Web 为谁而建
Web 为谁而建
2026 年 2 月,Cloudflare 宣布了一个看似不起眼的功能:Markdown for Agents。当 AI Agent 在请求头中带上 Accept: text/markdown,Cloudflare 的边缘网络会自动把 HTML 页面转换成 Markdown 返回。一篇博客文章的 token 数从 16,180 降到 3,150,减少了 80%。
这个功能本身并不复杂。但它背后的信号值得琢磨:Web 的消费者正在发生结构性变化,而基础设施已经开始为此调整。
要理解这件事的意义,得先回到一个更基本的问题——HTML 和 CSS 到底是为了解决什么问题。
给人类看的排版系统
HTML 诞生于 1991 年,最初的目的朴素得不能再朴素:让学术论文可以通过网络互相链接和阅读。早期的 HTML 几乎没有样式可言,纯文本加超链接,跟今天的 Markdown 反而更像。
CSS 在 1996 年出现,解决的是一个具体的痛点:人们希望网页能有报纸和杂志那样的排版质量。字体、颜色、边距、浮动布局——这些能力本质上都是在模拟印刷媒体的视觉体验。

从纯文本到富视觉:Web 排版三十年的演进方向始终是"让人类看得更舒服"
从这个起点出发,整个前端技术栈的发展逻辑就很清晰了:一切都是为了让人类更高效地获取信息。
具体来说,这种效率体现在两个维度。
第一个维度是信息密度的管理。一个页面能承载的信息远比一屏所能展示的多,但如果把所有信息一股脑铺出来,人会被淹没。所以 Web 发展出了各种"按需展示"的机制:hover 显示工具提示,click 展开详情面板,scroll 触发懒加载,tab 切换不同内容区域。这些交互模式的本质都是同一个——把信息藏在合理的层级里,让用户在需要的时候才看到。
第二个维度是视觉反馈的优化。动画、渐变、过渡效果、微交互,这些看起来是"花哨"的东西,实际上都在服务一个目标:帮助人类大脑理解界面状态的变化。一个按钮按下去有 ripple 效果,不是为了好看,是为了确认"你的操作被接收了"。一个列表项被删除时有淡出动画,是为了让你的视觉系统跟上 DOM 结构的变化。
这两个维度叠加在一起,构成了今天 Web 体验的核心:用视觉手段管理信息的呈现节奏,让人类大脑在有限的注意力带宽下获得最大的信息吞吐量。
Agent 不需要"看"
问题来了:Agent 不是人。
Agent 不需要渐变色来判断按钮的主次关系,不需要动画来理解状态转换,不需要 hover 效果来发现隐藏信息。对 Agent 来说,一个精心设计的 Web 页面和它的 Markdown 纯文本版本,在信息量上几乎没有区别——但在解析成本上差了一个数量级。
Cloudflare 的数据很直观:同一篇博客文章,HTML 版本 16,180 tokens,Markdown 版本 3,150 tokens。那多出来的 13,000 个 tokens 是什么?<div>、<nav>、<footer>、CSS 类名、JavaScript 引用、SVG 图标、ARIA 标签……全是给人类视觉系统准备的"包装",Agent 完全不需要。
这就是 Cloudflare 这个功能真正触及的问题:过去三十年,Web 的所有复杂性都是为人类视觉系统优化的。当主要消费者变成 Agent 时,这些复杂性从资产变成了负债。
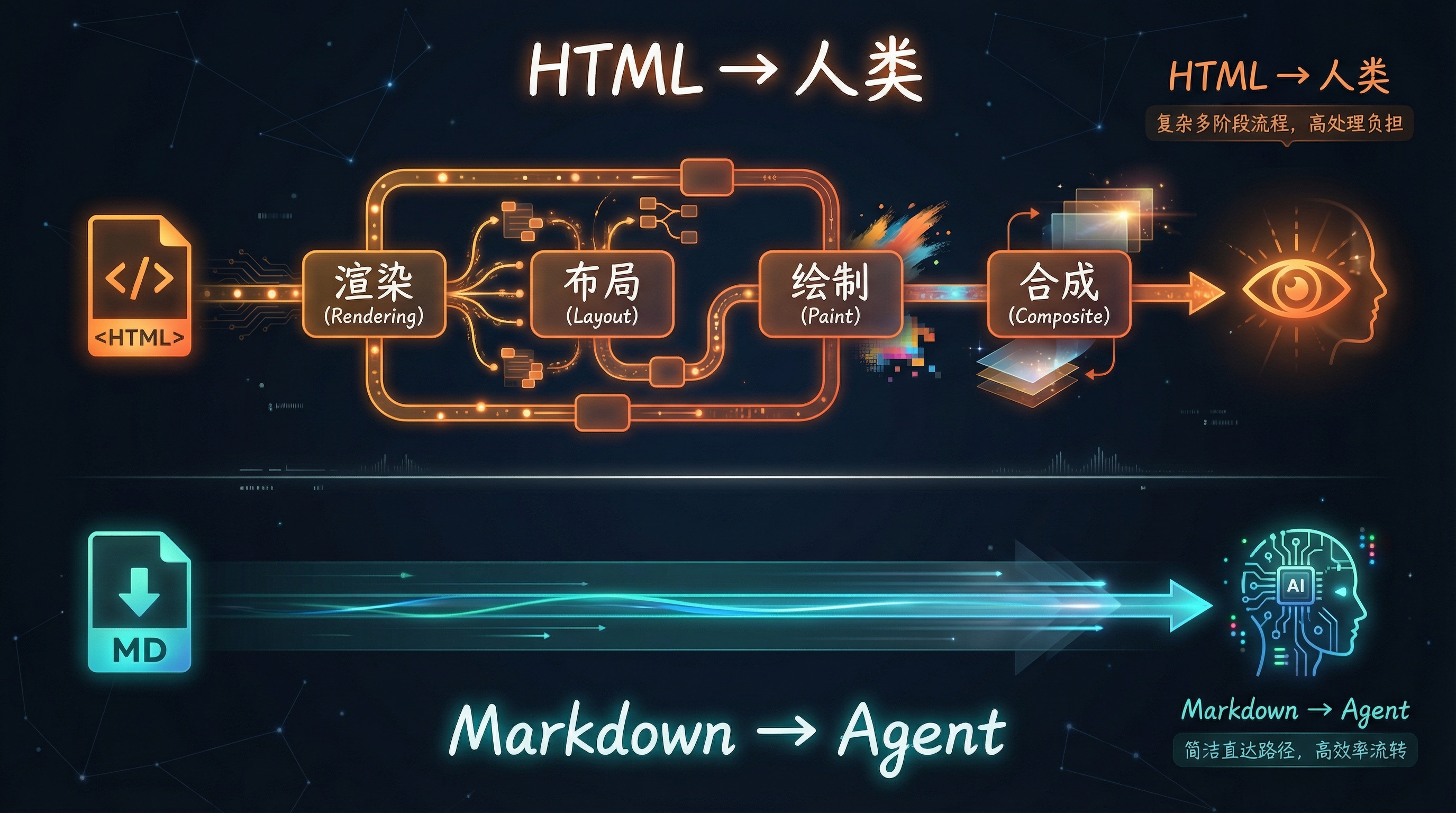
HTML 到人类 vs Markdown 到 Agent:两条完全不同的信息消费路径
而且这不只是效率问题。现在 AI 处理管线的标准做法是:抓取 HTML → 用 BeautifulSoup 或 Trafilatura 之类的工具提取正文 → 转成 Markdown → 喂给模型。每一步都在做同一件事——剥掉那些为人类设计的视觉层,还原出底层的纯信息结构。Cloudflare 做的事情是把这个剥离过程前移到了 CDN 边缘,让 Agent 一步拿到它真正需要的东西。
有意思的是,这形成了一个奇妙的循环:Web 从 Markdown 式的纯文本出发,花了三十年加上层层视觉包装变成复杂的 HTML+CSS+JS 体系,现在又开始往回走,为 Agent 重新提供 Markdown。
范式转移:从"人看网页"到"Agent 看网页"
Claude Code 和 OpenCode 这类编程 Agent 已经在请求头里默认带上了 Accept: text/markdown。这不是实验性行为,而是生产环境的标准配置。
这个趋势如果继续发展,会带来几个层面的变化。
内容层面:Web 可能会演化出两套并行的内容表达——一套面向人类的富视觉版本,一套面向 Agent 的结构化纯文本版本。Cloudflare 的方案是在边缘自动转换,但更彻底的做法可能是内容源头就维护两个版本,就像现在网站会同时维护 HTML 页面和 RSS feed 一样。
交互层面:这里有更大的想象空间。目前 Agent 主要是"读"网页——抓取信息、做摘要、回答问题。但下一步很可能是"操作"网页——Agent 代替人类点击按钮、填写表单、完成交易。到那个阶段,Agent 不仅需要 Markdown 形式的内容,还需要结构化的交互描述——哪些是可操作元素,操作的前置条件和预期结果是什么。
未来的可能形态:Agent 作为中间层,从原始 Web 到个性化界面
体验层面:最激进的可能性是,人类不再直接访问原始网页。Agent 替你访问多个数据源,提取你需要的信息,然后以一个全新的、为你个人定制的界面呈现出来。你不需要在电商网站的 SKU 列表里翻找,Agent 直接告诉你"根据你的需求,这三个选项最合适,区别在这里"。你不需要在政府网站的层层菜单里找表格,Agent 直接把表格拉出来,填好你的基本信息,等你确认提交。
这个场景下,原始网站的 UI 设计、交互体验、品牌视觉——这些曾经是核心竞争力的东西——都变得不那么重要了。重要的是你的内容结构是否对 Agent 友好,你的 API 是否开放且规范,你的数据是否容易被机器理解和操作。
现实的复杂性
当然,从当前状态到那个未来还有很长的路,并且路上布满了现实问题。
SEO 领域已经开始警觉。Cloudflare 把 Accept: text/markdown 请求头原封不动地转发给了源站服务器,这等于告诉源站"这个请求来自 AI Agent"。源站完全可以针对这个信号返回不同的内容——比如注入对 Agent 有利但对用户不可见的营销信息。Google 的 John Mueller 直接表达了对这种 "cloaking" 风险的担忧。
商业模式也面临挑战。如果用户不再直接访问网站,广告怎么展示?品牌怎么曝光?流量统计怎么做?Cloudflare 自己也在小心翼翼地平衡——一方面提供 Markdown for Agents 让 AI 访问更高效,另一方面又通过 Content Signals Policy 让站长可以声明"允许 AI 训练但不允许 AI 直接引用"之类的细粒度权限。
还有信任问题。Agent 替你操作网页,你怎么确保它操作的是正确的?它看到的 Markdown 版本和你看到的 HTML 版本内容一致吗?在 Agent 成为人和 Web 之间的中间层之后,这个中间层本身的可信度就成了新的问题。
Web 作为"信息 API"
回头看,Web 的演进路线其实一直有两条暗线在交织。
一条是表现力的增强:从纯文本到富媒体,从静态页面到单页应用,从桌面到移动端响应式——始终在追求更好的人类感官体验。
另一条是结构化的回归:RSS、JSON-LD、Schema.org、Open Graph、robots.txt、现在的 Markdown for Agents——始终在尝试让机器也能理解 Web 内容。
过去这两条线的权重差距很大,表现力那条线占绝对主导。但 Agent 时代到来后,结构化这条线的权重正在快速上升。
Cloudflare 选择在 CDN 边缘做 HTML 到 Markdown 的转换,是一个务实的过渡方案。它不要求站长改任何东西,也不要求 Agent 自己做繁重的解析工作。但长远来看,更可能的演进方向是:Web 本身就提供机器可读的结构化层,作为和视觉层平行的一等公民。
Web 不会消失,HTML 和 CSS 也不会消失。只要人类还在用眼睛看屏幕,视觉层就有存在的价值。但 Web 的角色可能会从"人类获取信息的界面"转变为"信息的通用 API"——人类和 Agent 各取所需,用各自最高效的方式消费同一份底层数据。
三十年前 Web 为人类的眼睛而生,现在它需要学会同时为 Agent 的解析器而生。Cloudflare 的 Markdown for Agents 只是这个转变过程中的一个早期信号,但它指向的方向已经足够清晰。