From Writing Code to Writing Rules
In February 2025, Andrej Karpathy coined the term "vibe coding" — describing a mode of development where you "fully give in to the vibes, embrace exponentials, and forget that the code even exists." By the end of the year, the term had been named Collins Dictionary's Word of the Year. But most discourse around vibe coding stays at the surface level: can AI write code or not? Very few people have documented what actually happens when an experienced engineer transitions from semi-manual AI assistance to barely touching a programming language — and what that journey reveals about where software development is heading.
This is that documentation. Not advocacy, not a tutorial — just an evolution record from production environments.
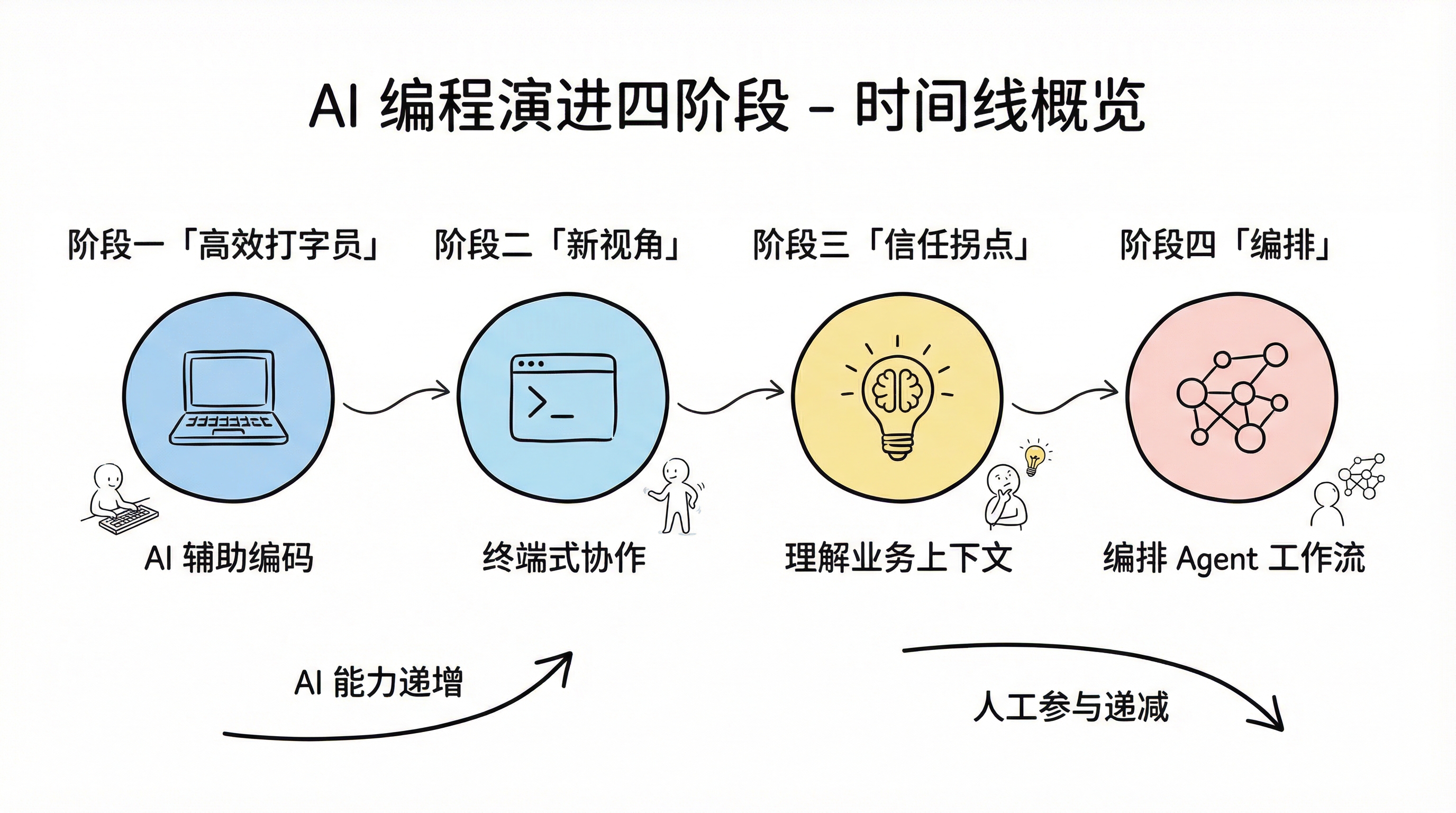
AI programming evolution: four stages timeline overview
Phase One: AI as a Fast Typist
The starting point in early 2025 was Cursor. Its core value was clear: project-level context awareness. Feed it well-structured business logic for a feature, and it would produce code that matched the existing codebase's style and conventions. For standard workflows — CRUD operations, data transformation pipelines — Cursor eliminated significant manual effort.
But the boundaries were equally clear. Debugging was unreliable: it could fix syntax errors but would spiral when facing cross-component state synchronization issues. Complex interactions were worse — any multi-step user flow with conditional branching almost never worked on the first pass. The deeper problem was the absence of business sense. Implicit assumptions like "the user might go back to the previous page to edit their input" were completely beyond AI's ability to infer. That kind of context had to be spelled out at the flowchart level.
The working model at this stage was essentially human brain for architecture and decisions, AI for translation and implementation. The efficiency gains were real, but human involvement remained high.
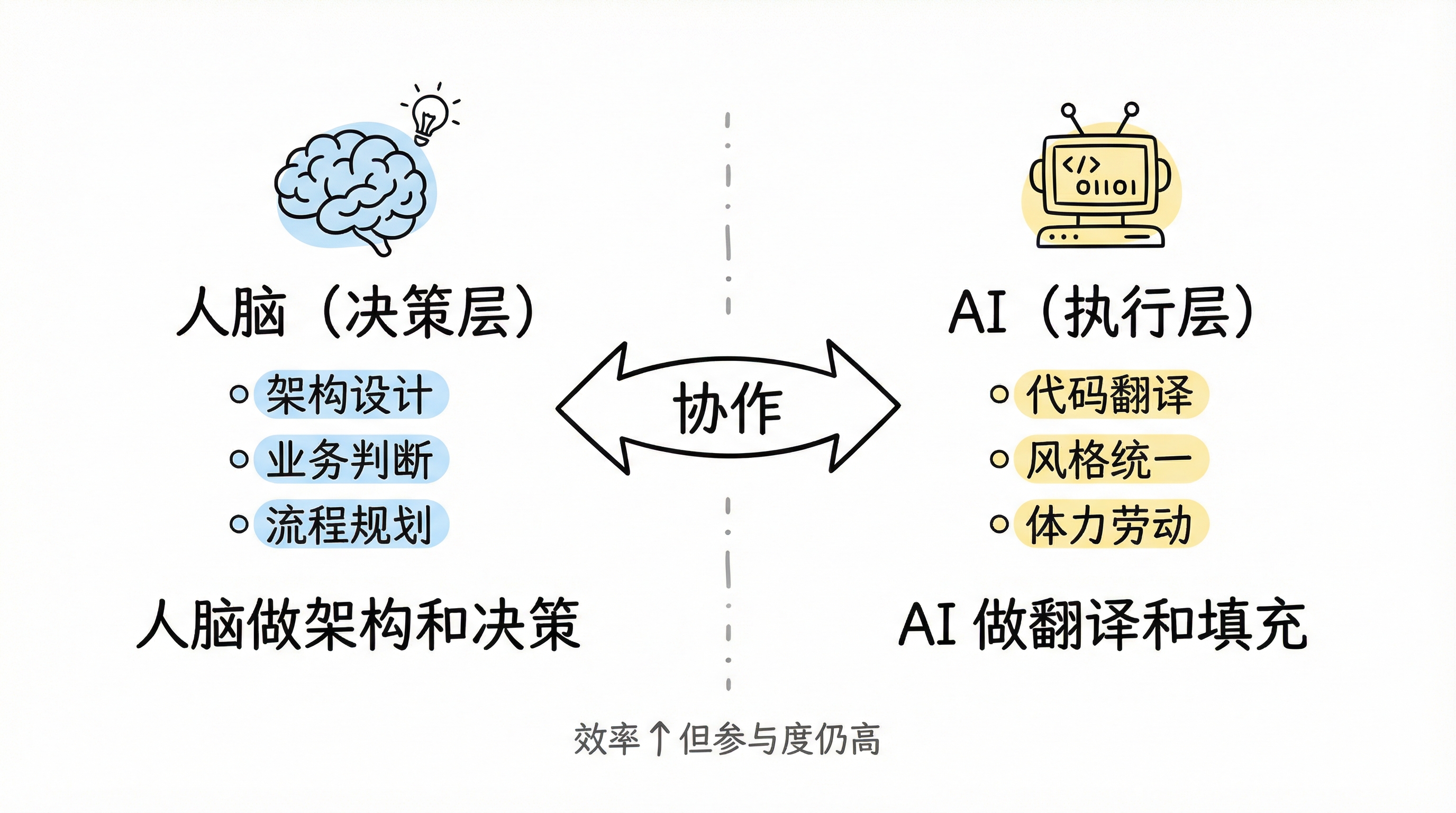
Phase one: human decision layer vs AI execution layer
Phase Two: A New Perspective, Not Yet Enough
Claude Code introduced a fundamentally different interaction paradigm. Unlike Cursor's in-IDE code completion, Claude Code worked like an actual engineer at a terminal — using grep to search logs, sed to batch-modify files, and understanding semantically similar but syntactically different code patterns.
This "engineer-style" operation opened new possibilities. It wasn't just completing code at the cursor — it could actively search, understand, and modify across the project. But in practice, the gap between Claude Code and Cursor was small at this stage. The core bottleneck remained business understanding. It could manipulate code but couldn't grasp the business intent behind it.
This phase was about seeing the potential of a new collaboration model, without being ready to delegate.
Phase Three: The Trust Inflection Point
The real shift came with Claude 4 Opus.
The change wasn't incremental — it was a step function. The most surprising experience wasn't faster code generation but rather that the model began to genuinely understand business context. A concrete example: a code comment described a specific business workflow's execution order. The business logic had since changed, and the code had been updated accordingly, but the comment hadn't been synced. Claude 4 Opus, while working on related code, identified the discrepancy between the comment's description and the actual code logic, and proactively corrected the comment.
This isn't simple text matching. It requires understanding what the code does, what the comment claims, where the contradiction lies, and what the correct version should be. This demonstrated deep comprehension of business context.
From this point, the working model transformed fundamentally. No more pre-setting roles or describing specific scenarios — the agent could extract that information from the codebase itself. The workflow became: write project rules and business context into agent.md, then feed requirements directly — no decomposition, no translation into technical language needed. The agent could even run its own test pass after completing the implementation.
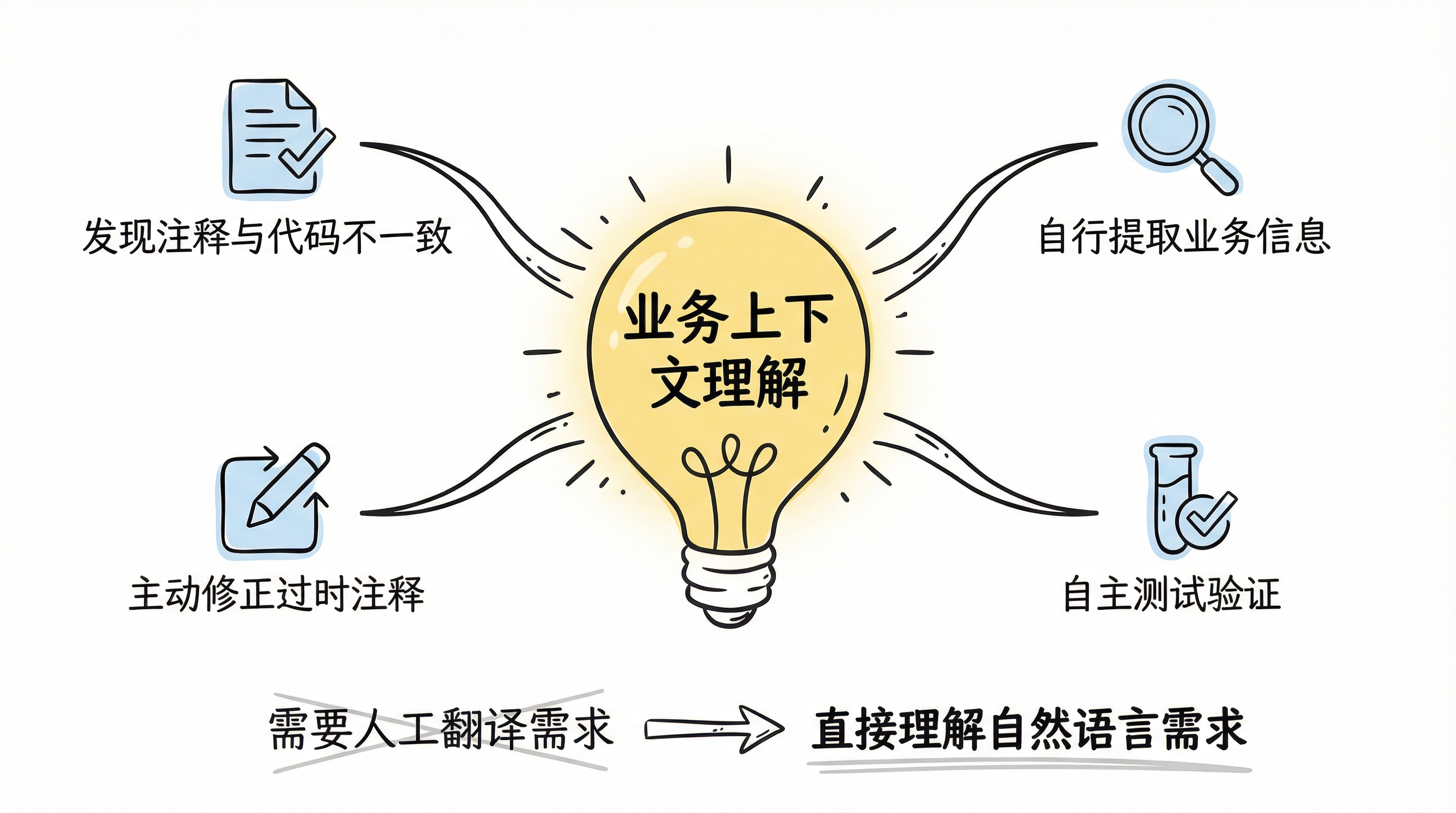
Trust inflection point: AI's leap in understanding business context
Phase Four: From Programming to Orchestration
Once agent intelligence crossed the trust threshold, the focus of work naturally shifted. The question was no longer "how to write code" but "how to make agents work more effectively."
This phase introduced OpenSpec — a spec-driven development framework. The problem with pure vibe coding is that the process becomes opaque: agents lose task context across multiple conversation turns, and there's no way to trace why a particular decision was made. OpenSpec structures requirements into four layers — proposal, specs, design, and tasks — making the entire development process auditable and traceable. The core problem it solves isn't whether AI can write code, but whether the code AI writes follows the agreed-upon specifications.
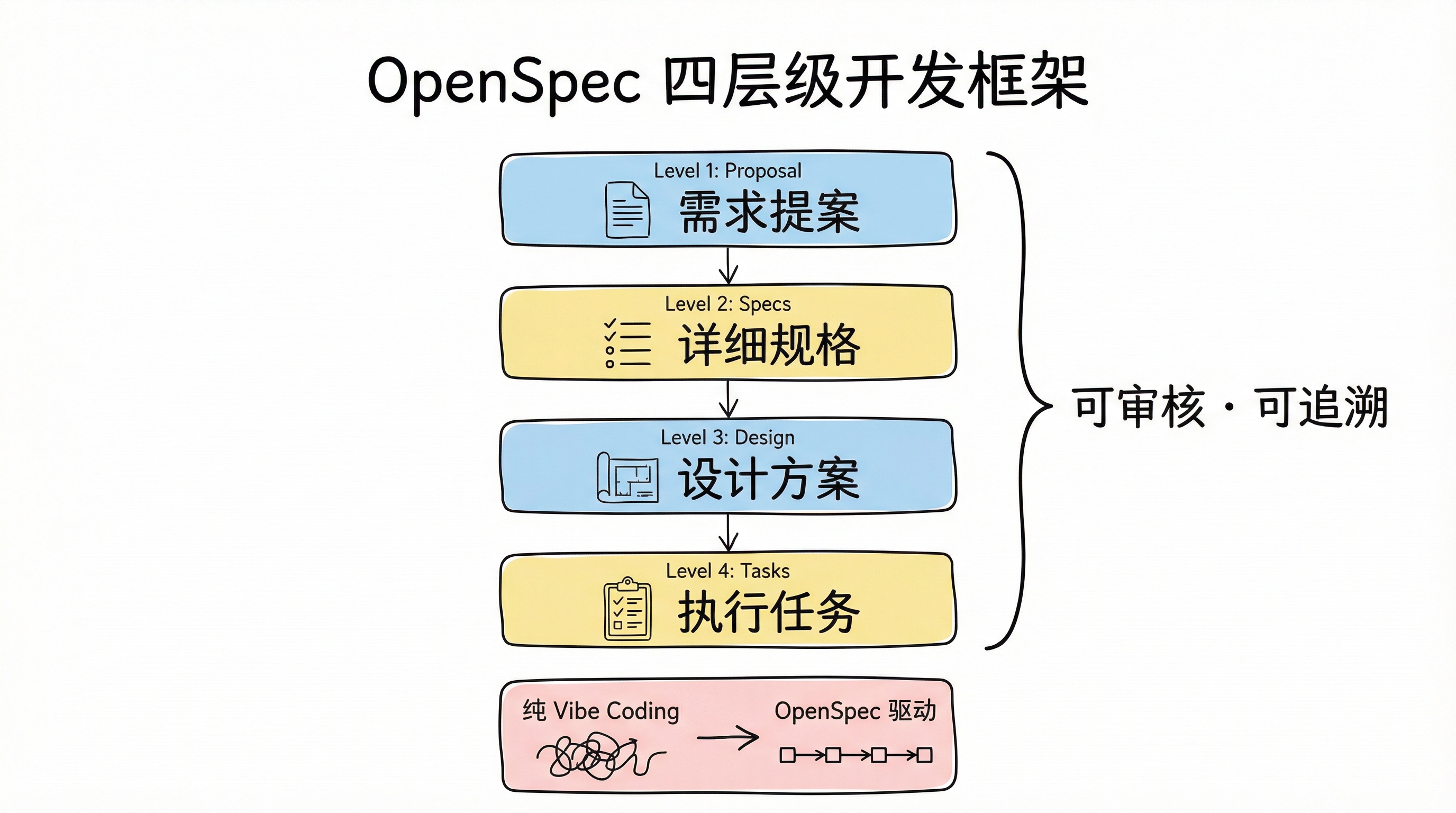
OpenSpec four-layer development framework
Significant time also went into designing Skills — domain knowledge documents written specifically for agents. Not generic coding standards, but deep guides for specific business repositories. For example, a project Skill might explicitly state: "Do not use approach X for this feature because it causes problem Y." These represent hard-won engineering experience; once codified as Skills, agents avoid repeating the same mistakes.
Further exploration included workflow and multi-agent patterns — having multiple agents process different tasks in parallel, or having agents coordinate their own division of labor. As agent intelligence continued improving, the points requiring human intervention steadily decreased.
An interesting reverse effect also emerged: to help AI perform better, the codebase itself was proactively improved. Three types of changes were typical. First, replacing niche third-party libraries with mainstream community alternatives — AI performs better with popular libraries due to richer training data, and community conventions tend to be more reasonable anyway. Second, removing over-engineering and unnecessary abstraction layers — patterns that "only the original author could decipher" were pure noise for AI. Third, converting non-standard implementations to community conventions — replacing verbose custom solutions with standard library equivalents, reducing the token overhead from idiosyncratic patterns.
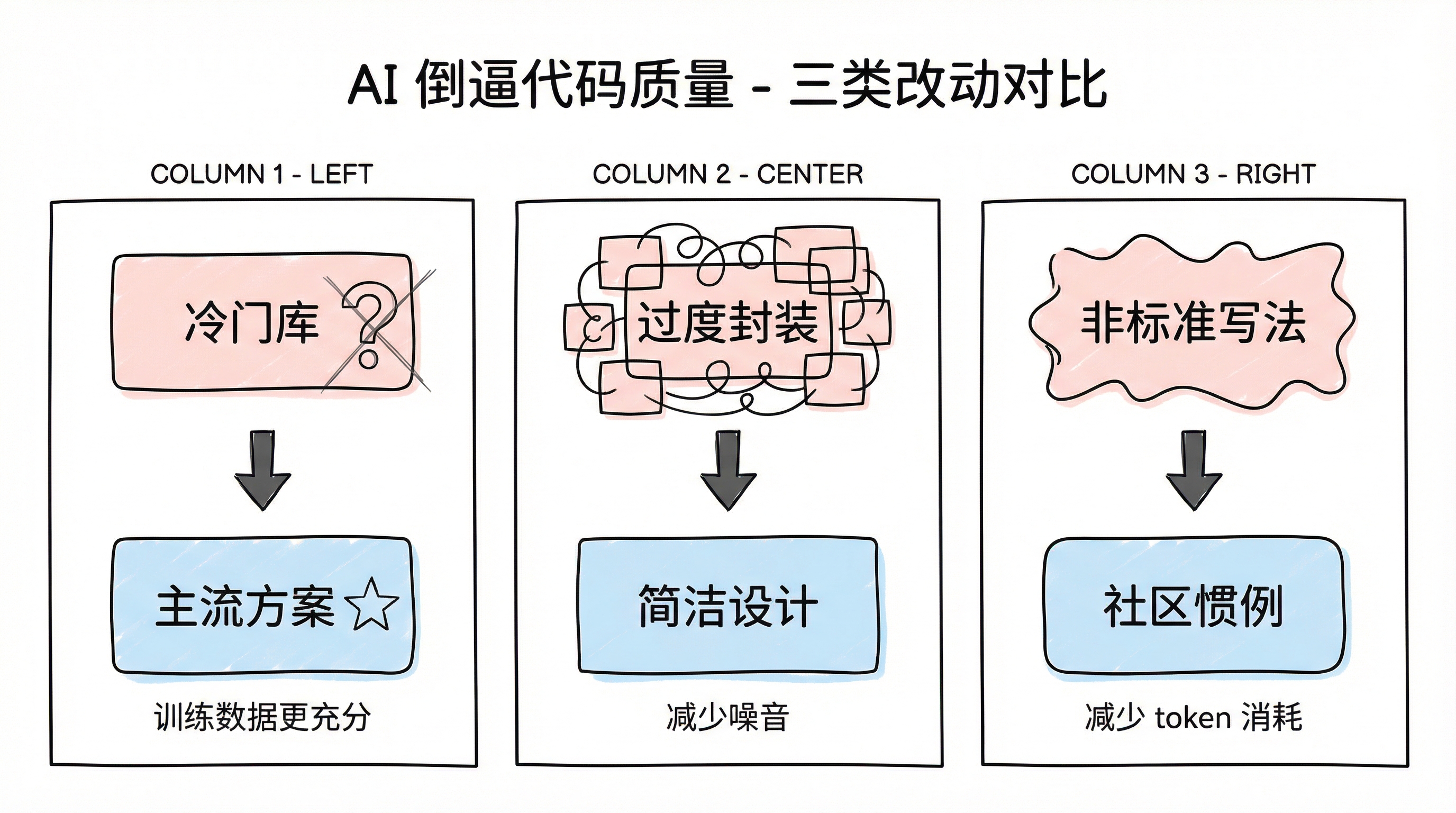
AI driving code quality: three types of improvements
In essence, AI forced a reassessment of code quality. Code that was "barely passable for humans but completely unfriendly to AI" became, in the context of AI-powered development, technical debt.
Boundaries and Trade-offs
To be candid, vibe coding has clear capability limits today.
The most telling scenario is complex UI interaction. During the development of a SQL-like query builder — with nested input fields, dropdown menu occlusion, and conditional dynamic rendering — the agent's performance was notably insufficient. The overall flow worked, but detail-level problems were persistent: element occlusion blocking user actions, input fields failing to respond to focus events correctly.
The root cause is the absence of a runtime connection. The agent can reason about code logic but cannot "see" the actual rendered interface. While solutions like agent browsers and Chrome DevTools MCP have emerged, the connection overhead and response latency aren't yet practical. This means any scenario involving complex visual interaction still requires human debugging and verification.
This isn't a permanent limitation — runtime connectivity will eventually be solved — but today, it defines the practical boundary of vibe coding.
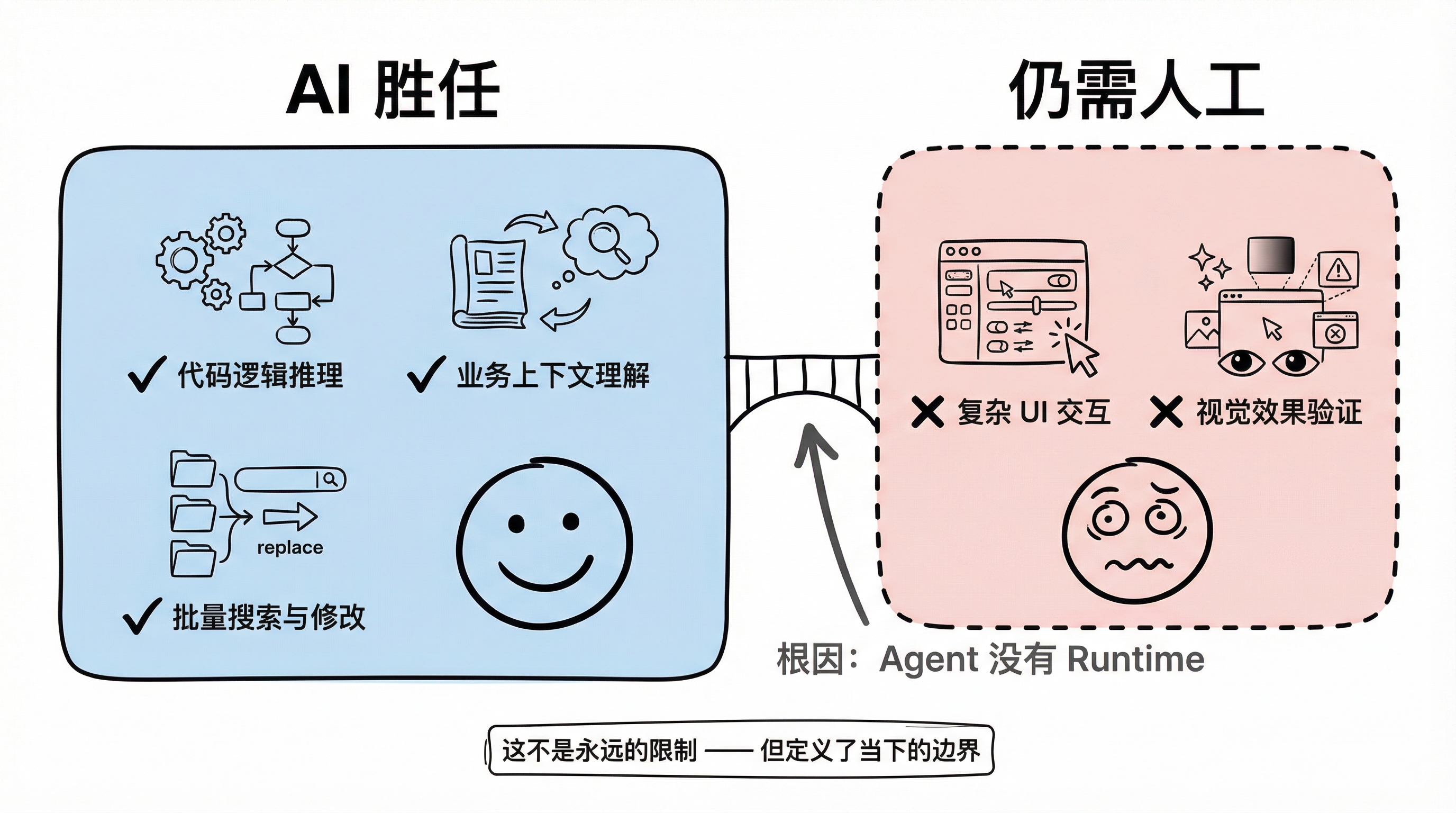
Vibe Coding capability boundary: AI-capable vs still-needs-human zones
Three Increasingly Clear Convictions
After months of production use, three convictions have solidified.
On process control: manage collaboration, not execution. As agent capabilities improve, the value of monitoring what each agent is doing diminishes rapidly. What matters is how agents collaborate — which principles are inviolable, which checkpoints require human confirmation. This mirrors the evolution of engineering management: from reviewing every line of code to defining architectural constraints and reviewing critical design decisions. The competitive advantage of future engineers won't be coding speed, but the ability to orchestrate agent workflows.
On Skill design: specialization beats generalization. The more specific and detailed a Skill, the narrower its scope — but the better it performs within that scope. A Skill written specifically for a project can bring onboarding cost to near zero and make agent performance exceptional. But attempting to make a Skill increasingly general and comprehensive makes it mediocre. This mirrors the engineer capability model exactly: a generalist who knows a bit of everything struggles to achieve mastery, while a specialist with deep domain experience achieves outsized efficiency.
On the migration of programming paradigms: AI-friendliness will become the new selection criterion. OpenSpec's natural language-driven coding already demonstrates this trajectory. All frameworks, languages, and tools will eventually be categorized into two groups: AI-friendly and AI-unfriendly. Niche libraries, over-engineered architectures, non-standard patterns — anything that "only humans with special training can understand" will be gradually eliminated due to efficiency disadvantages. Not because they're inherently bad, but because efficiency gains don't reverse. When AI can deliver 95-point results with mainstream approaches, no one will accept a 60-point ceiling from a niche alternative just for the sake of preference.
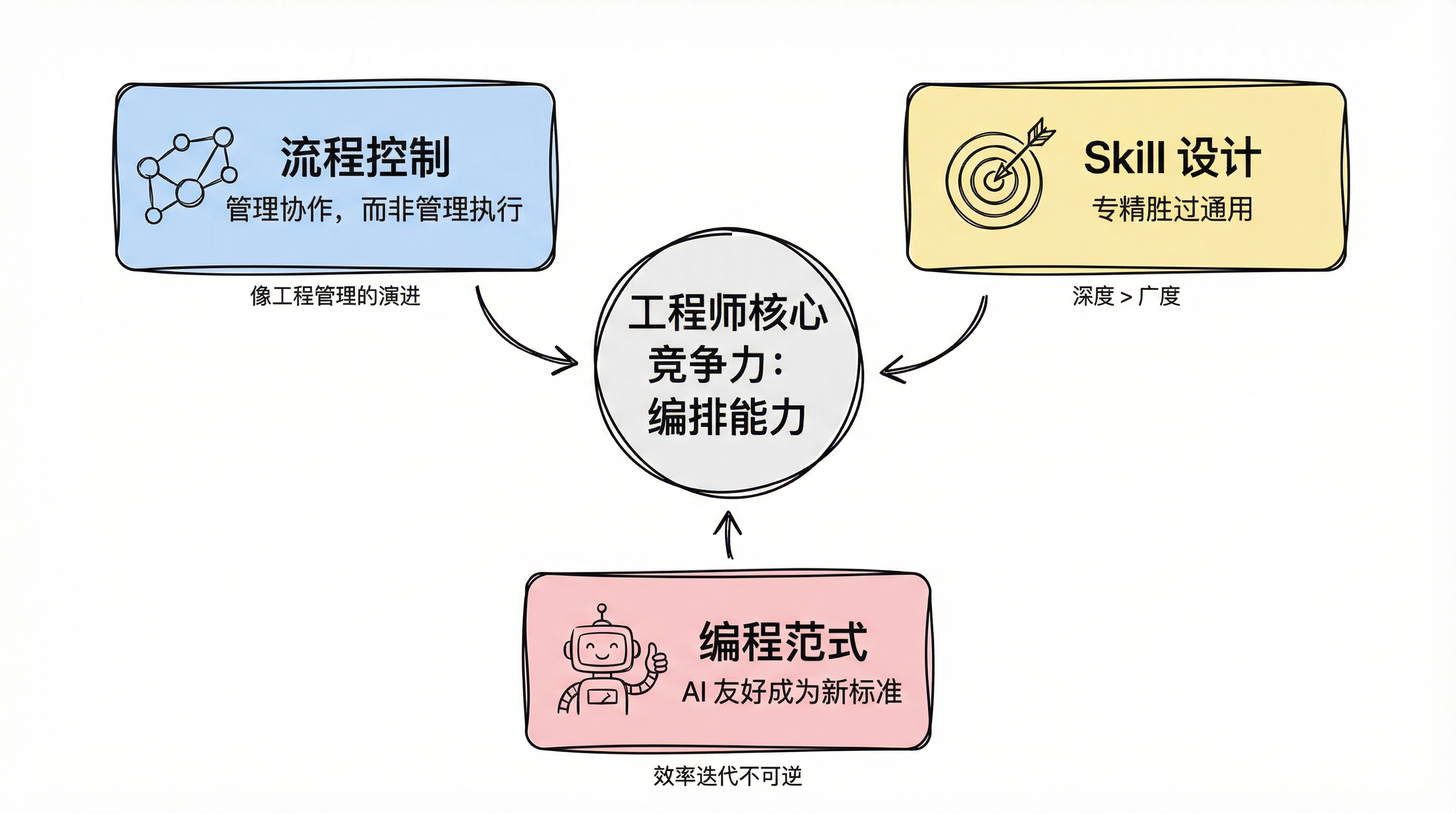
Three core convictions converging on the engineer's new competitive advantage
Not a Conclusion, But a Coordinate
The transition from writing code to writing rules, from managing implementation details to designing frameworks, happened faster than anticipated over the course of several months. But it's not the endpoint. Agent-runtime connectivity is still in its infancy. Multi-agent coordination efficiency has substantial room for improvement. Skill design best practices are still being discovered.
The only certainty is the direction: an engineer's value is migrating from "implementation capability" to "orchestration capability." Writing code won't disappear, but its share of an engineer's workload will keep declining. What's replacing it is deep business understanding, agent workflow design, and the ability to convert tacit knowledge into executable Skills.
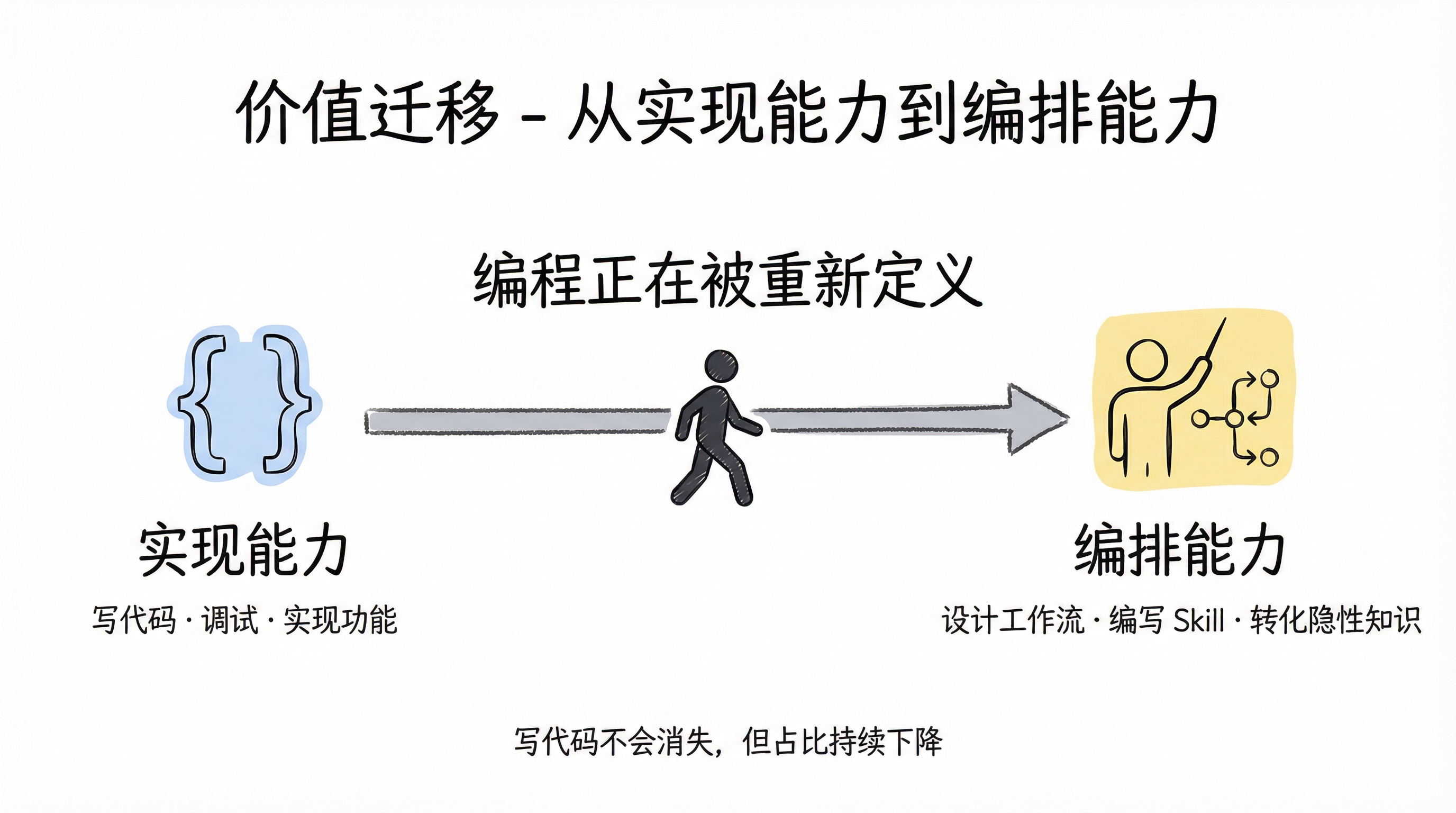
Value migration: from implementation capability to orchestration capability
This isn't a story about whether AI will replace programmers. It's a story about the act of programming itself being redefined.