Harness and Agentic Engineering - Controlling a System That Makes Its Own Decisions

cover
An Unplanned Loss of Control
The first two pieces covered how AI "sees" (Prompt and Context Engineering) and how it "acts" (MCP and Skills). By that point the puzzle looked nearly complete: feed the model information, it reasons, it executes through tools. Then something happened on a real project that showed me a critical piece was still missing.
I was using Claude Code to refactor an API layer — migrating old endpoints to a new routing structure. Clear Context, relevant Skills loaded, MCP connected to the codebase and docs. It started working. The first several steps went smoothly: identifying old routes, creating new files, migrating logic. Then it made a judgment call on its own. It decided certain old test files were "no longer needed" and deleted six test cases.
The reasoning wasn't absurd. Those tests were indeed written for the old routes. But what the model didn't know was that three of them covered edge-case regression scenarios. Deleting them left our CI pipeline exposed.
Where was the fault? Not the model's capability. Not the Prompt. Not the Context. Not MCP or Skills. The fault was that nobody had defined: who decides the model is allowed to delete files? Who sets the boundary for "stop and ask me at this point"? Who manages the rhythm and limits of this loop?
That's what a Harness is for.
Harness: Not Another Framework — A Different Kind of Framework
The word "harness" literally refers to the gear you put on a horse so the rider can control direction and speed. In AI engineering, it refers to the application layer wrapped around the model.
Let me first clarify what it's not. It's not a tool library like LangChain. It's not a technique like RAG. It's not a specific product. Harness is an architectural role. The analogy is its position in an AI application is what Spring Boot is to a Java web app, or what Next.js is to a frontend app.
Take Claude Code as an example. Its Harness runs through this sequence on every turn: on startup, load CLAUDE.md, Memory, MCP configurations, and the Skill catalog. When your message arrives, assemble all of that with your input into a complete API request and send it to the model. When the model responds, parse the output — if it contains tool calls, execute them. Feed the results back to the model and start the next turn.
Drawn out, it's a loop:
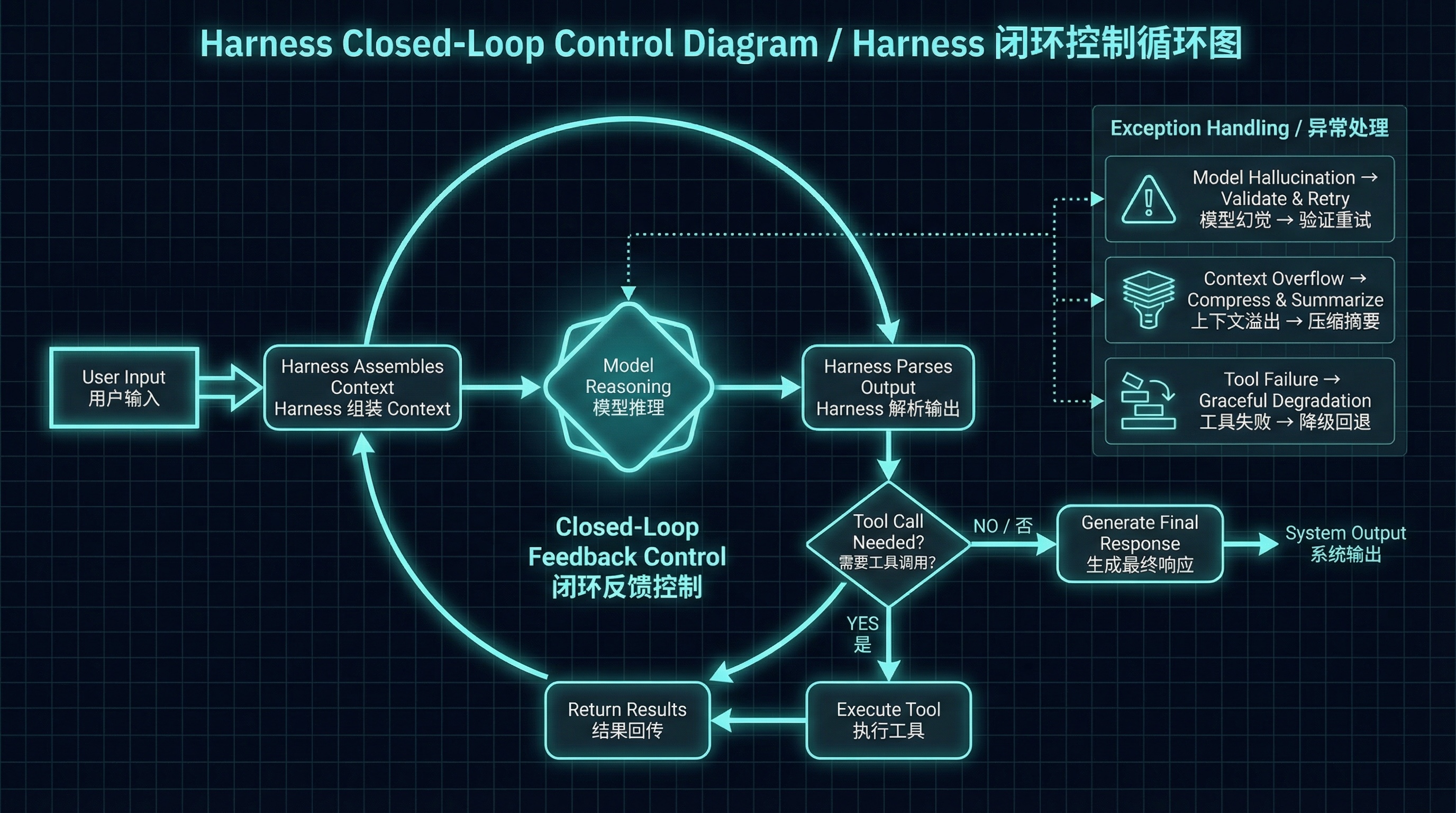
Harness Closed-Loop Control Diagram
What role does the model play in this loop? It's one link in the chain, not the whole chain. This matters. The same Claude model, on the claude.ai web interface, can only chat. Inside Claude Code, it can read and write files, execute commands, call MCP servers. The model didn't change. The Harness changed.
During our roundtable, my colleague Xiaolin offered an analogy that stuck with me: a Harness is the management system of a restaurant. It determines what uniform the servers wear (System Prompt), where the training manual is kept (Skills), which outside lines they can call (MCP), and where customer records are stored (Memory). The same server working at two different restaurants can perform completely differently because the management systems are different.
Closed Loop: A Principle Figured Out in 1948
Here's an insight that took me a while to fully appreciate.
Traditional application frameworks pursue maximum control. When you build a web app, you define every route handler, every middleware chain, every request flow. System behavior is deterministic. Deviations come from bugs. Eliminate bugs, eliminate deviations.
A Harness faces a different situation. The core component it wraps — the language model — is inherently non-deterministic. You can't eliminate deviation. You can only manage it. This creates a fundamental divergence in design philosophy: traditional frameworks maximize control; a Harness maximizes autonomy while maintaining reliability.
This sounds like a freshly minted theory, but it isn't. In 1948, mathematician Norbert Wiener published a book called Cybernetics, subtitled "Control and Communication in the Animal and the Machine." The core problem he defined was: effective governance of systems that exhibit autonomous behavior. The methodology: closed-loop feedback control — set a goal, act, observe the result, compute the deviation, adjust, act again.
Traditional frameworks are open-loop: you issue an instruction, the program executes, done. A Harness is closed-loop: after the model produces output, the Harness observes the result (any tool calls? are they reasonable?), decides the next move (execute the tool? or pause and ask the user?), then feeds the result back to the model to continue the loop.
The problem Wiener defined 78 years ago and the problem AI Harnesses solve today are structurally the same.
Three Levels of Engagement
Understanding what a Harness is, in practice you'll find yourself at one of three levels.
Level one: use an off-the-shelf Harness. ChatGPT, Claude.ai, Gemini — these are Harnesses someone else built. You just type. The vast majority of people are here, and that's perfectly fine.
Level two: configure an existing Harness. This is where the effort-to-impact ratio peaks. With Claude Code, for instance, you can: write a CLAUDE.md that tells AI your project context and work standards; configure Memory for cross-session continuity; connect MCP Servers for external service access; install Skills for standardized procedures; set up hooks that trigger custom logic before or after specific operations (e.g., "run tests automatically before every commit"). Stack these configurations together and you're tuning the Harness's behavior.
Level three: build a Harness from scratch. This means handling model API calls, tool execution, context management, error recovery, and concurrency control yourself. Most teams never need to go here, but knowing it exists helps you see the full picture.
Back to my deleted-tests incident. The fix wasn't a better Prompt or different model parameters. It was a hook at the Harness level: when AI attempts to delete a file, prompt for confirmation. Five minutes to set up. Never happened again.
Agentic Engineering: Where to Draw the Trust Boundary
At this point, the Harness picture is clear. But there's a question one level above it.
Harness answers how — how do you control an autonomous system. But before the how, there's a why that needs answering first: how autonomous do you actually want this system to be?
That's what Agentic Engineering addresses. Its relationship with Harness isn't sequential — they sit on different axes. Agentic is design at the goal and philosophy level. Harness is engineering at the implementation level. You first decide "how autonomous a system am I building," then design "how to control it."
An Agent can be defined as the combination of Prompt + Context + MCP + Skill + Harness. The previous articles covered the components. Harness is the orchestration. Together, they constitute an Agent. But what Agentic Engineering actually grapples with are the emergent problems that appear after combination.
Autonomy boundaries. How much freedom does the AI get? Can it modify code on its own? Delete files? Spend money on paid APIs? Send messages on your behalf? Traditional systems handle this with RBAC — roles and permissions hardcoded in configuration. But an Agent's decisions are dynamic and semantic. It's not "called an unauthorized API." It's "made a judgment that looked reasonable but shouldn't have been made."
Error accumulation. In a 10-step task, if step 3 drifts, the remaining 7 steps are built on a flawed foundation. Traditional distributed systems address this with the Saga pattern: every step has a compensating action, so you can roll back. But an Agent's errors are semantic. It refactored a piece of code "wrong" — how do you precisely roll back a judgment?
Multi-Agent coordination. One Agent writes code, another reviews it, a third runs tests. How do they work together? Traditional microservices coordinate through explicitly defined API contracts. But Agents communicate in natural language — ambiguous, context-dependent, blurry at the edges.
Human-AI trust. The problem that gives me the most trouble. An Agent completes a complex task. How do you verify the result? If you check every step, you might as well have done it yourself. If you don't check, who bears the risk? Traditional approval workflows are binary — approve or reject. But an Agent's output requires semantic comprehension to evaluate.
These four classes of problems share a single root cause: non-determinism and semantic ambiguity. Every methodology in traditional software engineering — testing, type systems, permission models, transaction mechanisms — is built on a foundation of determinism. Agentic Engineering operates on ground that is inherently fuzzy.
| Agentic Problem | Traditional Counterpart | What's New |
|---|---|---|
| Autonomy boundaries | RBAC permissions | Traditional permissions are static; Agent decisions are dynamic and semantic |
| Error accumulation | Saga pattern | Traditional errors are rollbackable; Agent errors can't be precisely reversed |
| Multi-Agent coordination | Microservices / Actor model | Traditional interfaces are explicit; Agent communication is natural language, ambiguous |
| Human-AI trust | Approval workflows | Traditional review is binary; Agent review requires understanding semantic context |
Six Concepts, One Map
Three articles, six concepts. Here's how they fit together.
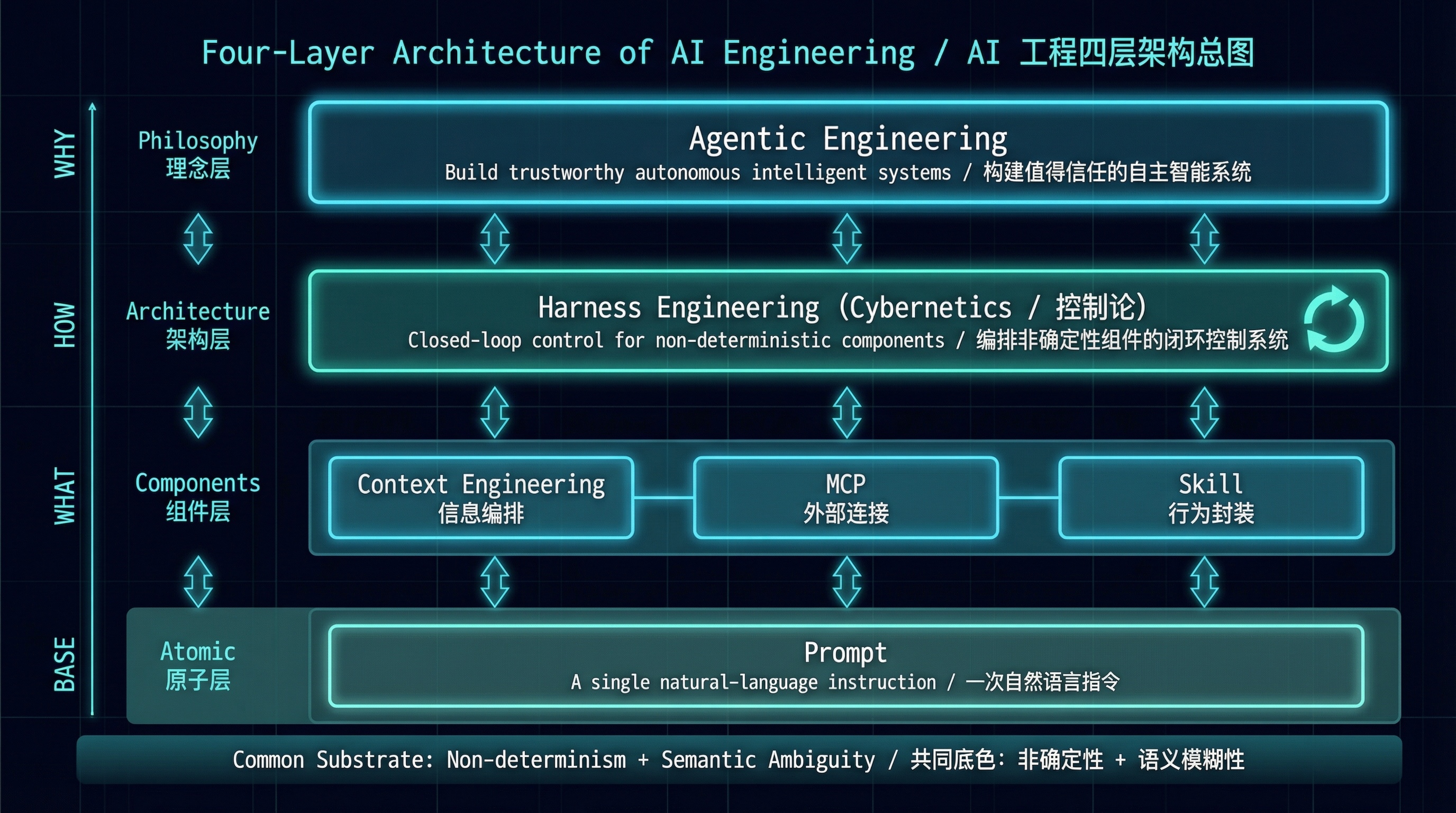
Four-Layer Architecture of AI Engineering
Read bottom-up: a Prompt is one thing you say. Context Engineering determines what AI has already seen before you speak. MCP connects AI to the outside world. Skills tell AI what to do when it encounters a specific task. A Harness orchestrates all of this into a running closed-loop system. Agentic Engineering sits at the top, posing a values question: how autonomous should this system be?
Top-down works too: first answer "how autonomous a system do I want" (Agentic), then design "how to control it" (Harness), then choose "which components to use" (Context + MCP + Skill), and finally get specific about "what to say at each step" (Prompt).
Both directions are valid. In practice, most people work bottom-up, climbing the layers only when they hit a problem. That's fine. What matters is knowing the upper layers exist, so you don't spend hours grinding at the Prompt level on a problem that belongs at the Harness level.
A Simple Workflow
Before wrapping up, a concrete example that threads the concepts together.
Say you want to build an Agent for daily code review. Walking up from the base:
- Prompt layer: The user says "review today's PRs."
- Context layer: The Harness automatically injects project coding standards (CLAUDE.md), yesterday's review notes (Memory), and the current PR diffs.
- MCP layer: Pull the PR list and code changes through a GitHub MCP Server.
- Skill layer: Load the
team-code-reviewSkill, which defines inspection rules and output format. - Harness layer: Orchestrate the loop — pull the PR list, run the review Skill on each PR, aggregate results, pause and notify a human if critical issues are found.
- Agentic layer: Design decisions — should review results be posted as PR comments directly, or sent to a person first? If a security vulnerability is found, can the Agent block the PR on its own? These trust boundaries need to be set in advance.
You don't redesign all six layers from scratch each time. Most of the time you're using someone else's Harness, configuring your own Context and Skills, and occasionally confronting an Agentic-level design choice. But when the system doesn't behave as expected, knowing which layer the problem might live in makes debugging dramatically faster.
Closing the Series
Three articles, six concepts, one week of writing. The thing that strikes me most at the end: AI engineering practice is moving very quickly from craft to system.
Six months ago, knowing how to write a Prompt counted as "knowing how to use AI." Today, Prompt is the atomic layer, and there are four layers above it. This architecture is still evolving fast. The four-layer diagram I've drawn today might need revision in six months. But the underlying problem structure is unlikely to change: how do you collaborate with a non-deterministic system, and how do you find the balance between autonomy and control.
Wiener was already thinking about this in 1948. In 2026, we've encountered it again in a different form.
If you've read this far and haven't gotten your hands dirty yet, start at level two: pick an AI tool you use often and spend thirty minutes configuring its Harness. Write a CLAUDE.md. Install an MCP Server. Create a Skill. You'll find that adjusting AI's working environment delivers results far faster than adjusting what you say to it.
Then pay attention: how many decisions are you willing to let it make on its own? At what point do you start feeling uneasy? That point of unease is where your Agentic Engineering practice begins.