MCP 与 Skill:给 AI 接上手脚,再给它一本操作手册

cover
一个很具体的挫败
上一篇讲了 Prompt 和 Context Engineering,核心是一个问题:怎么让 AI 看到正确的信息。但看到归看到,能做事是另一回事。
我最近的一个体验很说明问题。我让 AI 帮我查下周的日程安排,看看有没有冲突,然后把结果发给同事。这三件事任何一件单独拿出来都不复杂,但 AI 做不了。它不能访问我的 Google Calendar,不能查实时数据,也没办法发邮件。它就像一个被锁在隔音玻璃房里的顾问:听力极好,分析能力极强,但既没有手,也没有眼睛。
这不是智力问题,是物理限制。AI 有三个先天硬伤:知识有截止日期、不能执行动作、不能访问私有数据。你可以把 Prompt 写得再完美、Context 布置得再周全,这三堵墙就在那里。
所以接下来要讲的两个概念,分别解决两个不同层次的问题。MCP 解决的是"让 AI 够得到外面的世界",Skill 解决的是"让 AI 把事做对"。
MCP:AI 世界的 USB 协议
回忆一下 2000 年前后的电脑。键盘用 PS/2 口,打印机用并口,鼠标用串口,扫描仪用 SCSI。每种设备一种接口,买错了线就是插不上。然后 USB 出来了,一个口通吃。
MCP(Model Context Protocol)做的事情,本质上跟 USB 一样:定义一套标准协议,让 AI 应用能够以统一的方式连接各种外部服务。
没有 MCP 的时候,如果你想让 AI 能查 Google Calendar,你得自己写一套对接代码:认证怎么做、API 怎么调、返回数据怎么解析。想让它再能查 GitHub?再写一套。想加上 Gmail?又一套。N 个 AI 应用对接 M 个服务,就是 N x M 套代码,这个组合爆炸任何做过企业集成的工程师都太熟悉了。
有了 MCP,Gmail 只需要提供一个 MCP Server,任何支持 MCP 的 AI 客户端都能直接连上。N x M 变成了 N + M。
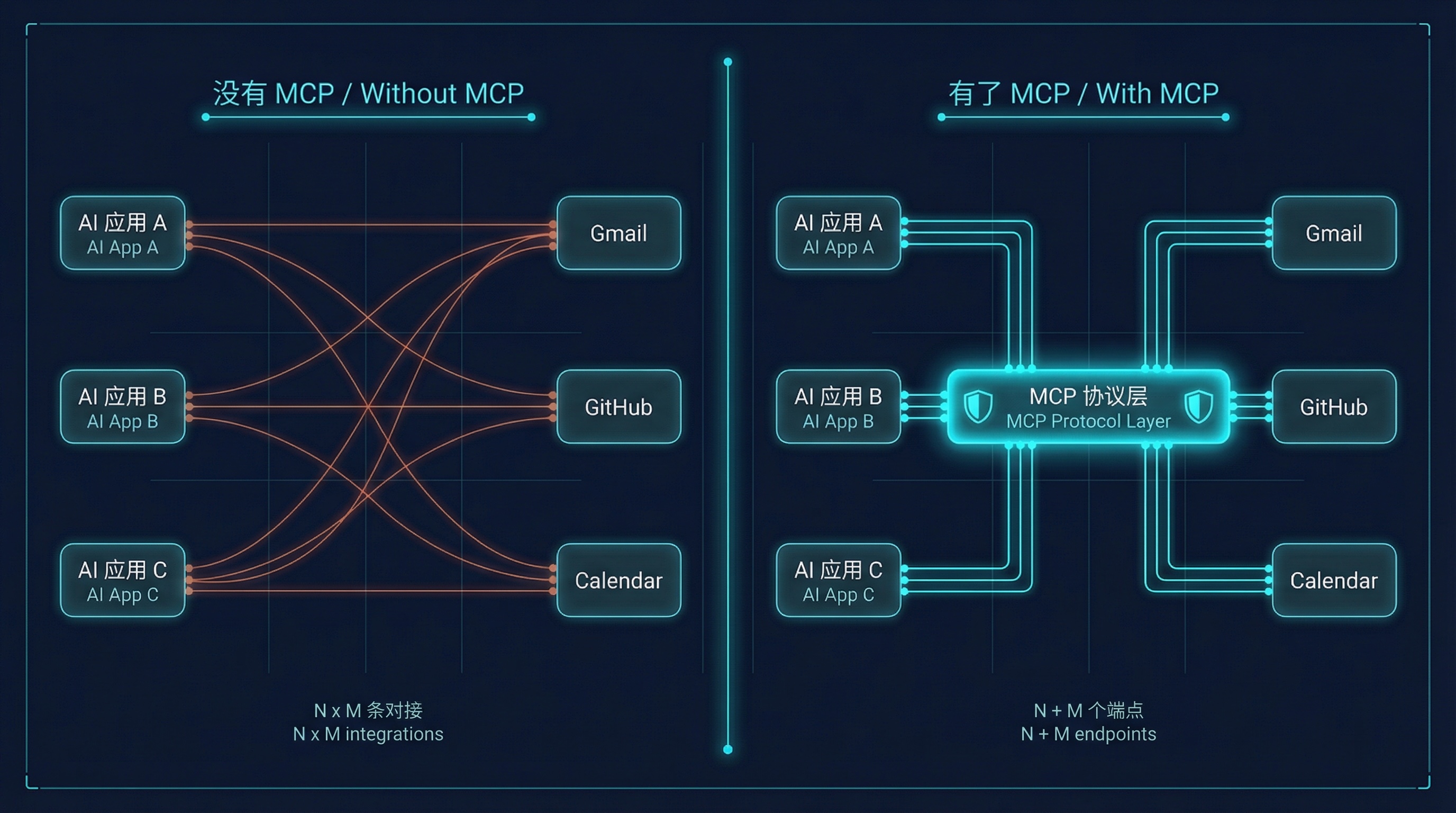
MCP 解耦:从 N×M 到 N+M
搞技术的朋友可能觉得这听着很耳熟。没错,MCP 的本质就是一个 RPC 规范,只不过调用方从程序变成了语言模型。如果你用过 ODBC 或 JDBC,那个心智模型几乎可以平移过来:应用不需要知道数据库的具体方言,中间层统一翻译。
MCP 协议里定义了三样东西:Tools(AI 可以执行的操作,比如"发送邮件")、Resources(AI 可以读取的数据源,比如"最近的会议记录")、Prompts(预定义的交互模板)。通信用的是 JSON-RPC,对做过 Web 开发的人来说没有学习曲线。
小林在我们圆桌讨论时打了一个比方,我觉得很贴切:MCP 就像餐厅里服务员用的那套统一系统。以前查后厨库存要打内线电话,查顾客会员信息要翻本子,叫外卖配送要用另一个 App。现在统一接入一个系统,同一套操作逻辑就能处理所有事。
先浇一盆冷水
MCP 的技术设计是优雅的,但标准能不能真正统一,从来不取决于技术本身。
USB 之所以成功,是因为 Intel、微软、苹果这些巨头都站到了同一边。如果当年 Intel 推 USB、微软推 FireWire、苹果搞自己的,那今天你的桌上可能还是一堆不同的线。MCP 目前的势头不错,Anthropic 主导发起,多家 AI 厂商在跟进,但生态博弈远没有结束。
另一个值得注意的点是安全。MCP 让 AI 能执行真实操作了——发邮件、写代码、改文件。这意味着一旦 Prompt 注入攻击通过 MCP 触发了某个 Tool,后果就不只是"回答了一个错误答案",而是可能真的发了一封不该发的邮件。能力越大,攻击面越大,这不是技术能单独解决的问题。
Skill:写给 AI 的标准操作手册
现在 AI 有手有脚了,但有手有脚不等于会干活。
这个区别在软件行业里有一个精确的对应。运维领域有一种东西叫 Runbook,就是操作手册:某个服务挂了,第一步检查什么,第二步重启什么,第三步通知谁,每一步的前置条件和检查点都写得清清楚楚。Runbook 不是教你运维知识,它假设你已经具备基本能力,只是把"这件事的正确做法"钉死。
Skill 做的是同样的事,只不过读 Runbook 的人换成了 AI。
一个具体的例子。我有一个日常任务:把写好的 Markdown 文章发布到微信公众号。这个任务涉及:Markdown 转 HTML、图片上传到图床并替换链接、调用公众号 API 创建草稿、处理各种格式兼容问题。如果每次都在 Prompt 里把这些步骤写一遍,不仅低效,而且容易出错——上次记得的细节这次可能忘了。
把这些步骤封装成一个 Skill,AI 每次执行这类任务时自动加载,问题就解决了。Skill 里会写清楚:触发条件是什么("当用户要求发布公众号文章时"),具体步骤有哪些,用到哪些工具,有什么约束规则("图片必须先上传到 R2 再替换链接"),甚至包含典型的示例。
Skill 和 Prompt 的关系,用一条线就能说清楚:
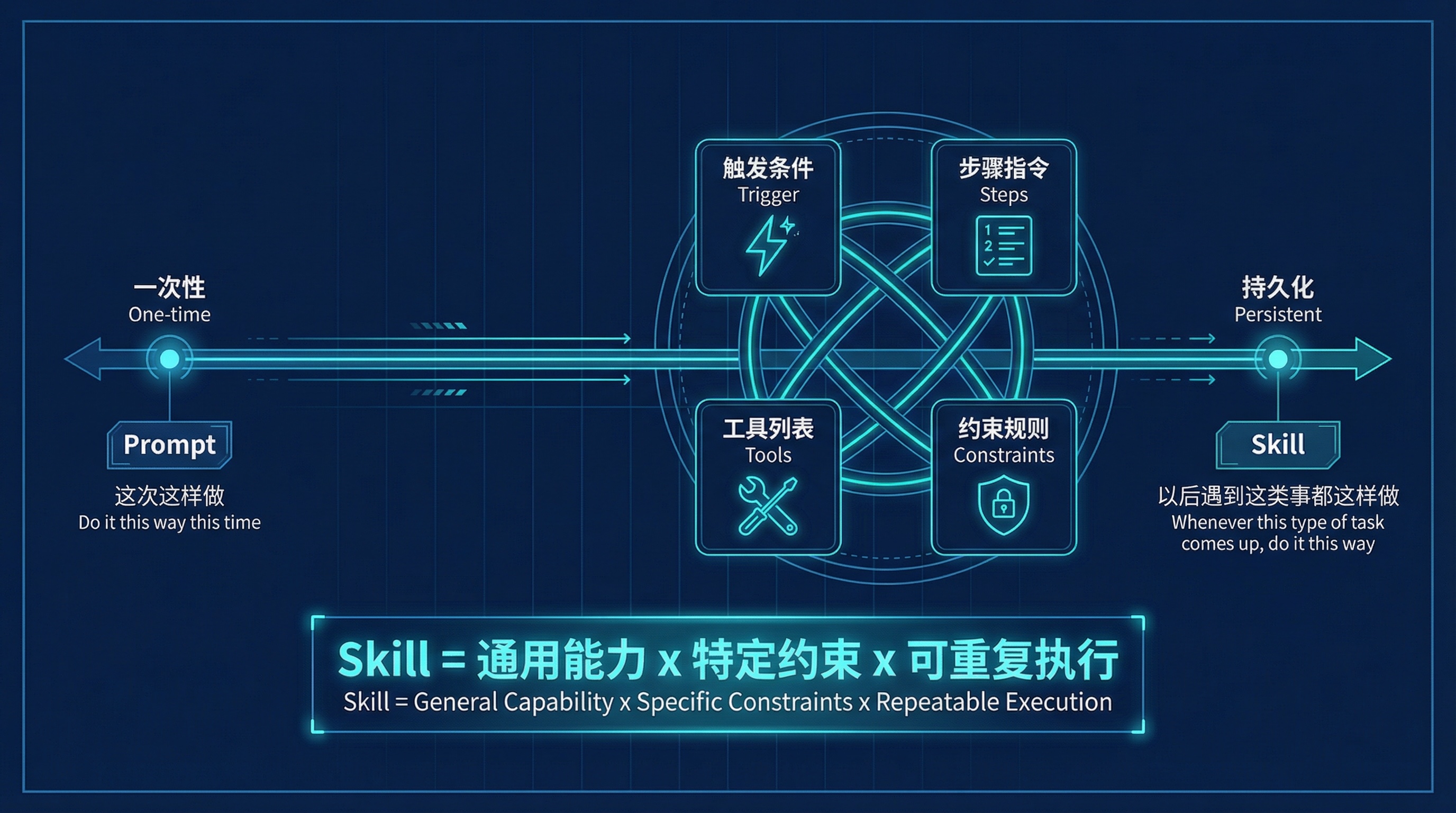
Prompt 与 Skill 的定位光谱
Prompt 是一次性的对话指令,说完就没了。Skill 是持久化的、可以版本管理的、可以分享给其他人的。你修了一个 bug 在 Skill 里加了一条规则,所有使用这个 Skill 的人都受益。这跟软件工程里的 Library 是一个逻辑:封装好的能力单元,需要时引入。
但 Skill 又不完全等于代码库。它更像 Runbook 和 Configuration 的结合体。Runbook 定义流程,Configuration 定义参数和约束,Skill 两样都包。
这里有一个关键洞察:Skill 不是在教 AI 新能力。AI 已经"大概会做"大部分事情。你让它把 Markdown 转成 HTML,它能做;你让它调一个 API,它也能做。Skill 解决的问题是把"大概能做"变成"确定能做对"。差别在哪?在细节。公众号的 HTML 不支持某些 CSS 属性、图片链接必须是 HTTPS、正文里的代码块需要特殊处理——这些 AI 不会主动知道,但写进 Skill 里它就每次都能做对。
用一个公式概括:Skill = 通用能力 x 特定约束 x 可重复执行。
动手试试
讲了这么多概念,看看实际操作长什么样。
装一个 MCP Server,以 Claude Code 为例。假设你想让 AI 能查实时技术文档(比如某个框架的最新 API),可以在项目的 .mcp.json 里加一个 context7 的 MCP Server:
{
"mcpServers": {
"context7": {
"command": "npx",
"args": ["-y", "@anthropic/plugin-context7"]
}
}
}装好之后,你在跟 AI 对话时说"帮我查一下 Next.js 15 的 Server Actions 怎么用",它就会通过这个 MCP Server 去拉取最新文档,而不是依赖训练数据里可能过时的信息。
写一个简单的 Skill,结构也不复杂。假设你经常需要让 AI 帮你做代码审查,而且你们团队有特定的规范,可以创建一个 Skill 文件:
---
name: team-code-review
trigger: 当用户要求做 code review 时
---
## 步骤
1. 先检查是否有未提交的变更,列出变更文件
2. 对每个变更文件,检查以下规则:
- 函数长度不超过 50 行
- 所有公共函数必须有注释
- 不允许使用 any 类型(TypeScript 项目)
- 错误处理不能用空的 catch 块
3. 汇总问题,按严重程度排序
4. 对每个问题给出具体的修改建议
## 约束
- 只检查本次变更的文件,不要扫描整个项目
- 风格问题和逻辑问题分开列出
- 如果没有问题,明确说"本次审查未发现问题"这就是一个最基本的 Skill。它不长,但把"怎么做一次代码审查"的步骤和标准固定了下来。下次你或者团队里的任何人触发这个 Skill,AI 都会按照同样的标准执行。
还没想清楚的部分
MCP 和 Skill 解决了两个层面的问题,但新的问题已经在冒出来了。
MCP 让 AI 能触达的东西越来越多,Skill 让 AI 做事的标准越来越固定。这两者叠加之后,AI 的自主性就开始变成一个真实的决策问题:你要给它多大的行动范围?哪些操作需要人确认,哪些可以自动执行?这不再是一个技术选择,而是一个信任设计的问题。
另一个让我犹豫的方向是 Skill 的粒度。写得太粗,AI 还是会在细节上出错;写得太细,维护成本就上去了,而且可能限制了 AI 本来能做得更好的部分。在我目前的实践中,"专精胜过通用"是一个看起来对的原则,但最优解在哪里,我还在摸。
上一篇留了一个问题:能不能让 AI 自己决定它需要看什么?现在可以把这个问题延伸一下:当 AI 既能自己获取信息(MCP),又有标准流程可以遵循(Skill),它是不是已经具备了独立完成任务的基础条件?
这正是下一篇要聊的内容:Agent。一个能感知、能决策、能行动的 AI,跟一个只会回答问题的 AI,是完全不同的物种。但在讨论 Agent 之前,得先把 MCP 和 Skill 搞明白,因为它们是 Agent 的基础设施。没有手脚的 Agent 是空谈,没有操作手册的 Agent 是隐患。
先把你手头最常重复的一个 AI 任务写成 Skill 吧。不需要完美,能跑就行。这是理解整套体系最快的入口。