Sonnet 正在吃掉 Opus 的午餐
Sonnet 正在吃掉 Opus 的午餐
2025 年 2 月 17 日,Anthropic 发布了 Claude Sonnet 4.6。官方的定位很克制:"最强的 Sonnet 模型"。但从实际数据看,这个版本的意义远不止 Sonnet 产品线的一次迭代——它正在系统性地侵蚀 Opus 的领地。
Claude Code 的早期测试给出了一个让人意外的数字:用户在 59% 的情况下更偏好 Sonnet 4.6,而不是 2025 年 11 月发布的旗舰模型 Opus 4.5。理由也不是"差不多就行"的妥协,而是 Sonnet 4.6 在具体维度上做得更好——更少的过度工程、更少的虚假成功声明、更好的指令遵循和多步骤任务的完成一致性。
这意味着模型选型的旧逻辑正在失效。
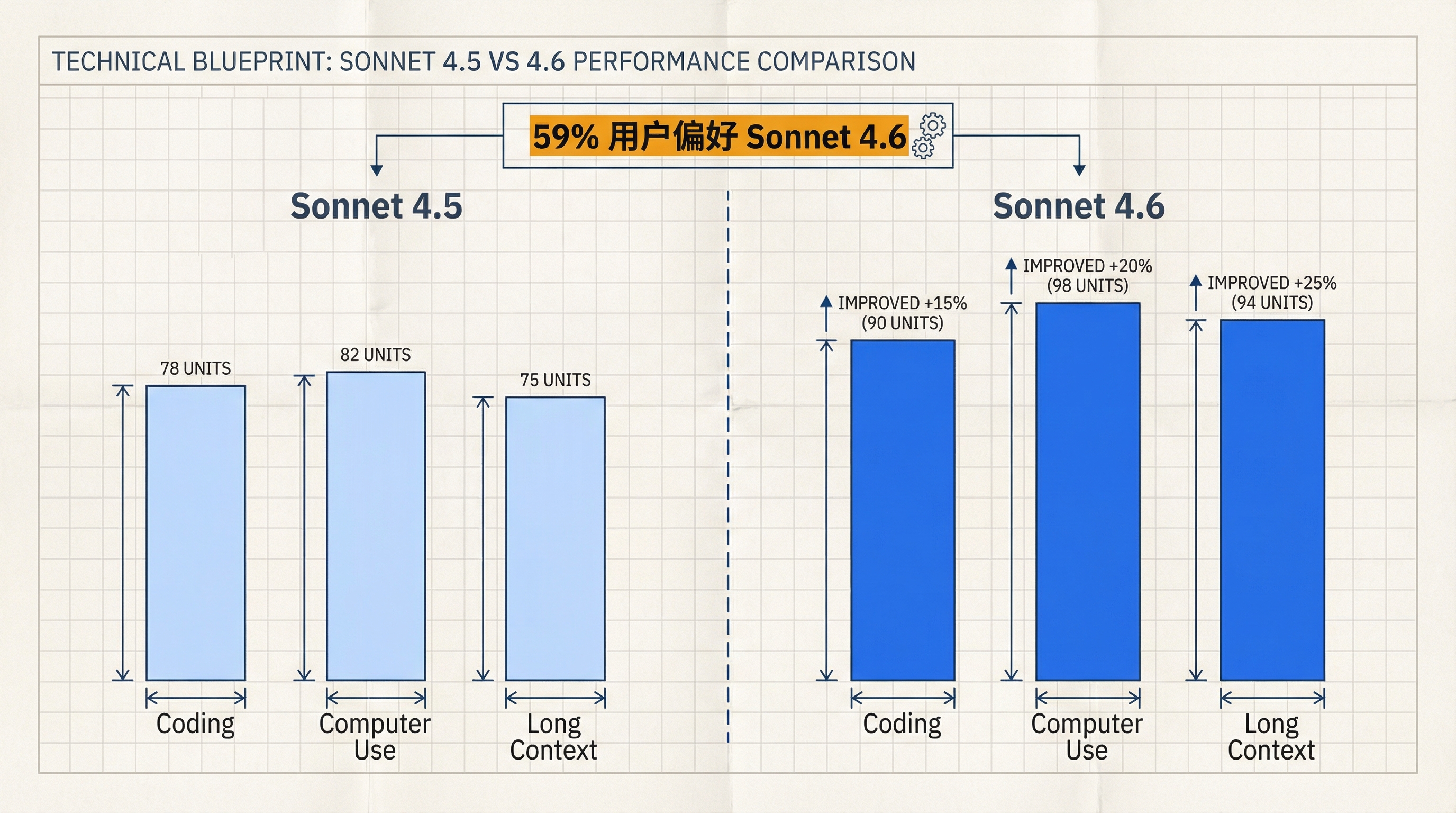
Sonnet 4.5 vs 4.6 性能对比
价格不变,能力跃迁
Sonnet 4.6 的 API 定价保持在 15 per million tokens,和前代 Sonnet 4.5 完全一致。这个定价策略本身就是一个信号:Anthropic 不是在推一个新的价格档位,而是在同一个价格档位里塞进了质的提升。
从 benchmark 数据看,Sonnet 4.6 在多个维度上逼近甚至匹配 Opus 级别。Databricks 的 CTO 确认,Sonnet 4.6 在 OfficeQA(企业文档理解评测)上的表现已经匹配 Opus 4.6。Box 的测试显示,在重推理 Q&A 任务上 Sonnet 4.6 超出 Sonnet 4.5 达 15 个百分点。Hebbia 在金融服务基准测试中观察到答案匹配率的显著提升。
更有意思的是 Vending-Bench Arena 的表现。这个评测让不同 AI 模型在模拟商业环境中竞争,比拼谁能创造更高利润。Sonnet 4.6 展现出了一种此前未见的策略行为:前 10 个模拟月份激进投入产能扩张,花费远超竞争对手,然后在最后阶段急转弯聚焦盈利。这种延迟满足式的策略规划能力,通常只在顶级模型中出现。
Computer use:从实验品到生产力工具
Computer use 的进步是另一条值得关注的线索。2024 年 10 月 Anthropic 首次推出通用计算机使用能力时,官方自己的评价是"实验性的,笨拙且容易出错"。16 个月过去,Sonnet 系列在 OSWorld 基准上的得分稳步攀升。
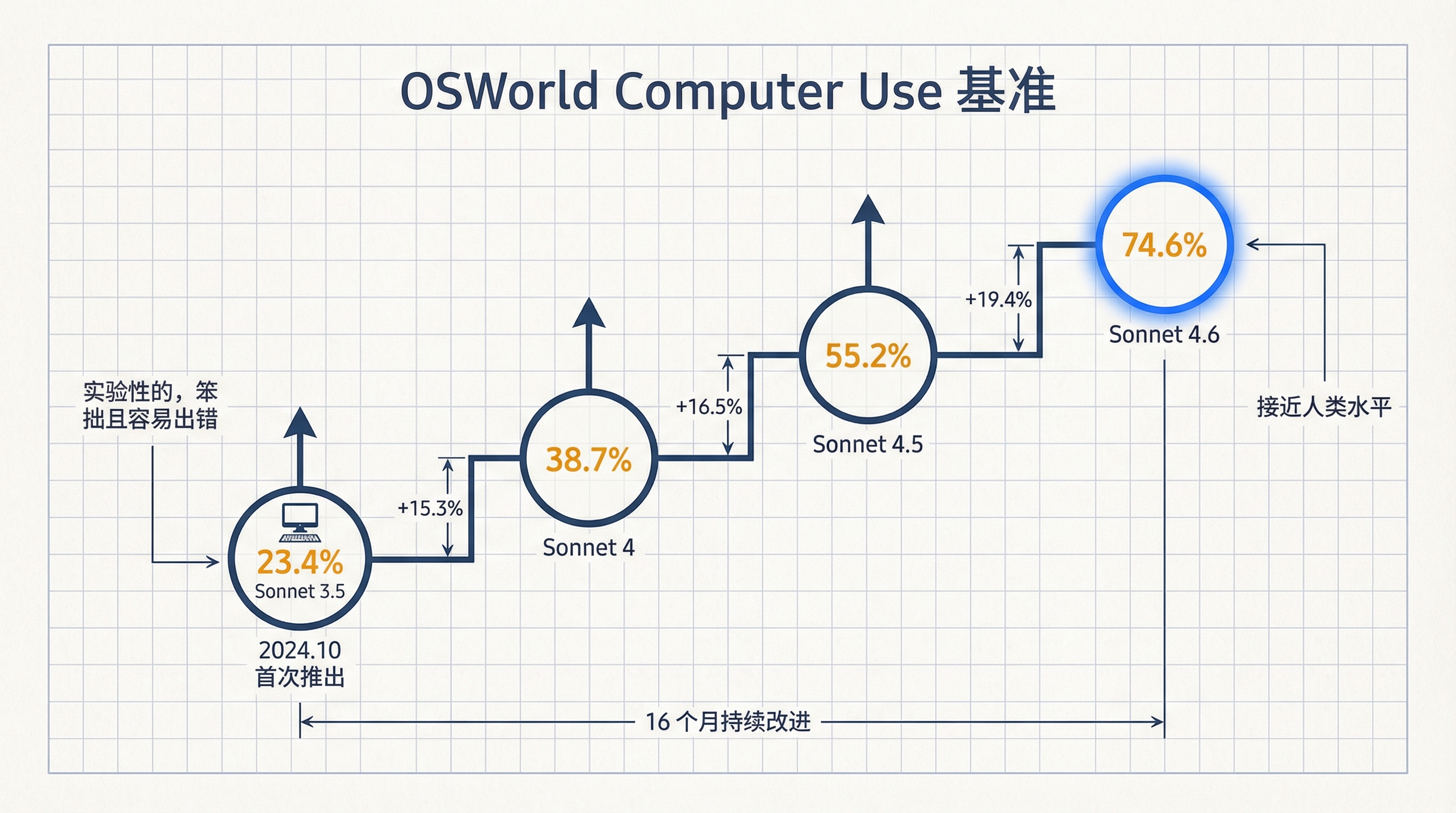
Sonnet 系列 OSWorld 进化轨迹
OSWorld 测试的是真实软件环境中的计算机操作——Chrome、LibreOffice、VS Code,没有特殊 API,模型通过虚拟鼠标和键盘与界面交互。早期用户反馈,Sonnet 4.6 在复杂表格操作和多标签页浏览器任务上已经接近人类水平。
同样重要的是安全层面的改进。Computer use 天然面临 prompt injection 风险——恶意网页可以通过隐藏指令劫持模型行为。Anthropic 的安全评估显示 Sonnet 4.6 在抵抗 prompt injection 方面相比 Sonnet 4.5 有大幅提升,达到了 Opus 4.6 的水平。对于计划在生产环境中部署 agent 的团队来说,这个改进直接影响可行性评估。
100 万 token 上下文窗口的实际意义
Sonnet 4.6 的上下文窗口扩展到 100 万 token(beta),这个数字本身不新鲜——竞品也有类似规格。关键在于 Anthropic 强调的是"在整个上下文中有效推理",而不只是"能塞进去"。
这两者的差距在实际应用中天差地别。能塞进 100 万 token 但只对最近的内容有效推理,和真正能跨越整个上下文做关联分析,是完全不同的能力。Sonnet 4.6 在 Vending-Bench Arena 中展现的长期策略规划能力,某种程度上就是长上下文推理能力的体现——模型需要记住 10 个月前的投资决策来调整当前策略。
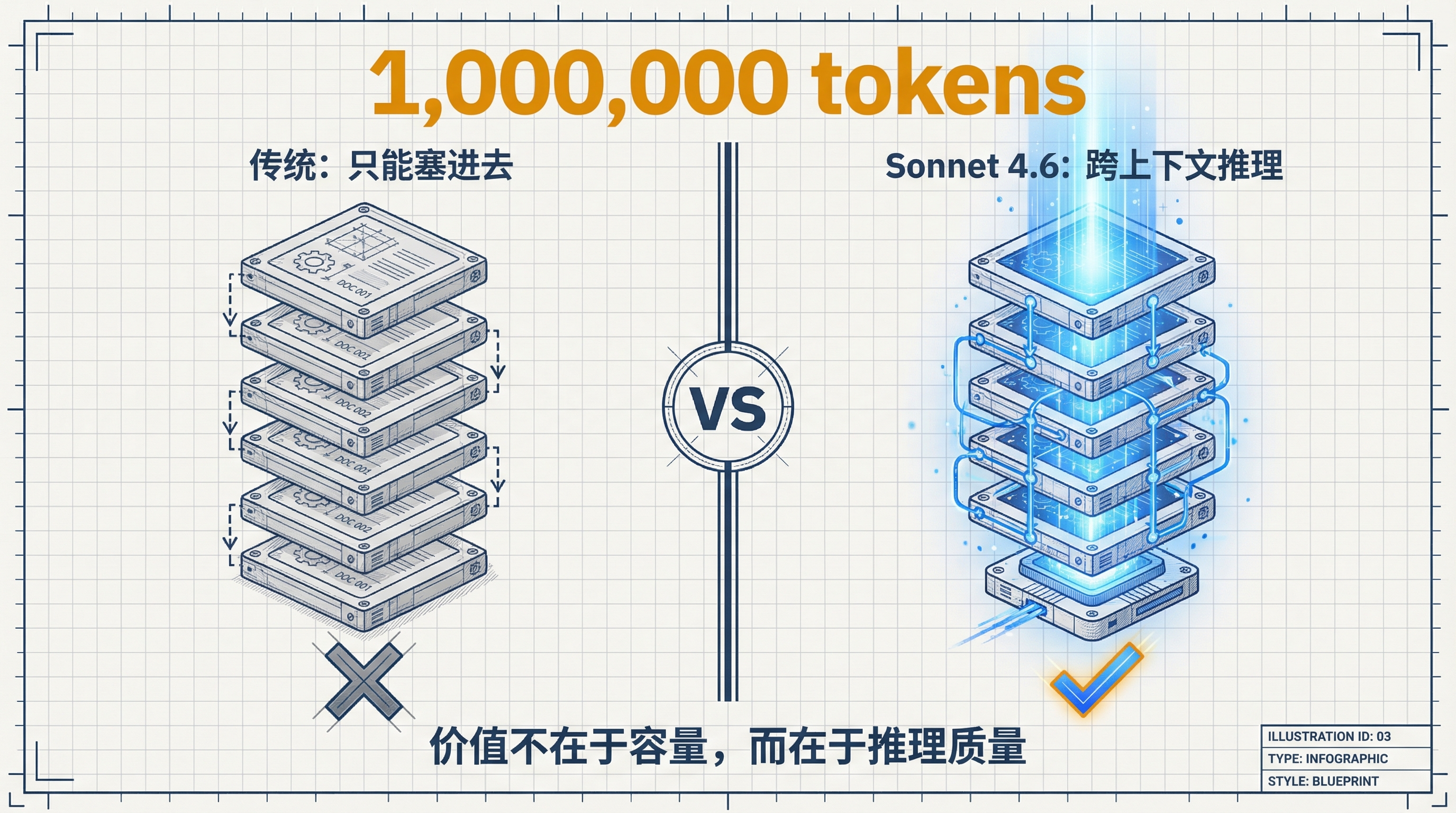
百万 token 有效推理
配合同步推出的 context compaction 功能(自动压缩旧对话上下文),Sonnet 4.6 的有效上下文利用率进一步提升。这对长会话场景的 agent 应用尤其关键。
对开发者模型选型的实际影响
Sonnet 4.6 的发布让模型选型的决策树变得更简单,也更微妙。
更简单的部分:对于大多数编码、文档理解、agent 任务,Sonnet 4.6 是默认选择。价格只有 Opus 的几分之一,性能在多数场景下已经够用甚至更好。Anthropic 自己的迁移建议也印证了这点——先用 Sonnet 4.6 关闭 thinking 试试,不够再升级。
更微妙的部分:Opus 4.6 的定位从"全能旗舰"收窄到了"极致推理"。Anthropic 明确指出 Opus 仍是"最深度推理任务"的最优选——代码库重构、多 agent 协调、必须一次做对的高风险场景。这不再是"更好的模型",而是"特定类型问题的专家"。
对于正在构建 AI 产品的团队,实际的建议是:
- 默认路由到 Sonnet 4.6,绝大多数任务在这一层解决
- 只在推理密度极高的任务上升级到 Opus 4.6
- 利用 adaptive thinking 让模型自动调整思考深度,而不是手动选模型
- Computer use 场景可以开始认真评估生产部署了,但要做好 prompt injection 的防御测试
核心要点
Sonnet 4.6 的发布不只是一次模型更新,它反映了 Anthropic 产品策略的清晰方向:
- 性能民主化:Opus 级能力正在系统性地下放到 Sonnet 价位,"够用就行选 Sonnet"的心智正在被"Sonnet 就是最佳选择"取代
- Computer use 进入实用阶段:16 个月的持续改进加上 prompt injection 防御的增强,让 agent 部署从实验走向可评估
- 长上下文的价值在于推理质量:100 万 token 窗口配合有效的跨上下文推理,解锁了真正的长期规划和复杂分析场景
- 模型选型从"级别"转向"任务特征":不再是简单的 Sonnet vs Opus 二选一,而是根据推理密度和容错要求做精确匹配
- 模型 ID
claude-sonnet-4-6,API 定价 15 per million tokens,直接替换即可