道理
这里有一个我花了不少时间才咂摸出来的洞察。
传统的应用框架追求的是最大化控制。你写一个 Web 应用,每条路由走哪个 handler、每个请求经过哪些中间件,全是你定义的。系统的行为是确定的,偏差来自 bug,消灭 bug 就消灭了偏差。
但 Harness 面对的情况不一样。它包裹的核心组件——语言模型——本身就是非确定性的。你没法消灭偏差,只能管理偏差。这让 Harness 的设计哲学跟传统框架产生了根本分歧:传统框架追求最大化控制,Harness 追求在保持可靠性的前提下最大化自主性。
这句话听着像是新发明的理论,其实不然。1948 年,数学家诺伯特·维纳出版了一本书叫《控制论》(Cybernetics),副标题是"关于在动物和机器中控制与通信的科学"。他定义的核心问题就是:对有自主行为的系统实施有效治理。方法论是闭环反馈控制——设定目标、执行、观察结果、计算偏差、调整行动、再执行。
传统框架是开环的:你下达指令,程序执行,结束。Harness 是闭环的:模型输出之后,Harness 观察结果(有没有工具调用?调用合不合理?),根据观察决定下一步(执行工具?还是停下来问用户?),然后把结果反馈回模型继续循环。
78 年前维纳定义的问题,跟今天 AI Harness 要解决的问题,结构上是同一个。
三种使用层次
理解了 Harness 的本质,实操上你会发现自己处在三个层次之一。
第一层:用现成的 Harness。ChatGPT、Claude.ai、Gemini,都是别人给你搭好的 Harness。你只需要打字。绝大多数人在这一层,完全没有问题。
第二层:配置现有的 Harness。这是产出比最高的层次。以 Claude Code 为例,你可以做这些事:写 CLAUDE.md 告诉 AI 你的项目背景和工作规范;配置 Memory 让它记住跨会话的信息;接入 MCP Server 让它能访问外部服务;安装 Skill 让它遵循标准流程;设置 hooks 在特定操作前后触发自定义逻辑(比如"每次提交代码前自动跑测试")。这些配置加在一起,就是在调整 Harness 的行为。
第三层:从零构建 Harness。这意味着你自己处理模型 API 调用、工具执行、上下文管理、错误恢复、并发控制。绝大多数团队不需要走到这一步,但理解它的存在有助于看清整个画面。
回到我开头那个删测试文件的事故。解决方案不是写更好的 Prompt,也不是调模型参数。解决方案是在 Harness 层配一条 hook:当 AI 要删除文件时,弹出确认提示。五分钟搞定,从此再没出过事。
Agentic Engineering:信任的边界在哪里
到这里,Harness 的画面清楚了。但还有一个更上层的问题。
Harness 回答的是 how——怎么控制一个自主系统。但在回答 how 之前,有一个 why 的问题需要先回答:你到底想要这个系统自主到什么程度?
这就是 Agentic Engineering 关心的事。它跟 Harness 不是线性递进的关系,而是不同维度的。Agentic 是目标和理念层面的设计,Harness 是实现手段层面的工程。你先决定"我要造一个多自主的系统",再设计"怎么控制它"。
一个 Agent 可以被定义为 Prompt + Context + MCP + Skill + Harness 的组合。前面四篇讲的都是组件,Harness 是编排,这些加在一起就是一个 Agent。但 Agentic Engineering 真正要解决的,是组合之后涌现出来的新问题。
自主决策边界。 给 AI 多少自由?它可以自己改代码吗?可以删文件吗?可以花钱调用付费 API 吗?可以代表你给同事发消息吗?传统系统里这类问题用 RBAC 权限模型解决,角色和权限写死在配置里。但 Agent 的决策是动态的、语义级的。它不是"调用了一个没权限的 API",而是"做了一个看起来合理但实际上不该做的判断"。
错误累积。 一个 10 步任务,如果第 3 步出了偏差,后面 7 步都建立在错误基础上。传统分布式系统用 Saga 模式解决类似问题:每一步都有补偿操作,出错了可以回滚。但 Agent 的错误是语义级的——它把一段代码重构"错"了,你怎么精确回滚一个"判断"?
多 Agent 协作。 一个写代码的 Agent、一个审查代码的 Agent、一个跑测试的 Agent,怎么配合?传统微服务通过定义明确的 API 接口来协作。但 Agent 之间的通信是自然语言,模糊、有歧义、高度依赖上下文。
人机信任。 最让我头疼的问题。Agent 做完一个复杂任务,你怎么验证结果?如果每一步都检查,那跟自己做有什么区别?如果不检查,风险谁承担?传统系统的审批流是二元的——通过或不通过。但 Agent 的产出需要语义级的理解才能评估。
这四类问题有一个共同的根源:非确定性和语义模糊性。传统软件工程的所有方法论——测试、类型系统、权限模型、事务机制——都建立在"确定性"这个地基上。Agentic Engineering 面对的处境是,地基本身就是模糊的。
| Agentic 问题 | 传统对应物 | 新在哪? |
|---|---|---|
| 自主决策边界 | RBAC 权限 | 传统权限是静态的;Agent 决策是动态的、语义的 |
| 错误累积 | Saga 模式 | 传统错误可回滚;Agent 错误不可精确回滚 |
| 多 Agent 协作 | 微服务 / Actor 模型 | 传统接口确定;Agent 间通信自然语言、模糊 |
| 人机信任 | 审批流 | 传统审核二元;Agent 审核需理解语义上下文 |
六个概念,一张图
三篇写完,六个概念讲完了。最后把它们的关系画在一起。
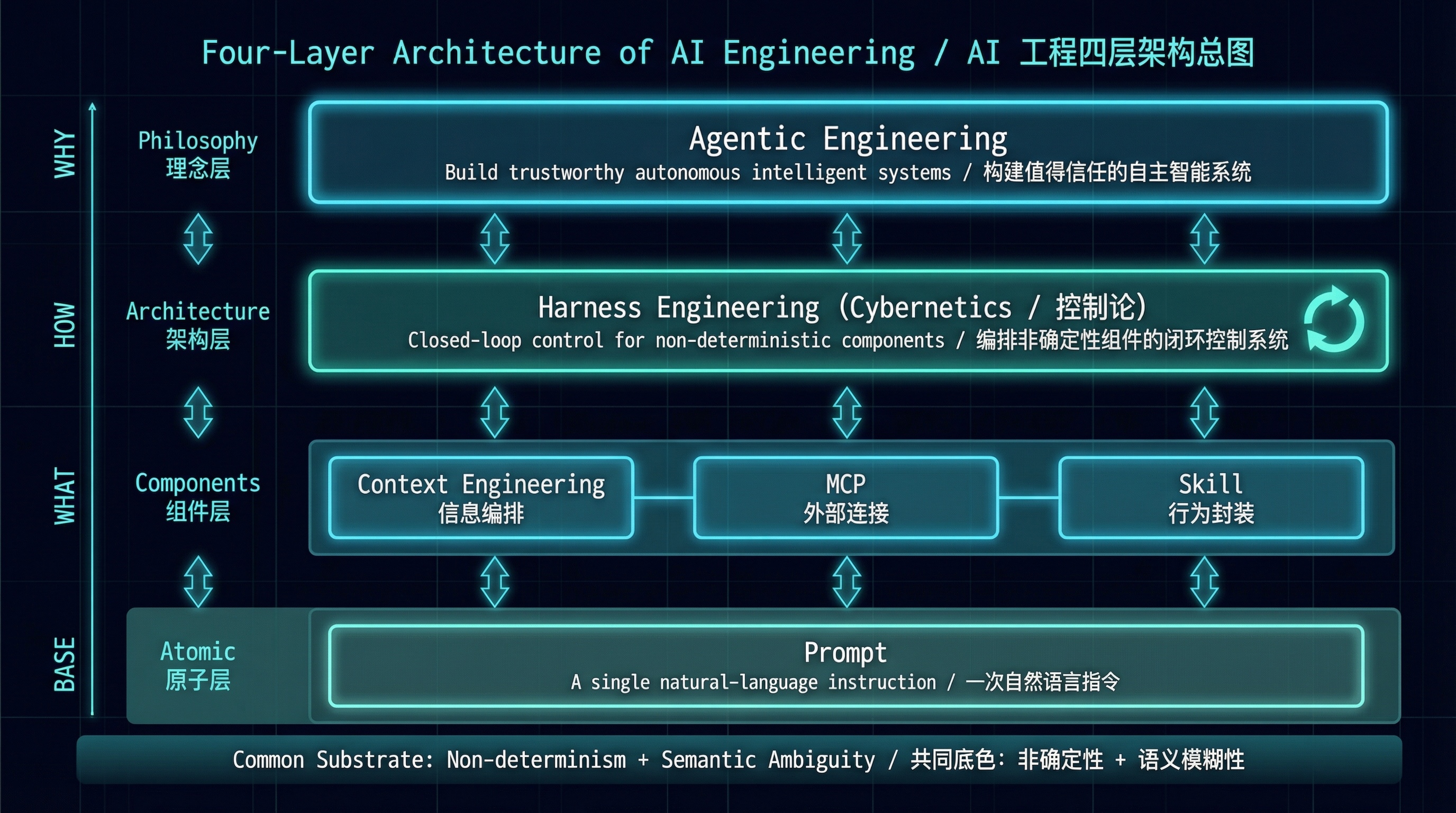
AI 工程四层架构总图
从下往上看:Prompt 是你说的一句话。Context Engineering 决定 AI 在你说话之前看到了什么。MCP 给 AI 接上外部世界。Skill 告诉 AI 遇到特定任务该怎么做。Harness 把这一切编排成一个闭环运转的系统。Agentic Engineering 站在最上面,问一个价值判断的问题:这个系统应该自主到什么程度?
从上往下看也成立:你先回答"要造多自主的系统"(Agentic),再设计"怎么控制"(Harness),再选择"用哪些组件"(Context + MCP + Skill),最后落到"每一步具体说什么"(Prompt)。
这两个阅读方向都对。实际工作中大多数人从下面往上走,碰到问题才往上追。这没什么不好。重要的是知道上面还有东西,不至于在 Prompt 层死磕一个本该在 Harness 层解决的问题。
一个简单的工作流
收束之前,给一个实际的例子,把几个概念串起来。
假设你想搭一个 Agent 来做每日代码审查。从底层往上走:
- Prompt 层: 用户说"审查一下今天的 PR"。
- Context 层: Harness 自动注入项目的编码规范(CLAUDE.md)、昨天审查的记录(Memory)、本次 PR 的 diff。
- MCP 层: 通过 GitHub MCP Server 拉取 PR 列表和代码变更。
- Skill 层: 加载
team-code-reviewSkill,里面定义了检查规则和输出格式。 - Harness 层: 编排整个循环——先拉 PR 列表,对每个 PR 执行审查 Skill,汇总结果,如果发现严重问题暂停并通知人类。
- Agentic 层: 设计决策——审查结果是直接在 PR 上留评论,还是先发给人看?发现安全漏洞时能直接 block PR 吗?这些信任边界需要提前设定。
六层不是每次都要从头设计。大多数情况下你在用别人的 Harness,配置自己的 Context 和 Skill,偶尔处理一个 Agentic 级别的决策问题。但当系统表现不符合预期的时候,知道问题可能出在哪一层,排查效率会高很多。
写在系列结尾
三篇文章,六个概念,写了一个星期。写完之后最大的感受是:AI 工程实践正在以非常快的速度从"一门手艺"变成"一套体系"。
半年前,会写 Prompt 就算是"会用 AI"。现在,Prompt 只是原子层,上面还有四层东西。这个体系还在快速演化,今天画出来的四层架构图半年后可能就要改。但底层的问题结构不太会变:怎么跟一个非确定性系统协作,怎么在自主性和可控性之间找到平衡。
维纳在 1948 年就在想这件事。我们在 2026 年用另一种方式重新遇到了它。
如果你读到这里还没有动手,建议从第二层开始:挑一个你常用的 AI 工具,花半小时配置它的 Harness。写一个 CLAUDE.md,装一个 MCP Server,或者创建一个 Skill。你会发现,调整 AI 的工作环境比调整你说的话,效果来得快得多。
然后观察一下:你愿意让它自己做多少决定?你在哪个点开始不放心?那个不放心的点,就是你的 Agentic Engineering 实践的起点。