一块不能编程的芯片,凭什么跑赢所有 GPU
当大模型被刻进晶体管
上一篇我写 Token 是电力的出口形态,有人问:如果算力成本也能降到接近零呢?这周 Taalas 把 Llama 刻进了芯片,我觉得那个"如果"正在变成现实。
一条让我停下来的新闻
上周刷到一条消息:一家叫 Taalas 的加拿大公司,把 Meta 的 Llama 3.1 8B 模型直接蚀刻进了芯片的晶体管里。
不是"把模型加载到芯片上运行"。是把模型的权重变成了物理晶体管本身。32 层 Transformer,每一层都是硅片上的物理电路。用户输入进来,电信号从第 1 层的晶体管流到第 32 层,中间不经过任何外部存储器,直接在导线上完成推理。
结果是:每秒 17000 个 Token。GPU 方案大概 1800。快了将近 10 倍。
建造成本是 GPU 方案的 1/20。功耗是 1/10。
没有 HBM(高带宽内存),没有先进封装,没有液冷系统。这些在当前 AI 硬件里占大头成本的东西,全部不需要了。
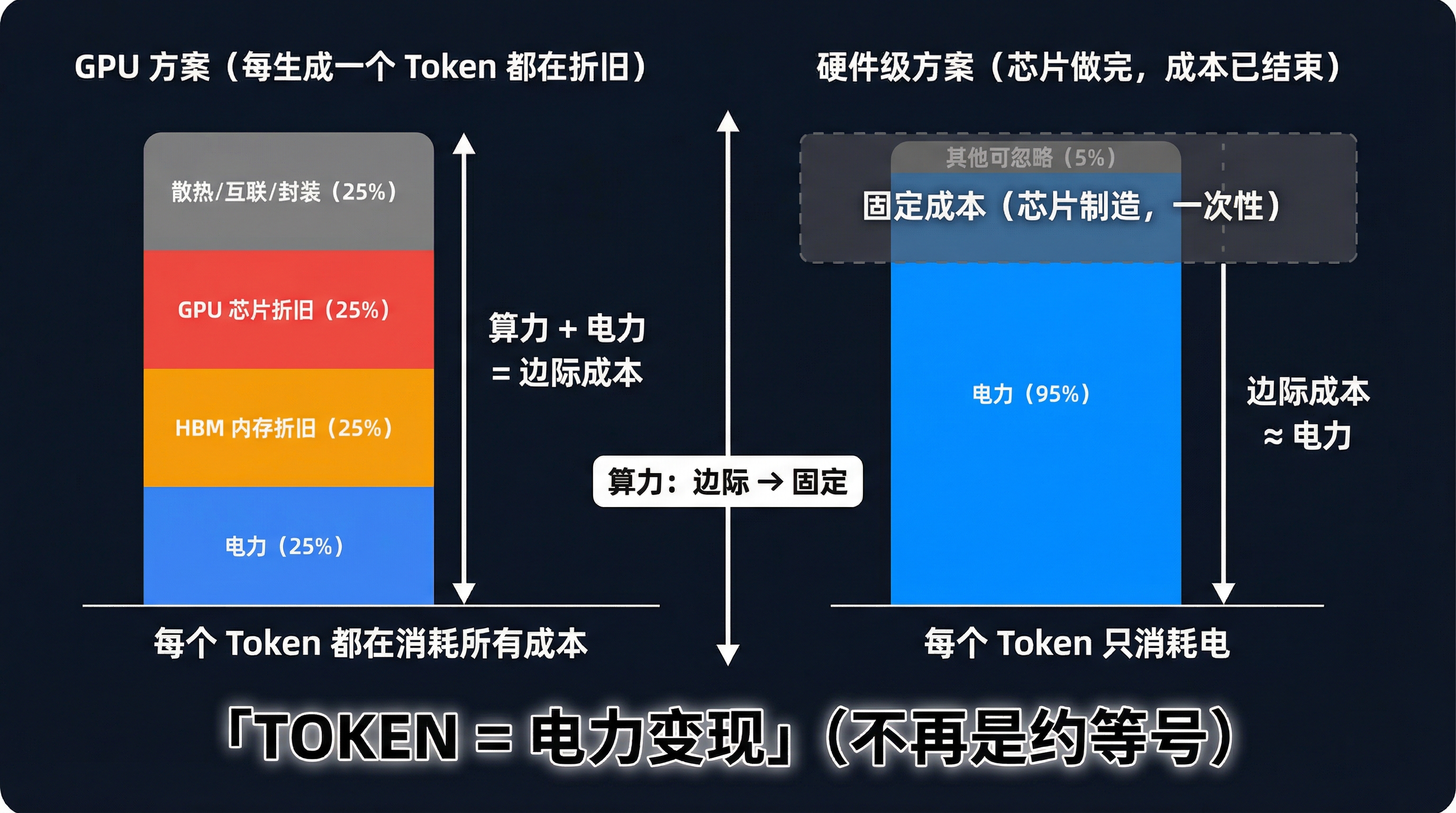
我看到这条新闻的第一反应不是"好快",而是回想起自己上一篇文章里的一句话:Token 的边际成本中,算力加电力占 70% 以上。
如果 Taalas 这条路走通了,这个比例会变成什么?

Taalas vs GPU 关键指标对比
当算力变成固定成本
在 GPU 方案里,Token 的边际成本有两大块:算力和电力。算力不只是 GPU 本身的价格,还包括 HBM 内存、散热系统、高速互联——这些加在一起,可能比 GPU 芯片本身还贵。每生成一个 Token,这些硬件都在折旧,都在计入边际成本。
Taalas 做的事情,是把"算力"从边际成本项变成了固定成本项。
芯片制造完成的那一刻,所有的硬件投入就结束了。之后每生成一个 Token,消耗的只有电。没有内存读写的功耗,没有数据搬运的开销,电信号在晶体管间流过,就是全部的成本。
上一篇我说 Token ≈ 电力变现。在硬件级大模型的世界里,这个约等号可以拿掉了。Token = 电力变现。
Token 边际成本结构:GPU方案 vs 硬件级方案
这听起来像是一个技术细节的差异,但经济含义完全不同。当 Token 的边际成本几乎只剩电费,电力成本在 AI 竞争中的权重就不是"重要",而是"唯一"。谁的电便宜,谁的 Token 就便宜,中间几乎没有其他变量了。
但我很快就意识到,事情没有这么简单。
一个致命的问题
Taalas 的芯片有一个根本性的约束:它只能跑一个模型。
Llama 3.1 8B 被刻进去了,这块芯片就永远是 Llama 3.1 8B。等 Llama 4 出来,芯片不能升级,只能报废。Taalas 说他们从拿到模型到完成芯片只需要两个月,但两个月在 AI 行业是很长的时间——DeepSeek 从发论文到全球爆火也就一个月。
这让我想到了一段计算机史。
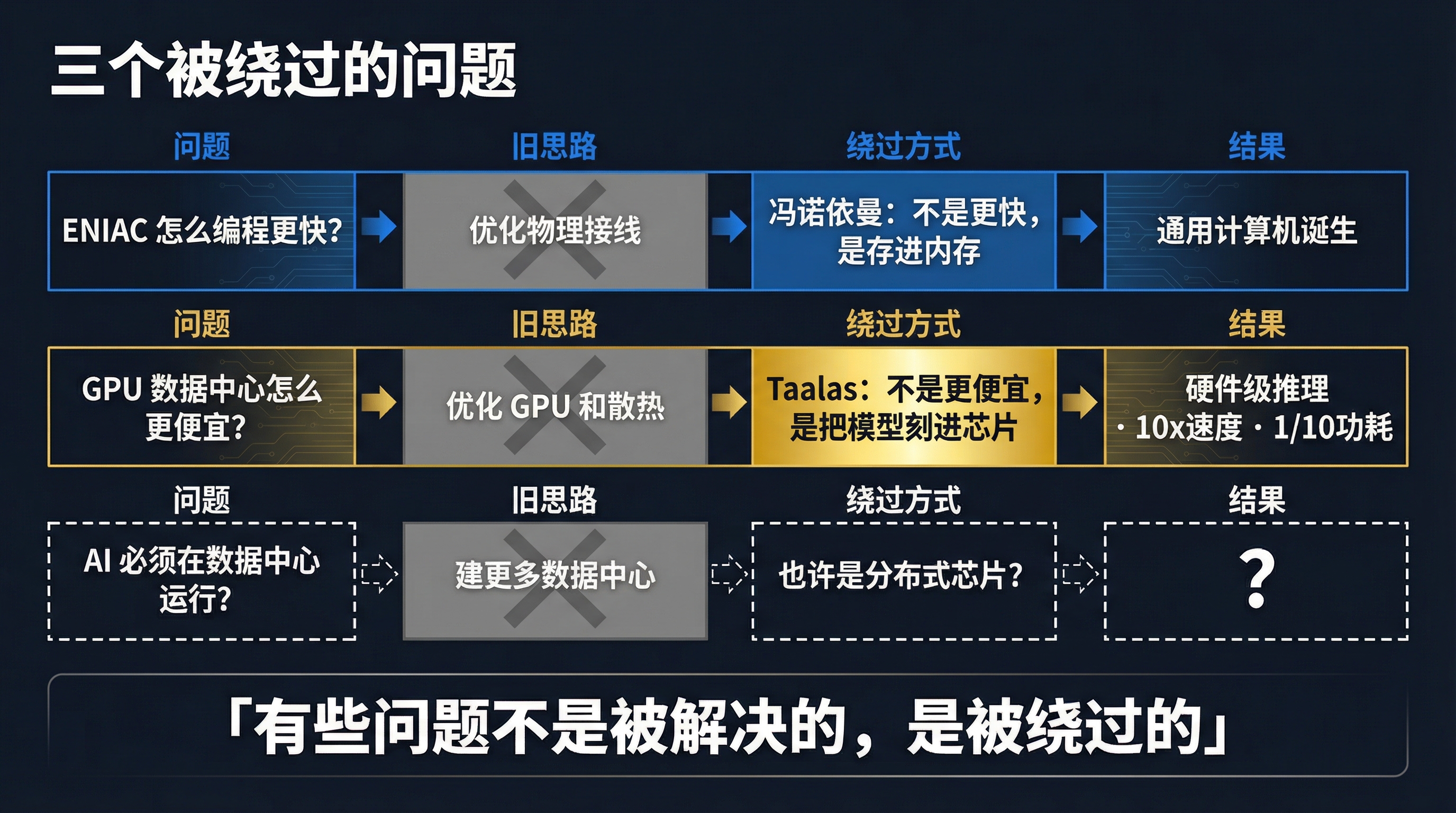
ENIAC、冯诺依曼、和一个还没被回答的问题
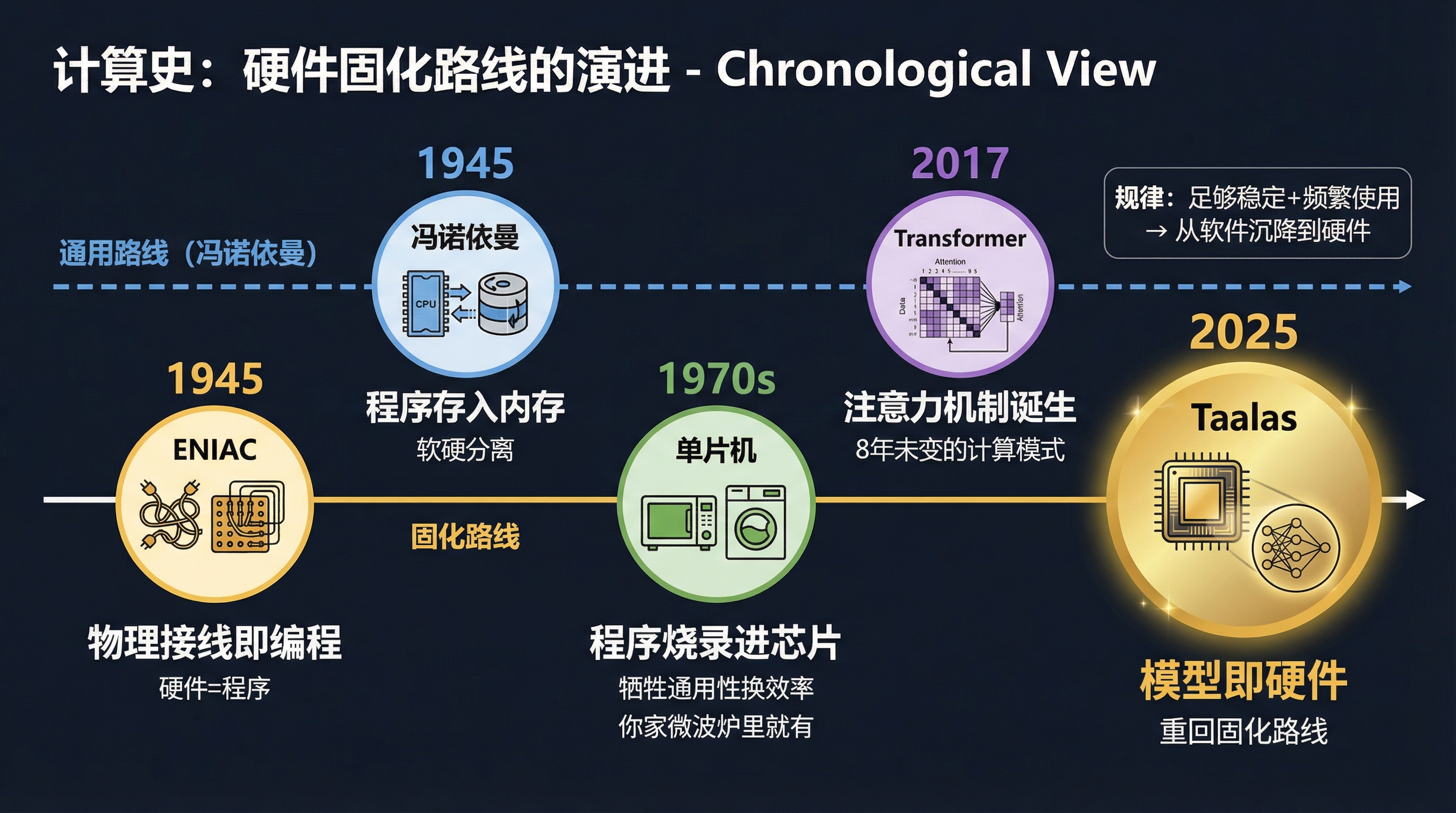
1945 年,ENIAC 是世界上第一台通用电子计算机。但"通用"这个词有点名不副实——ENIAC 的编程方式是物理接线。你要算一个新问题,就得重新插拔电缆、调整开关,可能要花几天时间。程序和硬件是绑定的。
听起来是不是很像 Taalas?模型就是硬件,硬件就是模型。
冯诺依曼在 1945 年提出了一个关键的架构思想:把程序和数据一起存储在内存里,让计算机可以通过读取不同的程序来执行不同的任务。从此,硬件和软件分离了。你不需要为每个新任务重造一台计算机。
这个思想奠定了之后 80 年计算机发展的基础。从大型机到 PC,从 PC 到智能手机,底层都是冯诺依曼架构的延续——通用硬件,可编程软件。
但有意思的是,在计算机发展的过程中,"刻进硬件"这条路从来没有完全消失。
单片机就是一个中间形态。程序烧录进芯片,不像 ENIAC 那样需要物理接线,但也不像 PC 那样随时换程序。它牺牲了通用性,换来了极致的效率和成本——所以你家的微波炉、洗衣机、遥控器里面都是单片机,不是 PC。
CPU 本身也有"刻进去"的部分。常用的指令集(x86、ARM)是固化在硬件里的,因为这些指令足够稳定、使用频率足够高,把它们做成物理电路比每次用软件解释快得多。
规律是:当一个计算模式足够稳定、使用频率足够高时,它最终会从软件沉降到硬件里。
所以真正的问题不是"Taalas 的方案能不能用",而是:大模型的哪些部分已经足够稳定,值得被刻进硬件?
计算史:硬件固化路线的演进
大模型的分层稳定化
现在的大模型迭代很快。Llama 3 到 3.1 到 4,GPT-3.5 到 4 到 4o,每一代的架构、参数规模、注意力机制都可能变化。把整个模型刻进芯片,等于赌这个模型至少在芯片的生命周期内不会被淘汰。
但如果换一个角度想——模型不需要作为整体被刻进去。
我最近越来越觉得,大模型的使用方式正在从"一个大模型做所有事"转向一种分层结构:
一个足够聪明的大模型负责理解任务、做拆解和调度。这部分需要最新最强的能力,迭代快,适合跑在通用硬件(GPU)上。
拆解出来的子任务被分发给一组专用的小模型去执行。翻译、摘要、代码生成、格式转换——这些任务的模式相对固定,对模型能力的要求也没那么极端。
这些小模型,就是 Taalas 方案的理想目标。
把"翻译 8B 模型"刻进一块芯片,把"代码生成 8B 模型"刻进另一块,把"摘要 8B 模型"刻进第三块。每块芯片只做一件事,但做到极致——17000 tokens/s,近乎零延迟,边际成本只有电。
上面的调度层跑在 GPU 上,负责理解用户意图、拆解任务、分发给对应的硬件芯片。这一层迭代快没关系,因为它跑在通用硬件上,软件更新就行。下面的执行层刻在芯片里,不需要经常变,因为"把中文翻译成英文"这个任务的模式三年后和今天不会有本质区别。
快变的部分留在软件,慢变的部分沉降到硬件。 这不就是计算机 80 年来一直在做的事情吗?

大模型分层架构:调度层 GPU + 执行层专用芯片
Transformer 会是下一个指令集吗?
再往前推一步。
如果说刻整个模型进芯片是"ENIAC 模式"(硬件即程序),那有没有一种中间路径——不刻整个模型,而是把模型里最核心、最稳定的计算模式做成硬件?
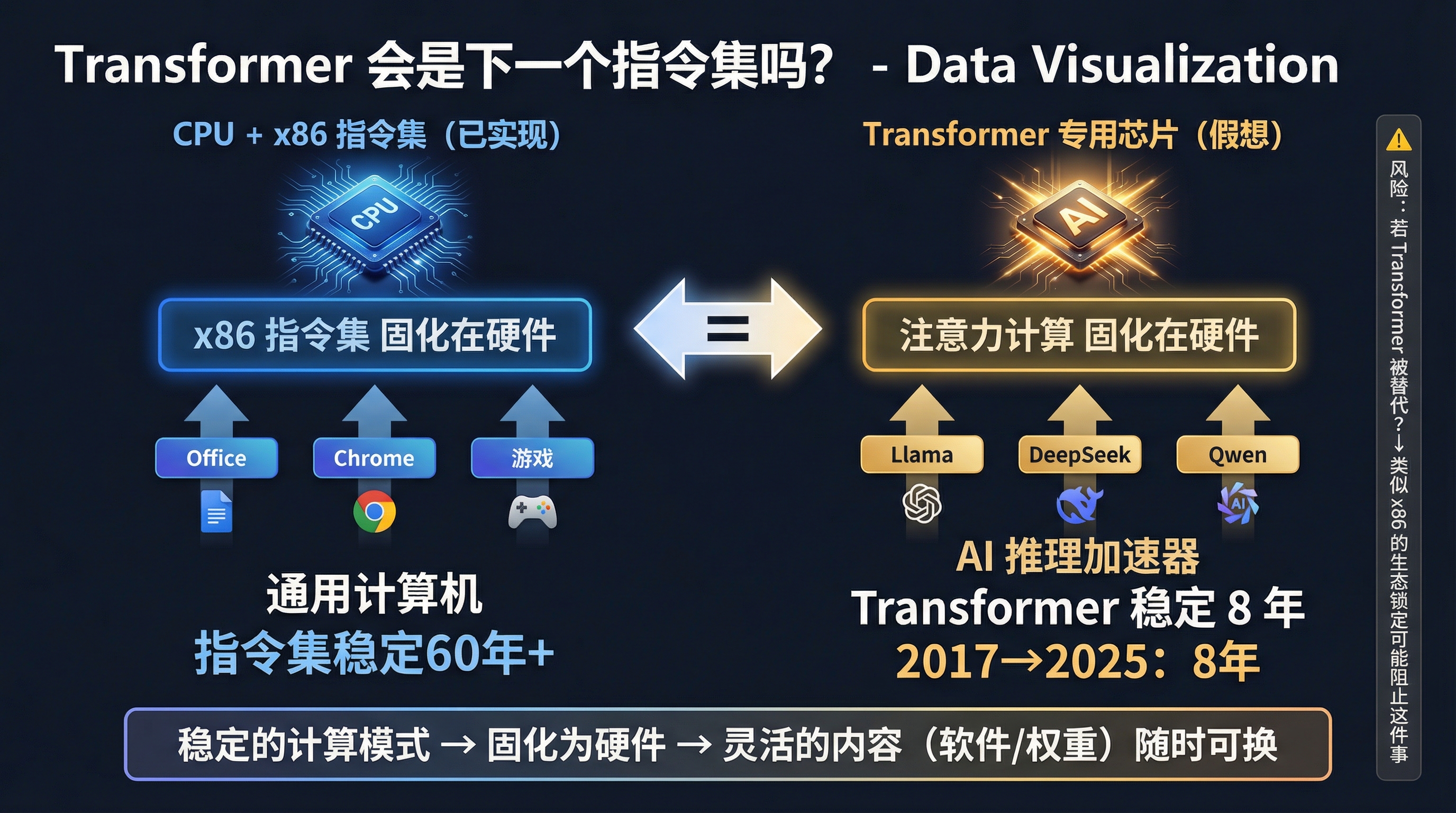
Transformer 架构从 2017 年提出到现在,底层的注意力计算机制基本没变过。不管是 GPT、Llama、DeepSeek 还是 Qwen,底下都是 Self-Attention + Feed-Forward 的组合。变的是层数、参数量、训练方法、注意力的具体变种(MHA、GQA、MQA),但矩阵乘法 + Softmax + 残差连接这套计算模式已经稳定了将近 8 年。
8 年,在 AI 领域是地质年代级别的稳定。
那为什么不把 Transformer 的核心计算模式——注意力计算和前馈网络的矩阵运算——做成硬件电路?就像 CPU 把 x86 指令集固化一样,做一个"Transformer 指令集"的专用芯片。具体的模型参数(权重)通过加载的方式灌进去,但计算逻辑本身是物理电路。
这样的芯片既不像 GPU 那样"什么都能算但什么都不够快",也不像 Taalas 那样"只能跑一个模型"。它是一个针对 Transformer 计算模式优化到极致的硬件平台,任何基于 Transformer 的模型都能在上面高效运行。
Google 的 TPU 某种程度上已经在走这条路。但 TPU 仍然保留了大量通用性。如果进一步激进地砍掉非 Transformer 的能力,效率还能再上一个台阶。
当然,这里有一个风险:如果未来某天 Transformer 被一种全新的架构取代了呢?那这些芯片就和 Taalas 刻死的 Llama 芯片一样,变成废硅。但从目前的趋势看,Transformer 更可能是像 x86 一样——不是没有更好的设计,而是生态锁定太深,迁移成本太高,最终成为事实标准。
Transformer 会是下一个指令集吗?
回到电力
拉回到上一篇的主线。
如果 AI 硬件真的从"通用 GPU 数据中心"走向"专用芯片分布式部署",电力竞争的形态会发生一个微妙但重要的变化。
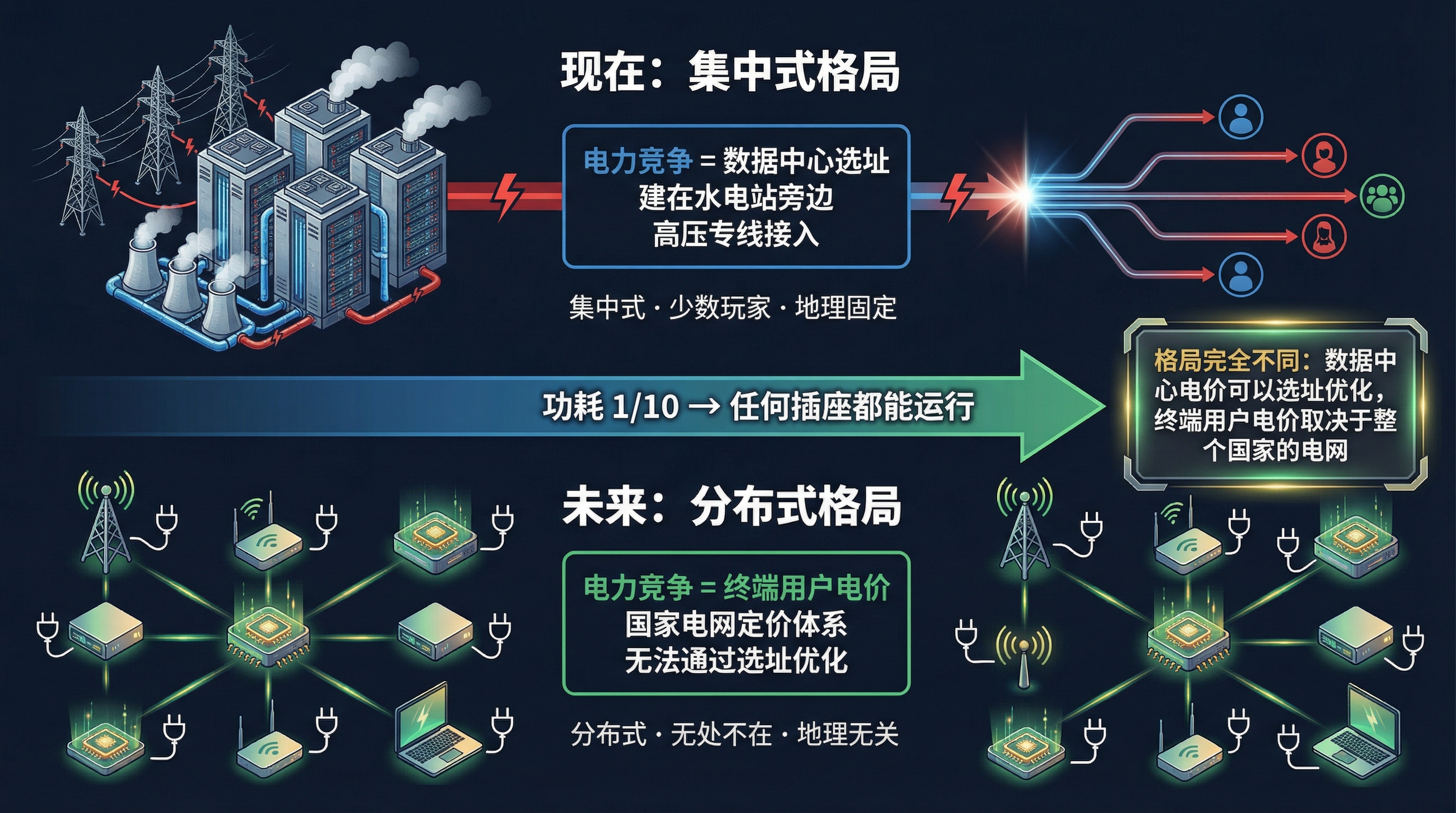
现在的 AI 推理集中在少数大型数据中心里。谁拥有大型数据中心+便宜的电,谁就有 Token 定价优势。这是一个集中式的竞争格局。
但硬件级大模型的功耗极低——Taalas 的方案是 GPU 的 1/10。如果一块芯片就能跑一个完整的推理模型,而且不需要液冷、不需要机柜、功耗可能只有几十瓦,那它完全可以部署在任何有电的地方。边缘设备、基站、甚至家用路由器。
AI 推理从"集中在数据中心"变成"分散在每一个插座旁边"。
这时候电力竞争就不再是"谁的数据中心电价便宜",而是"谁的终端用户用电便宜"。格局完全不同。数据中心的电价可以通过选址优化(建在水电站旁边),但终端用户的电价取决于整个国家的电网效率和定价体系。
AI 电力竞争格局转变:集中式 → 分布式
我现在还不确定这个转变会在什么时间发生。Taalas 的第一代芯片只能跑 8B 参数的模型,离前沿大模型还有很大距离。但方向是清楚的:AI 硬件正在从冯诺依曼架构的通用路线,重新向"计算模式固化"的方向探索。
我们现在看 AI 硬件的状态,可能就像 1950 年代看计算机——大型机、穿孔卡片、空调房间。所有人都在讨论怎么让大型机更快更便宜,很少有人在想:也许未来每个人口袋里都会有一台。
上一篇我说,有些答案不是想出来的,是等来的。
这一篇我想说的是,有些问题不是被解决的,是被绕过的。冯诺依曼没有让 ENIAC 跑得更快,他换了一种思考方式。Taalas 也没有让 GPU 更便宜,它问了一个不同的问题:如果模型本身就是硬件呢?
下一个要被绕过的问题,也许是"AI 必须在数据中心里运行"。
三个被绕过的问题