AI 最激烈的战场,可能最不重要
2026 年 2 月,7 个重大 AI 模型同月发布。所有人都在这一层拼命。但写了三层物理基础设施之后,我开始怀疑:最热闹的这一层,可能不是决定胜负的那一层。
所有人都在这里拼命
2 月 5 日,Anthropic 发布 Claude Opus 4.6。ARC-AGI-2 抽象推理得分 68.8%——比上一代翻了将近一倍。SWE-bench 真实世界编程 80.8%。GDPval-AA 知识工作排行榜登顶,领先 GPT-5.2 整整 144 个 Elo。发布二十分钟后,OpenAI 扔出 GPT-5.3 Codex——Terminal-Bench 2.0 得分 77.3%,反超 Opus 的 65.4%。同一天,两家公司同时发布旗舰模型。
五天后,2 月 10 日,ByteDance 的 Seedance 2.0 上线——AI 视频生成,音视频联合架构,多项评测超过 Sora 2。
第二天,2 月 11 日,智谱 AI 发布 GLM-5。744B 参数,全部在华为 Ascend 芯片上训练,零 NVIDIA 依赖,SWE-bench 77.8%,MIT 开源。当天股价涨了 28.7%。
再过一天,2 月 12 日,MiniMax 发布 M2.5。性能逼近 Opus 4.6,价格只有它的 1/20。
2 月 16 日,Alibaba 发布 Qwen 3.5。397B 参数 MoE 架构,只激活 17B,声称在多项基准上超过 GPT-5.2 和 Claude Opus 4.5。开源,Apache 2.0 协议,201 种语言。
2 月 17 日,Anthropic 发布 Claude Sonnet 4.6。SWE-bench 79.6%——距离自家旗舰 Opus 4.6 只差 1.2 个百分点,价格便宜 5 倍。在实际开发者测试中,70% 的人更偏好它而非上一代旗舰 Opus 4.5。
2 月 26 日,Google 放出 Gemini 3.1 Pro 预览版。ARC-AGI-2 得分 77.1%——反超 Opus 4.6 的 68.8%。
三周之内,每隔两三天就有一个模型刷新某项纪录,然后被下一个模型超过。月之暗面的 Kimi K2.5 在 1 月 26 日已经抢跑。没有人能安全地坐在榜首超过一周。
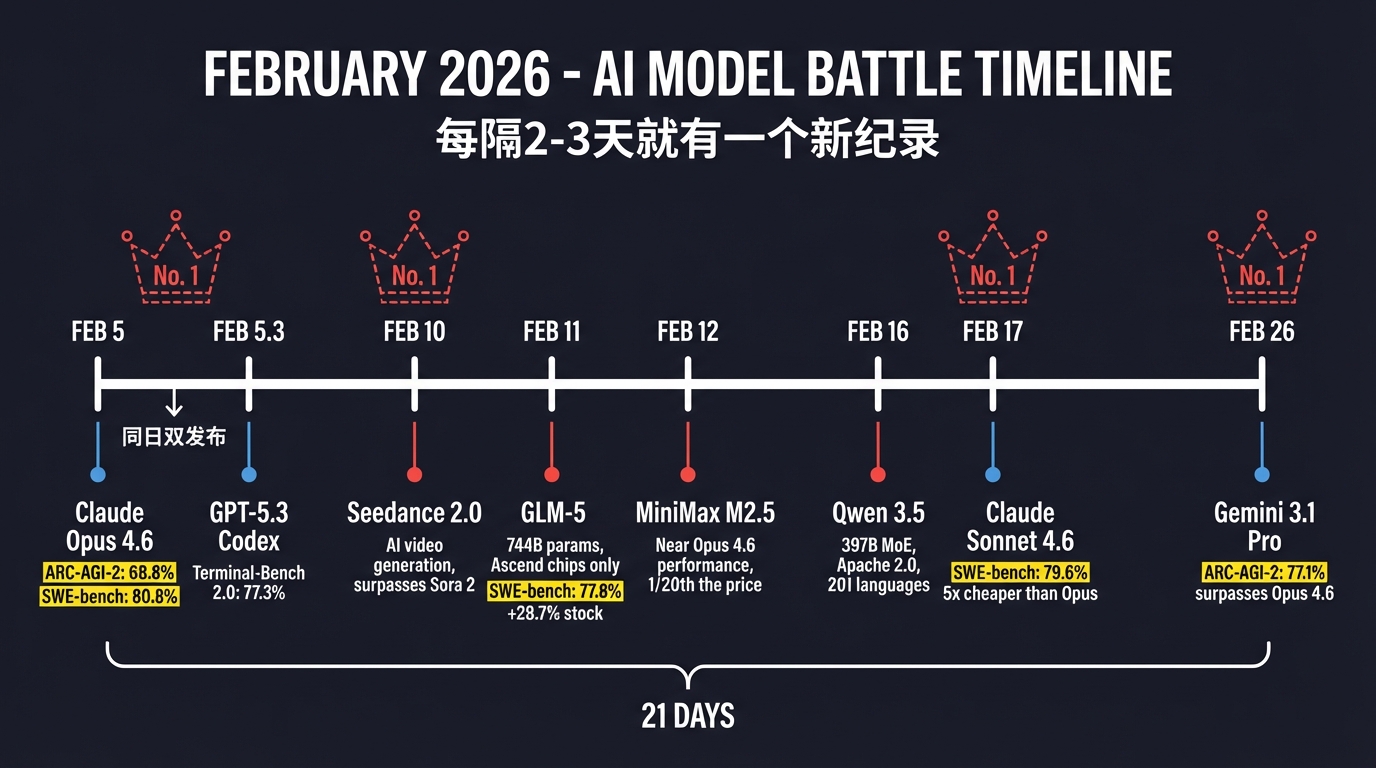
2026年2月AI模型发布时间轴
Google DeepMind 的 CEO Hassabis 在 1 月说中国最好的模型和美国"只差几个月"。RAND 在 2026 年初的研究更具体:中国大模型平台的网站访问量在两个月内增长了 460%,全球市场份额从 3% 跳到 13%。而且头部中国模型的崛起没有蚕食彼此的流量——Qwen、Moonshot、智谱 AI 同期都在增长。
这就是 2026 年 2 月的模型层。所有人都在这里拼命。但拼了三层物理基础设施之后再看这一层,我看到了一个反直觉的现象。
逆袭
下面三层,中国的处境是逐层递减的。
第一层电力——不可蒸馏的优势。全球第一的装机容量,西部的水电和风电为数据中心提供全球最低成本的电力。
第二层芯片——三面墙。EUV 光刻机、台积电先进制程、CUDA 软件生态,每一面都是硬性制约。Ascend 910C 的推理性能只有 H100 的六成。
第三层云——放大器。有独特性但没有明确优势,芯片层的裂缝和电力层的优势在这里同时被放大。
按这个趋势,到了第四层模型层,中国应该更弱才对——芯片更少、算力更贵、训练集群更小。
但事实恰好相反。
模型层是中国追赶速度最快、差距最小的一层。Qwen 和 DeepSeek 在全球开源模型排行榜上长期占据前列。GLM-5 完全在国产芯片上训练却在多项基准上逼近 GPT-5.2 和 Claude Opus 4.5。
但这个反弹需要诚实地限定范围。
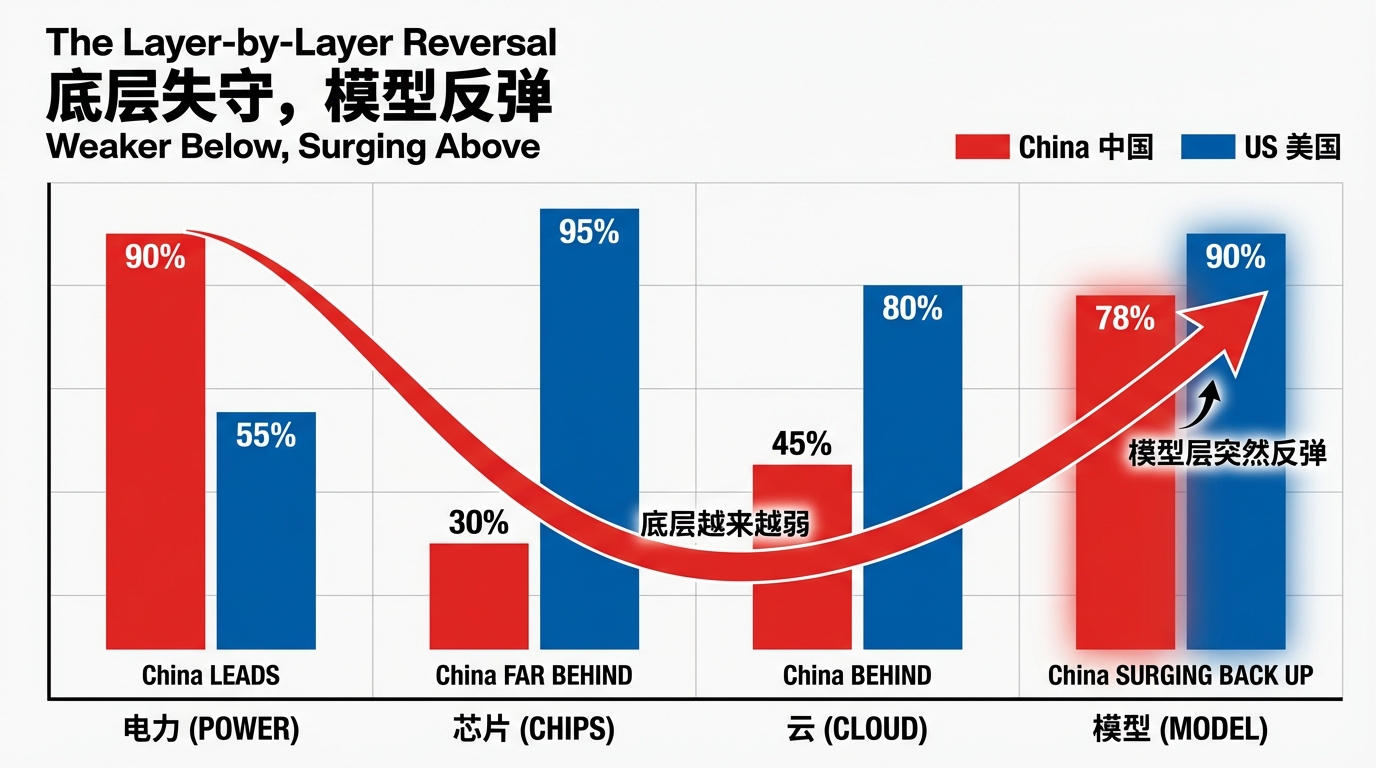
AI竞争五层蛋糕架构
前沿依然在美国手里
追赶最快不等于追上了。
开场列的那些基准数字,仔细看会发现一个规律:中国模型在刷新纪录的同时,美国前沿模型也在刷新纪录。Opus 4.6 在 GPQA Diamond 上拿了 91.3%,ARC-AGI-2 上 68.8%——而 Gemini 3.1 Pro 三周后就把 ARC-AGI-2 刷到了 77.1%。前沿的速度比追赶的速度更快。
中国没有对等的闭源前沿模型。
Qwen 3.5 和 GLM-5 在开源世界很强,在多项基准上确实逼近了 GPT-5.2 和 Claude Opus 4.5(上一代)。但和 Opus 4.6 比,差距依然明确。尤其是在需要深度推理、复杂代码工程、长链条多步骤任务这些"最后 5%"的能力上——这恰恰是企业愿意付高价买单的能力。
Opus 4.6 也很贵。但对于华尔街的对冲基金、硅谷的 AI 创业公司、全球 500 强的内部工具来说,贵不是问题,能力才是。这部分高端市场,中国模型目前进不去。
这里有一句暴论:Opus 4.6 是 2026 年最强的模型,也是 2026 年最弱的模型。这两句话同时为真。 最强,因为此刻没有任何模型在综合前沿能力上能超过它。最弱,因为它是这个时间点的天花板——而 AI 模型的天花板每隔几个月就被刷新一次。今天的"一骑绝尘",半年后就是基准线。
但"高端市场进不去"不等于"大部分市场进不去"。
Token 就像人的时间——有的人时间值 50/小时,但绝大多数工作不需要 $1000/小时的人来做。笔者的公司有 AI 翻译的 API,大多数场景下 Qwen 就够用了。语音转文字、内容摘要、客服对话——这些占企业 AI 使用量 80% 以上的场景,根本没有上 Opus 4.6 的必要。用 Opus 4.6 做日常翻译,就像请一个诺贝尔奖得主来批改小学作业。
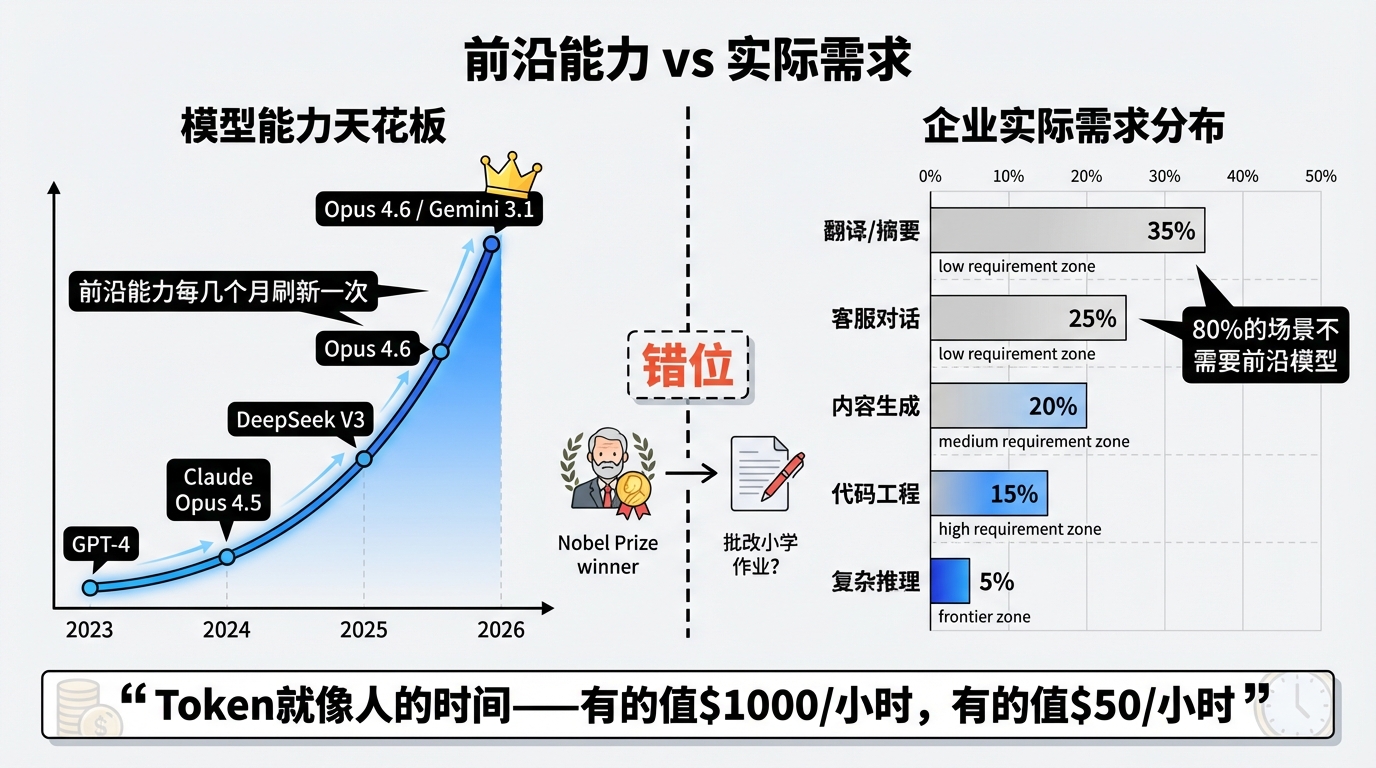
前沿能力与实际需求的错位
这意味着什么?前沿模型的能力天花板在不断升高,但大部分真实业务场景的需求天花板并没有同步升高。 当"够用"的模型越来越便宜甚至免费,前沿模型的优势就被压缩到越来越窄的高端场景里。中国模型不需要在所有维度上追平 Opus 4.6——只需要在 80% 的场景里"够用且便宜",就能拿走大部分市场。
不过,有一个领域中国确实撕开了一角:视频生成。
ByteDance 的 Seedance 2.0 在 2 月 10 日发布,音视频联合生成、导演级镜头控制、多镜头叙事——在多个评测中超过了 Sora 2 和 Veo 3.1。这不是"追平",是局部领先。ByteDance 做短视频出身,TikTok/抖音的内容生态提供了其他竞争对手无法复制的反馈回路。
但 Seedance 2.0 有一个耐人寻味的细节:全球 API 迟迟没有开放。 原定 2 月 24 日的全球 API 发布推迟了,目前只在中国市场的"即梦"平台上可用。官方说法涉及版权争议,但更深层的原因可能是——生成视频消耗的算力远超文本,而算力瓶颈从芯片层一路传导上来。模型做出来了,但没有足够的算力大规模服务全球用户。
这恰好呼应了前几篇的判断:芯片层的裂缝不会消失。它沿着蛋糕向上传导,在每一层打折扣。 模型层的性能可以通过效率创新追近,但模型层的产能——能同时服务多少用户、能多快响应——仍然受制于下面两层。
所以模型层的图景比"中国追上了"更复杂:开源模型追平甚至局部领先,高端闭源模型差距依然明显,产能受芯片层制约。 这三件事同时为真。
理解了这个背景,再来看中国模型为什么能追得这么快。
约束催生效率
答案藏在约束本身里。
芯片受限,意味着中国团队不能用"堆算力"的方式暴力训练。他们必须在有限资源下把效率拧到最高。这种约束反而逼出了一系列工程创新。
MoE(混合专家架构):MoE 不是中国发明的,但中国团队在资源受限下把它用到了极致。DeepSeek-V3 有 671B 参数,但每个 Token 只激活 37B——不到总参数的 6%。相当于你有一栋 100 层的大楼,但每次只开 6 层的灯。推理计算成本大幅降低,性能却接近全参数模型。
蒸馏:用大模型的输出来训练小模型。这就像一个学生不需要从零自学,而是直接学习一个优秀老师的解题思路——学习成本低得多,但考试成绩可以很接近。DeepSeek 早期靠这个方法以极低成本做出了接近 GPT-4 水平的模型,后续的 V3 更是把蒸馏和自研架构结合到了新高度。
强化学习优化:DeepSeek 率先在推理模型上大规模使用强化学习,让模型学会"思考过程"而不只是记住答案。这个方法论上的突破不依赖硬件规模,而依赖算法设计。
在资源约束下被逼出来的系统性工程优化。中国 AI 团队把"每单位算力能产出多少智能"这个效率指标推到了全球前列。
Stanford HAI 的数据显示,自 2022 年以来,AI 推理成本下降了 280 倍以上。中国团队是这个趋势的主要推动者之一。
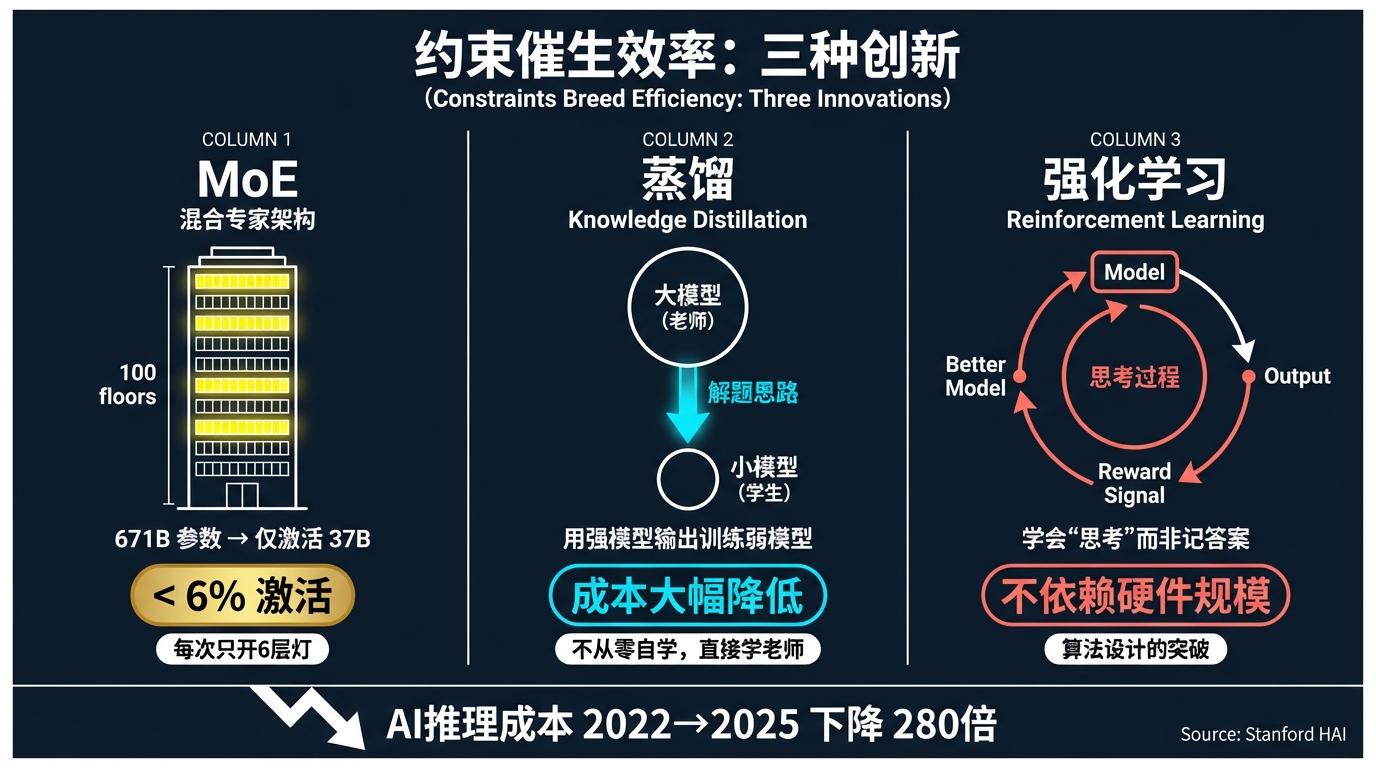
约束催生效率:MoE、蒸馏、强化学习三种创新
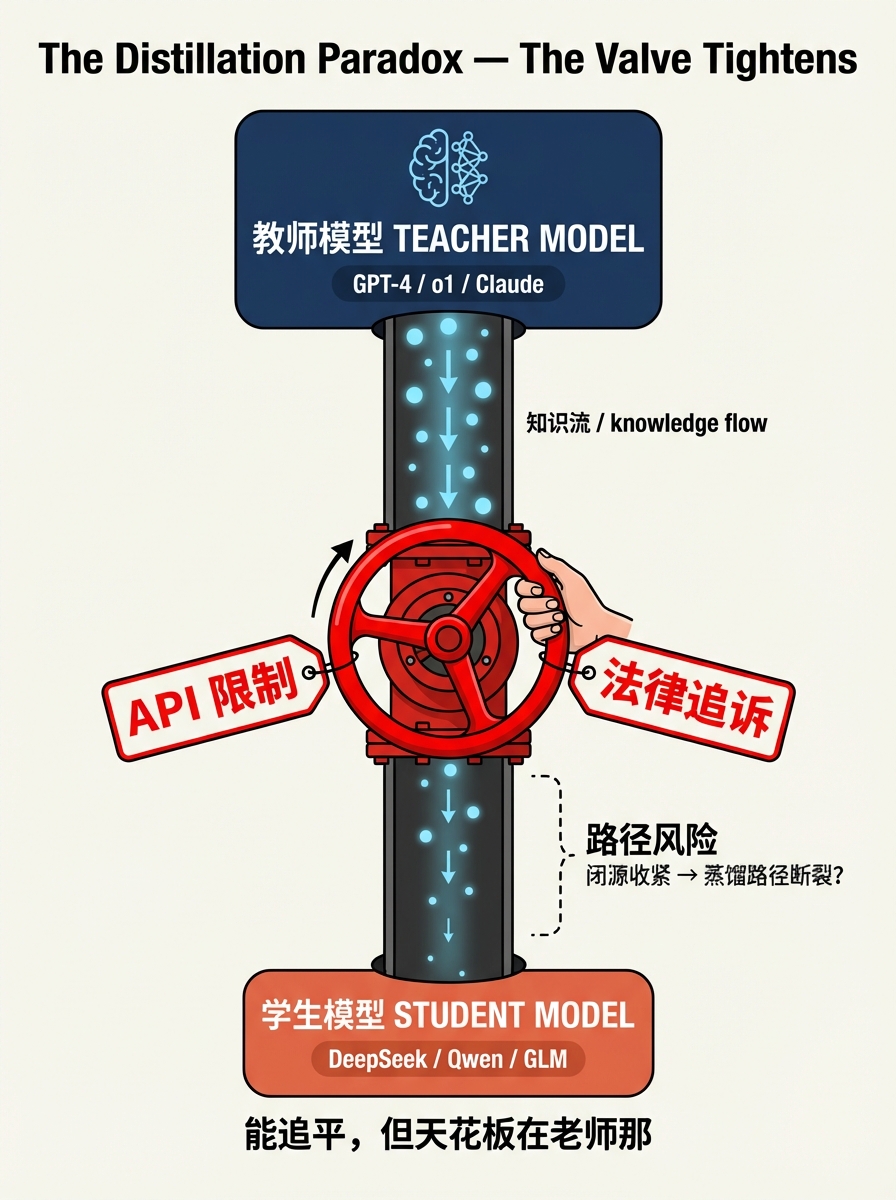
蒸馏悖论
但蒸馏这条路有一个深层矛盾。
蒸馏的逻辑是:用已有的强模型的输出来训练新模型。DeepSeek 用 OpenAI 的 o1 来生成推理数据,再用这些数据训练自己的模型。OpenAI 已经在美国国会正式指控 DeepSeek 蒸馏其模型——"DeepSeek 的下一个模型应该在其持续搭便车的背景下被理解。"
这里面有两个问题。
第一,天花板问题。 学生可以通过学习老师的解题思路来提高成绩,但很难超过老师。蒸馏模型可以在特定基准上追平甚至超过教师模型(通过专项优化),但在通用能力的前沿——比如发明下一个 Transformer 级别的架构突破——蒸馏做不到。Hassabis 的判断很关键:"中国能在基准测试上追平,但还没有证明他们能超越前沿。"
第二,路径依赖问题。 如果蒸馏依赖前沿闭源模型的存在,那当 OpenAI、Anthropic、Google 进一步收紧 API 访问、加强输出水印、在法律上追究蒸馏行为——这条路可能被堵。OpenAI 已经明确禁止用其输出来训练"模仿前沿 AI 模型"。
当然,蒸馏只是中国模型崛起的一个因素,不是全部。MoE 架构创新、强化学习方法论、数据工程效率——这些不依赖蒸馏。DeepSeek 的 V3 模型在预训练阶段就展示了独立的技术突破。一旦开源模型足够强,蒸馏的"教师"可以是开源模型本身,不再依赖闭源 API。
蒸馏悖论的结论不是"中国模型全靠抄",也不是"蒸馏完全没问题"。而是:这条路径有真实的效率优势,也有真实的天花板和风险。它能让你追平前沿,但不一定能让你定义前沿。
蒸馏悖论:追平前沿的路径与局限
Android 打法
如果说蒸馏是追平性能的手段,开源就是抢占市场的战略。
中国模型几乎全部走开源路线。Qwen 3.5 用 Apache 2.0,DeepSeek 用 MIT License,GLM-5 也是 MIT License。对比之下,OpenAI 的核心模型闭源(虽然后来也发布了 gpt-oss 系列),Anthropic 和 Google 的前沿模型也是闭源为主。
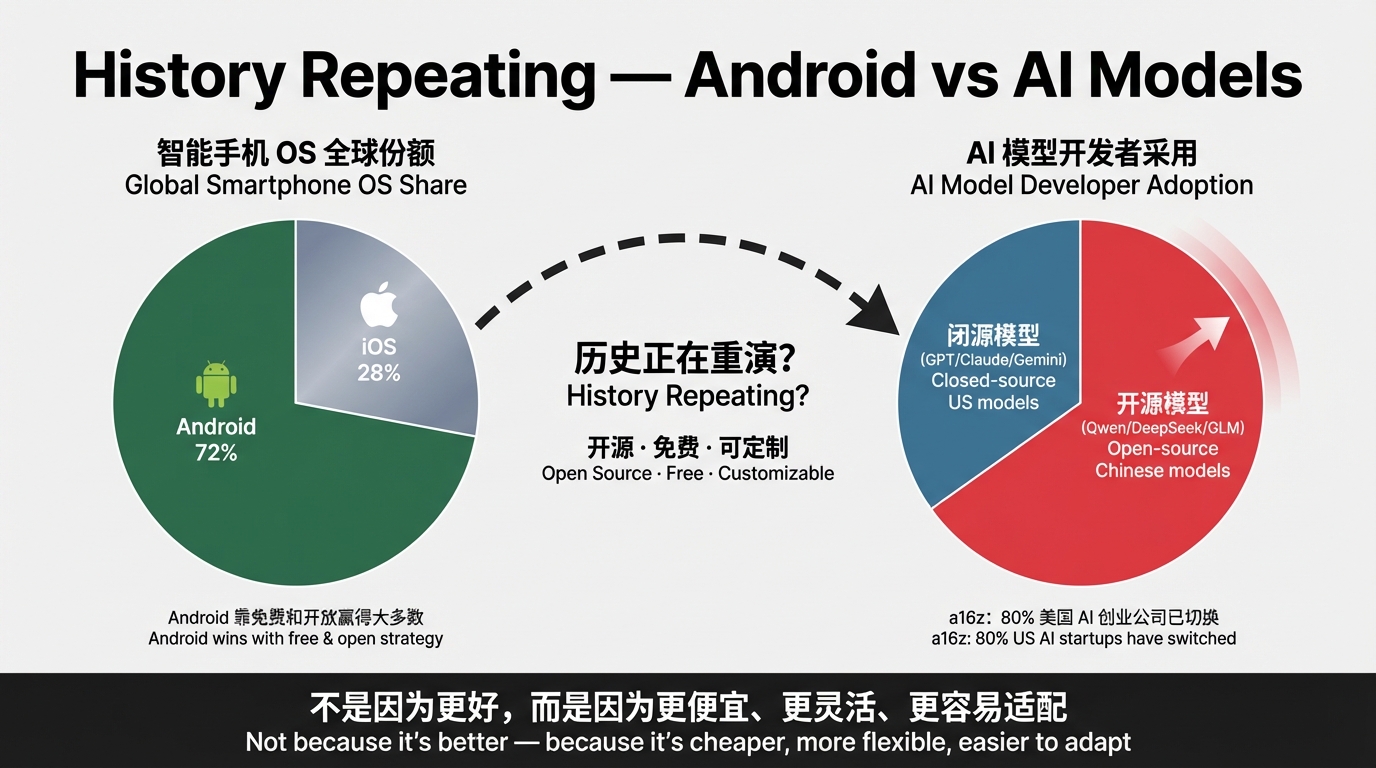
这像极了 Android vs iOS 的剧本。
iOS(闭源模型):体验更好、更安全、但贵,且开发者被锁在生态里。 Android(开源模型):免费、可定制、可本地部署,开发者自由度高。
Android 最终拿了全球 70%+ 的智能手机份额。不是因为它比 iOS 更好,而是因为它更便宜、更灵活、更容易适配不同硬件和市场。
中国开源模型正在走同样的路。HuggingFace 趋势榜上,中国模型(DeepSeek、Qwen、GLM)长期占据主导。a16z 说 80% 的美国 AI 创业公司不再用 OpenAI 或 Anthropic 的模型。RAND 报告显示,中国模型在发展中国家和与中国关系紧密的国家渗透率最高——30 个国家超过 10%,11 个国家超过 20%。
但 Android 打法也有 Android 的问题。很多企业不敢用中国开源模型——不是性能问题,是信任问题。
这个信任问题的本质比大多数人以为的更深。
表面上看是数据安全。中国模型带有审查偏向(敏感话题的回避),开放权重不等于完全透明,无法排除模型输出被刻意调控的可能性。但 Qwen 是开源的,你可以下载权重、本地部署,数据不出你的服务器——理论上没有数据安全问题。企业还是不敢用。为什么?
因为合规不是技术判断,是政治判断。一个美国银行的 CTO 选了中国模型,出了任何事——哪怕和模型完全无关——他面对的第一个问题就是"你为什么选了中国的"。没有人会因为选了 AWS 上的 Claude 被问责,但选了阿里云上的 Qwen 就要写报告。这不是性能差距,是选择的政治成本不对称。
再深一层:数据合规框架本身就是地缘政治工具。GDPR、美国的 CLOUD Act、中国的数据出境安全评估办法——这些法律表面上保护公民数据,实际效果是把数据主权和技术栈绑定在一起。你用了哪国的模型,就隐性地接受了那国的数据治理逻辑。
所以数据合规不是技术壁垒,是信任壁垒。而信任壁垒的底层是主权壁垒。 它和芯片制裁是同一件事的两面——芯片制裁卡的是供给侧(你不能造),数据合规卡的是需求侧(你不敢用)。中国模型在性能上可以追平,在价格上可以更低,但在信任上——这个成本是写在国旗上的,工程优化解决不了。
在受监管的行业(金融、医疗、政府),这个信任成本足以抵消所有价格优势。在不那么敏感的行业和发展中国家市场,价格优势仍然可以压过信任成本——这也是为什么 RAND 报告显示中国模型在发展中国家渗透率最高。
开源的全球份额在扩大,但闭源在高价值客户中的地位也没有动摇。两条路径可能长期共存,就像 Android 和 iOS 今天仍然共存一样——但分界线不是性能,是信任;不是技术,是主权。
不过,Android 的类比还藏着一层更深的含义。
中国没有办法禁用 Android。不是因为信任 Google,是因为整个移动生态——应用、开发者、供应链——已经长在 Android 上了。禁用的成本远大于信任的风险。当一个开源标准渗透到足够多的开发者工具链、企业内部系统、和基础设施里,它就从"可选项"变成了"事实标准"。到了那个临界点,信任成本不是被解决了,而是被"没得选"覆盖了。
中国开源模型正在走这条路。Qwen 已经是 HuggingFace 上下载量最大的开源模型家族。当越来越多的东南亚开发者在 Qwen 上训练自己的垂直模型、越来越多的非洲创业公司用 DeepSeek API 构建产品、越来越多的中东企业在阿里云上跑 Qwen——生态依赖就在形成。一旦形成,切换成本就会逐渐超过信任成本。
信任壁垒是真实的,但它不是永恒的。解法不是去说服别人信任你,而是让你的标准变成事实标准,让"不用你"的成本比"信任你"的成本更高。
Android打法:开源渗透力与主权信任壁垒
商品化的终局
前面说了两件看似矛盾的事:前沿模型越来越强也越来越贵(Opus 4.6),同时大部分场景根本不需要前沿模型。这两件事合在一起,指向一个结论。
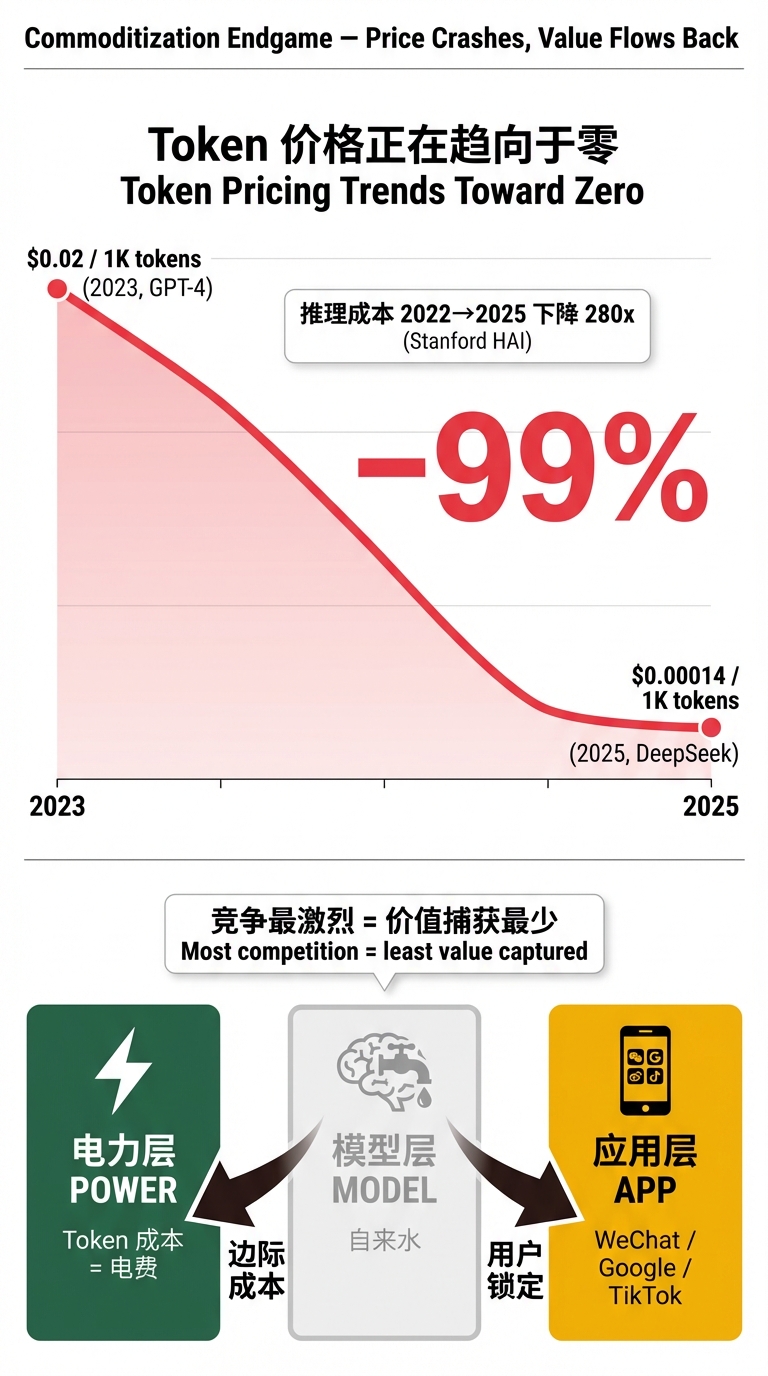
模型层正在快速商品化。
Token 价格的证据最直接:2023 年初,使用大模型的成本是 0.00014/千个输入 Token。两年跌了 99%。
这个趋势的驱动力是多方面的:MoE 降低推理成本、蒸馏降低训练成本、开源模型消除授权费、硬件效率持续提升。所有力量都指向同一个方向——模型的价格趋向于零。
Constellation Research 的分析师直说了:"模型的可能价格是免费。"
如果模型趋向于免费,那"谁的模型更好"就不再是竞争的核心问题。当所有人都能获得 GPT-4 级别甚至更强的模型能力——通过开源下载或者极低价 API——差异化就不在模型本身了。
差异化在哪?回到了下面三层。
谁能最便宜地运行这些模型?——回到电力层。Token 的边际成本归根到底是电费。中国的水电优势在这里再次出现。
谁能以最低延迟把推理结果交付给用户?——回到云层。数据中心的地理位置、网络带宽、部署效率。
谁能把模型嵌入用户每天使用的产品里?——往上看应用层。这才是锁定用户的地方。
商品化终局:Token价格崩塌与价值层转移
模型层是五层蛋糕里最热闹、最受关注、竞争最激烈的一层。但恰恰因为竞争太激烈、迭代太快、开源太普及——它可能是价值捕获最少的一层。
最不性感的地方
写模型层的过程中,有几个想法不断浮现,和模型本身无关,但可能比任何基准测试都重要。
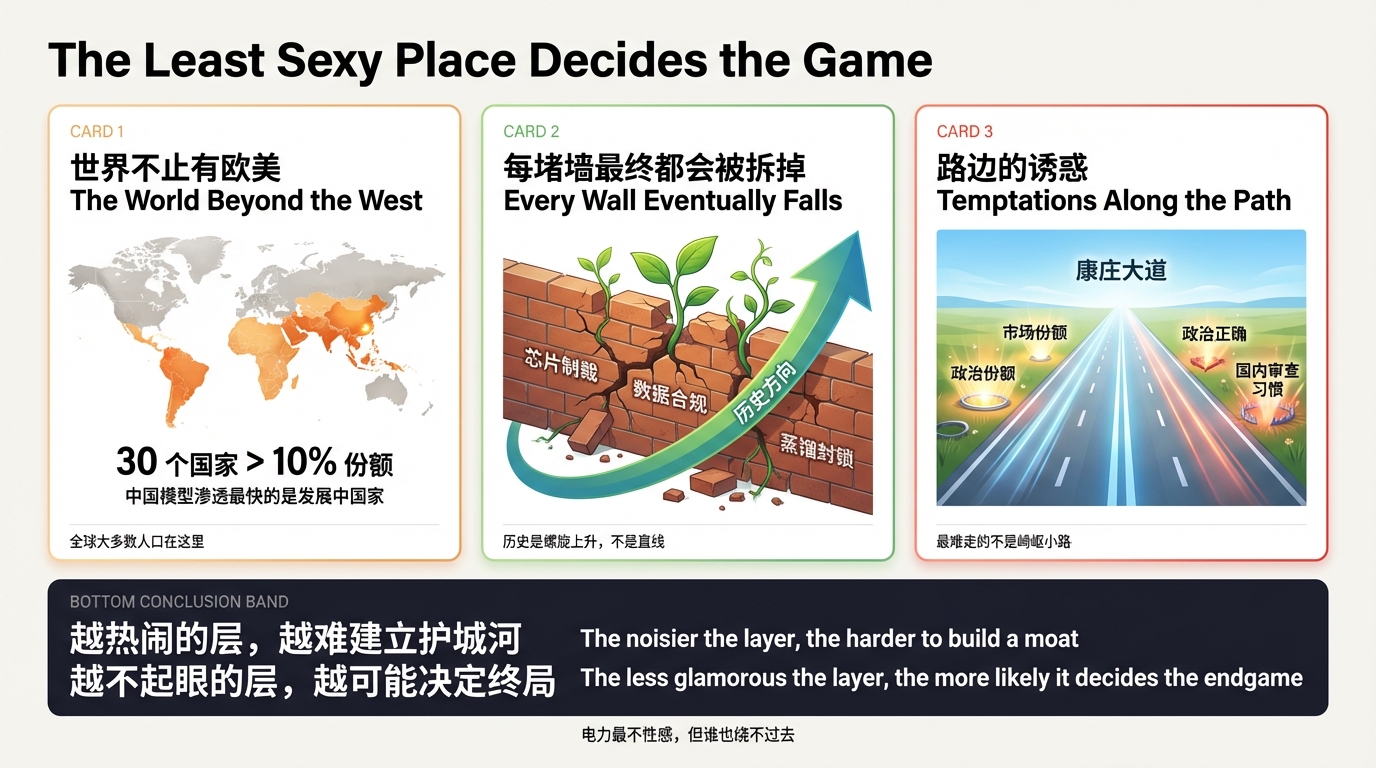
第一,世界不止有欧美。 很多分析把目光锁死在硅谷和欧洲,好像只有发达国家市场才值得争。但 RAND 的数据已经说明了——中国模型渗透最快的是发展中国家,30 个国家超过 10% 的份额。东南亚、中东、拉美、非洲——这些地方加在一起,是全球大多数人口。它们的消费能力在增长,数字化速度不比发达国家慢,而且它们对"美国标准"没有天然的忠诚。忽略这些市场,就像只看一楼的客厅却忘了整栋大楼有二十层。
第二,从人类发展的角度看,每一条阻碍效率的墙最终都会被拆掉。 芯片制裁、数据合规壁垒、蒸馏封锁——这些都是真实的墙,但历史上没有哪堵技术封锁的墙是永恒的。只是历史并不总是线性发展。它不是一条直线向上的斜坡,而是螺旋式上升的结构——有回退,有绕路,有看似倒退的弯道,但长期方向是效率更高、成本更低、覆盖更广。
第三,也是最想说的一句:世界上最难走的路,可能不是那条泥泞挣扎的崎岖小路,而是康庄大道上,草丛边藏着一个又一个的诱惑。 中国模型目前面临的最大风险不是"追不上"——蒸馏、MoE、开源已经证明追得上。最大的风险是在份额快速扩张的过程中,被短期增长的诱惑带偏:为了市场份额牺牲模型安全、为了政治正确扭曲模型输出、为了国内审查习惯而失去全球开发者的信任。这些诱惑不会一次性出现,而是一个接一个地藏在路边,每一个看起来都很合理,但累积起来就偏离了方向。
四层写下来,一个规律变得越来越清楚:越热闹的层越难建立护城河,越不起眼的层越可能决定终局。
越热闹的层越难建立护城河:三个反直觉洞见
电力最不性感,但它决定了 Token 的边际成本下限,谁也绕不过去。模型最热闹,但它正在变成自来水——打开水龙头就有,没人在意水是从哪条管道来的。
上面还有最后一层:应用。
如果模型是免费的,那价值在哪里?在把模型变成十亿人每天使用的产品里。搜索、电商、社交、办公、支付——谁能把 AI 嵌入这些高频场景,谁就锁定了用户。
这恰恰是中美各自最强的领域。中国有微信、支付宝、抖音、淘宝。美国有 Google、Apple、Microsoft、Meta。
下一篇,最后一层。五层蛋糕的顶部。